 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural network interpretability with layer-wise relevance propagation: novel techniques for neuron selection and visualization
Dec 07, 2024Interpreting complex neural networks is crucial for understanding their decision-making processes, particularly in applications where transparency and accountability are essential. This proposed method addresses this need by focusing on layer-wise Relevance Propagation (LRP), a technique used in explainable artificial intelligence (XAI) to attribute neural network outputs to input features through backpropagated relevance scores. Existing LRP methods often struggle with precision in evaluating individual neuron contributions. To overcome this limitation, we present a novel approach that improves the parsing of selected neurons during LRP backward propagation, using the Visual Geometry Group 16 (VGG16) architecture as a case study. Our method creates neural network graphs to highlight critical paths and visualizes these paths with heatmaps, optimizing neuron selection through accuracy metrics like Mean Squared Error (MSE) and Symmetric Mean Absolute Percentage Error (SMAPE). Additionally, we utilize a deconvolutional visualization technique to reconstruct feature maps, offering a comprehensive view of the network's inner workings. Extensive experiments demonstrate that our approach enhances interpretability and supports the development of more transparent artificial intelligence (AI) systems for computer vision applications. This advancement has the potential to improve the trustworthiness of AI models in real-world machine vision applications, thereby increasing their reliability and effectiveness.
A Tiered GAN Approach for Monet-Style Image Generation
Dec 07, 2024



Generative Adversarial Networks (GANs) have proven to be a powerful tool in generating artistic images, capable of mimicking the styles of renowned painters, such as Claude Monet. This paper introduces a tiered GAN model to progressively refine image quality through a multi-stage process, enhancing the generated images at each step. The model transforms random noise into detailed artistic representations, addressing common challenges such as instability in training, mode collapse, and output quality. This approach combines downsampling and convolutional techniques, enabling the generation of high-quality Monet-style artwork while optimizing computational efficiency. Experimental results demonstrate the architecture's ability to produce foundational artistic structures, though further refinements are necessary for achieving higher levels of realism and fidelity to Monet's style. Future work focuses on improving training methodologies and model complexity to bridge the gap between generated and true artistic images. Additionally, the limitations of traditional GANs in artistic generation are analyzed, and strategies to overcome these shortcomings are proposed.
From classical techniques to convolution-based models: A review of object detection algorithms
Dec 06, 2024



Object detection is a fundamental task in computer vision and image understanding, with the goal of identifying and localizing objects of interest within an image while assigning them corresponding class labels. Traditional methods, which relied on handcrafted features and shallow models, struggled with complex visual data and showed limited performance. These methods combined low-level features with contextual information and lacked the ability to capture high-level semantics. Deep learning, especially Convolutional Neural Networks (CNNs), addressed these limitations by automatically learning rich, hierarchical features directly from data. These features include both semantic and high-level representations essential for accurate object detection. This paper reviews object detection frameworks, starting with classical computer vision methods. We categorize object detection approaches into two groups: (1) classical computer vision techniques and (2) CNN-based detectors. We compare major CNN models, discussing their strengths and limitations. In conclusion, this review highlights the significant advancements in object detection through deep learning and identifies key areas for further research to improve performance.
Exploring AI Text Generation, Retrieval-Augmented Generation, and Detection Technologies: a Comprehensive Overview
Dec 05, 2024



