 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiomics in Medical Imaging: Methods, Applications, and Challenges
Jan 24, 2026Radiomics enables quantitative medical image analysis by converting imaging data into structured, high-dimensional feature representations for predictive modeling. Despite methodological developments and encouraging retrospective results, radiomics continue to face persistent challenges related to feature instability, limited reproducibility, validation bias, and restricted clinical translation. Existing reviews largely focus on application-specific outcomes or isolated pipeline components, with limited analysis of how interdependent design choices across acquisition, preprocessing, feature engineering, modeling, and evaluation collectively affect robustness and generalizability. This survey provides an end-to-end analysis of radiomics pipelines, examining how methodological decisions at each stage influence feature stability, model reliability, and translational validity. This paper reviews radiomic feature extraction, selection, and dimensionality reduction strategies; classical machine and deep learning-based modeling approaches; and ensemble and hybrid frameworks, with emphasis on validation protocols, data leakage prevention, and statistical reliability. Clinical applications are discussed with a focus on evaluation rigor rather than reported performance metrics. The survey identifies open challenges in standardization, domain shift, and clinical deployment, and outlines future directions such as hybrid radiomics-artificial intelligence models, multimodal fusion, federated learning, and standardized benchmarking.
Neural network interpretability with layer-wise relevance propagation: novel techniques for neuron selection and visualization
Dec 07, 2024Interpreting complex neural networks is crucial for understanding their decision-making processes, particularly in applications where transparency and accountability are essential. This proposed method addresses this need by focusing on layer-wise Relevance Propagation (LRP), a technique used in explainable artificial intelligence (XAI) to attribute neural network outputs to input features through backpropagated relevance scores. Existing LRP methods often struggle with precision in evaluating individual neuron contributions. To overcome this limitation, we present a novel approach that improves the parsing of selected neurons during LRP backward propagation, using the Visual Geometry Group 16 (VGG16) architecture as a case study. Our method creates neural network graphs to highlight critical paths and visualizes these paths with heatmaps, optimizing neuron selection through accuracy metrics like Mean Squared Error (MSE) and Symmetric Mean Absolute Percentage Error (SMAPE). Additionally, we utilize a deconvolutional visualization technique to reconstruct feature maps, offering a comprehensive view of the network's inner workings. Extensive experiments demonstrate that our approach enhances interpretability and supports the development of more transparent artificial intelligence (AI) systems for computer vision applications. This advancement has the potential to improve the trustworthiness of AI models in real-world machine vision applications, thereby increasing their reliability and effectiveness.
From classical techniques to convolution-based models: A review of object detection algorithms
Dec 06, 2024



Object detection is a fundamental task in computer vision and image understanding, with the goal of identifying and localizing objects of interest within an image while assigning them corresponding class labels. Traditional methods, which relied on handcrafted features and shallow models, struggled with complex visual data and showed limited performance. These methods combined low-level features with contextual information and lacked the ability to capture high-level semantics. Deep learning, especially Convolutional Neural Networks (CNNs), addressed these limitations by automatically learning rich, hierarchical features directly from data. These features include both semantic and high-level representations essential for accurate object detection. This paper reviews object detection frameworks, starting with classical computer vision methods. We categorize object detection approaches into two groups: (1) classical computer vision techniques and (2) CNN-based detectors. We compare major CNN models, discussing their strengths and limitations. In conclusion, this review highlights the significant advancements in object detection through deep learning and identifies key areas for further research to improve performance.
Exploring AI Text Generation, Retrieval-Augmented Generation, and Detection Technologies: a Comprehensive Overview
Dec 05, 2024



The rapid development of Artificial Intelligence (AI) has led to the creation of powerful text generation models, such as large language models (LLMs), which are widely used for diverse applications. However, concerns surrounding AI-generated content, including issues of originality, bias, misinformation, and accountability, have become increasingly prominent. This paper offers a comprehensive overview of AI text generators (AITGs), focusing on their evolution, capabilities, and ethical implications. This paper also introduces Retrieval-Augmented Generation (RAG), a recent approach that improves the contextual relevance and accuracy of text generation by integrating dynamic information retrieval. RAG addresses key limitations of traditional models, including their reliance on static knowledge and potential inaccuracies in handling real-world data. Additionally, the paper reviews detection tools that help differentiate AI-generated text from human-written content and discusses the ethical challenges these technologies pose. The paper explores future directions for improving detection accuracy, supporting ethical AI development, and increasing accessibility. The paper contributes to a more responsible and reliable use of AI in content creation through these discussions.
U-Net in Medical Image Segmentation: A Review of Its Applications Across Modalities
Dec 03, 2024