The rapid development of Artificial Intelligence (AI) has led to the creation of powerful text generation models, such as large language models (LLMs), which are widely used for diverse applications. However, concerns surrounding AI-generated content, including issues of originality, bias, misinformation, and accountability, have become increasingly prominent. This paper offers a comprehensive overview of AI text generators (AITGs), focusing on their evolution, capabilities, and ethical implications. This paper also introduces Retrieval-Augmented Generation (RAG), a recent approach that improves the contextual relevance and accuracy of text generation by integrating dynamic information retrieval. RAG addresses key limitations of traditional models, including their reliance on static knowledge and potential inaccuracies in handling real-world data. Additionally, the paper reviews detection tools that help differentiate AI-generated text from human-written content and discusses the ethical challenges these technologies pose. The paper explores future directions for improving detection accuracy, supporting ethical AI development, and increasing accessibility. The paper contributes to a more responsible and reliable use of AI in content creation through these discussions.
Analyzing the Impact of AI Tools on Student Study Habits and Academic Performance
Dec 03, 2024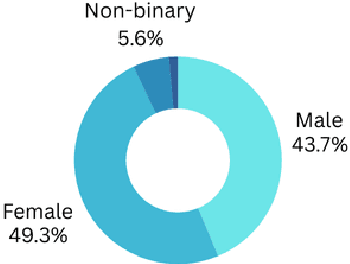
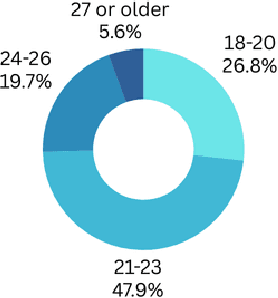
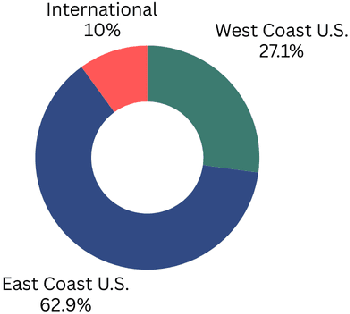
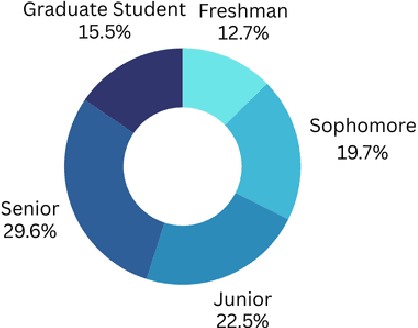
This study explores the effectiveness of AI tools in enhancing student learning, specifically in improving study habits, time management, and feedback mechanisms. The research focuses on how AI tools can support personalized learning, adaptive test adjustments, and provide real-time classroom analysis. Student feedback revealed strong support for these features, and the study found a significant reduction in study hours alongside an increase in GPA, suggesting positive academic outcomes. Despite these benefits, challenges such as over-reliance on AI and difficulties in integrating AI with traditional teaching methods were also identified, emphasizing the need for AI tools to complement conventional educational strategies rather than replace them. Data were collected through a survey with a Likert scale and follow-up interviews, providing both quantitative and qualitative insights. The analysis involved descriptive statistics to summarize demographic data, AI usage patterns, and perceived effectiveness, as well as inferential statistics (T-tests, ANOVA) to examine the impact of demographic factors on AI adoption. Regression analysis identified predictors of AI adoption, and qualitative responses were thematically analyzed to understand students' perspectives on the future of AI in education. This mixed-methods approach provided a comprehensive view of AI's role in education and highlighted the importance of privacy, transparency, and continuous refinement of AI features to maximize their educational benefits.
U-Net in Medical Image Segmentation: A Review of Its Applications Across Modalities
Dec 03, 2024



Medical imaging is essential in healthcare to provide key insights into patient anatomy and pathology, aiding in diagnosis and treatment. Non-invasive techniques such as X-ray, Magnetic Resonance Imaging (MRI), Computed Tomography (CT), and Ultrasound (US), capture detailed images of organs, tissues, and abnormalities. Effective analysis of these images requires precise segmentation to delineate regions of interest (ROI), such as organs or lesions. Traditional segmentation methods, relying on manual feature-extraction, are labor-intensive and vary across experts. Recent advancements in Artificial Intelligence (AI) and Deep Learning (DL), particularly convolutional models such as U-Net and its variants (U-Net++ and U-Net 3+), have transformed medical image segmentation (MIS) by automating the process and enhancing accuracy. These models enable efficient, precise pixel-wise classification across various imaging modalities, overcoming the limitations of manual segmentation. This review explores various medical imaging techniques, examines the U-Net architectures and their adaptations, and discusses their application across different modalities. It also identifies common challenges in MIS and proposes potential solutions.
Visualizing Routes with AI-Discovered Street-View Patterns
Mar 30, 2024



Street-level visual appearances play an important role in studying social systems, such as understanding the built environment, driving routes, and associated social and economic factors. It has not been integrated into a typical geographical visualization interface (e.g., map services) for planning driving routes. In this paper, we study this new visualization task with several new contributions. First, we experiment with a set of AI techniques and propose a solution of using semantic latent vectors for quantifying visual appearance features. Second, we calculate image similarities among a large set of street-view images and then discover spatial imagery patterns. Third, we integrate these discovered patterns into driving route planners with new visualization techniques. Finally, we present VivaRoutes, an interactive visualization prototype, to show how visualizations leveraged with these discovered patterns can help users effectively and interactively explore multiple routes. Furthermore, we conducted a user study to assess the usefulness and utility of VivaRoutes.