Medical imaging is essential in healthcare to provide key insights into patient anatomy and pathology, aiding in diagnosis and treatment. Non-invasive techniques such as X-ray, Magnetic Resonance Imaging (MRI), Computed Tomography (CT), and Ultrasound (US), capture detailed images of organs, tissues, and abnormalities. Effective analysis of these images requires precise segmentation to delineate regions of interest (ROI), such as organs or lesions. Traditional segmentation methods, relying on manual feature-extraction, are labor-intensive and vary across experts. Recent advancements in Artificial Intelligence (AI) and Deep Learning (DL), particularly convolutional models such as U-Net and its variants (U-Net++ and U-Net 3+), have transformed medical image segmentation (MIS) by automating the process and enhancing accuracy. These models enable efficient, precise pixel-wise classification across various imaging modalities, overcoming the limitations of manual segmentation. This review explores various medical imaging techniques, examines the U-Net architectures and their adaptations, and discusses their application across different modalities. It also identifies common challenges in MIS and proposes potential solutions.
Analyzing the Impact of AI Tools on Student Study Habits and Academic Performance
Dec 03, 2024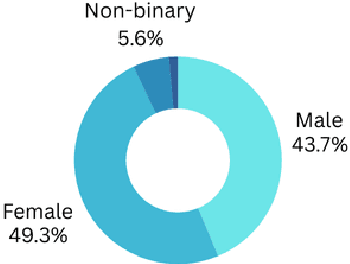
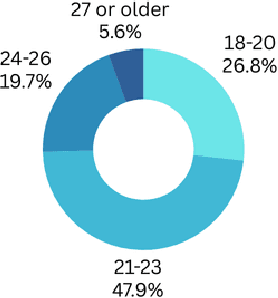
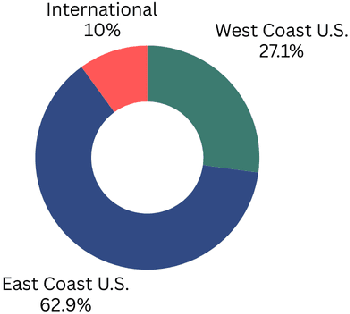
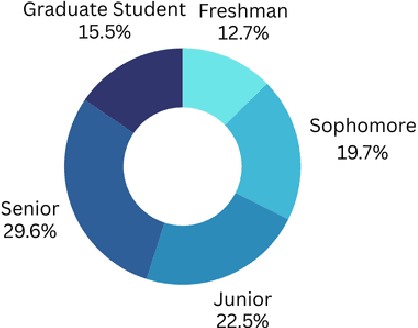
This study explores the effectiveness of AI tools in enhancing student learning, specifically in improving study habits, time management, and feedback mechanisms. The research focuses on how AI tools can support personalized learning, adaptive test adjustments, and provide real-time classroom analysis. Student feedback revealed strong support for these features, and the study found a significant reduction in study hours alongside an increase in GPA, suggesting positive academic outcomes. Despite these benefits, challenges such as over-reliance on AI and difficulties in integrating AI with traditional teaching methods were also identified, emphasizing the need for AI tools to complement conventional educational strategies rather than replace them. Data were collected through a survey with a Likert scale and follow-up interviews, providing both quantitative and qualitative insights. The analysis involved descriptive statistics to summarize demographic data, AI usage patterns, and perceived effectiveness, as well as inferential statistics (T-tests, ANOVA) to examine the impact of demographic factors on AI adoption. Regression analysis identified predictors of AI adoption, and qualitative responses were thematically analyzed to understand students' perspectives on the future of AI in education. This mixed-methods approach provided a comprehensive view of AI's role in education and highlighted the importance of privacy, transparency, and continuous refinement of AI features to maximize their educational benefits.
Multi-Layer Feature Fusion with Cross-Channel Attention-Based U-Net for Kidney Tumor Segmentation
Oct 20, 2024Renal tumors, especially renal cell carcinoma (RCC), show significant heterogeneity, posing challenges for diagnosis using radiology images such as MRI, echocardiograms, and CT scans. U-Net based deep learning techniques are emerging as a promising approach for automated medical image segmentation for minimally invasive diagnosis of renal tumors. However, current techniques need further improvements in accuracy to become clinically useful to radiologists. In this study, we present an improved U-Net based model for end-to-end automated semantic segmentation of CT scan images to identify renal tumors. The model uses residual connections across convolution layers, integrates a multi-layer feature fusion (MFF) and cross-channel attention (CCA) within encoder blocks, and incorporates skip connections augmented with additional information derived using MFF and CCA. We evaluated our model on the KiTS19 dataset, which contains data from 210 patients. For kidney segmentation, our model achieves a Dice Similarity Coefficient (DSC) of 0.97 and a Jaccard index (JI) of 0.95. For renal tumor segmentation, our model achieves a DSC of 0.96 and a JI of 0.91. Based on a comparison of available DSC scores, our model outperforms the current leading models.
* 8 pages