 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Query History: Nonstationary Classification via Learned Retrieval
Apr 08, 2026Nonstationarity is ubiquitous in practical classification settings, leading deployed models to perform poorly even when they generalize well to holdout sets available at training time. We address this by reframing nonstationary classification as time series prediction: rather than predicting from the current input alone, we condition the classifier on a sequence of historical labeled examples that extends beyond the training cutoff. To scale to large sequences, we introduce a learned discrete retrieval mechanism that samples relevant historical examples via input-dependent queries, trained end-to-end with the classifier using a score-based gradient estimator. This enables the full corpus of historical data to remain on an arbitrary filesystem during training and deployment. Experiments on synthetic benchmarks and Amazon Reviews '23 (electronics category) show improved robustness to distribution shift compared to standard classifiers, with VRAM scaling predictably as the length of the historical data sequence increases.
Robust Linear Classification from Limited Training Data
Oct 04, 2021
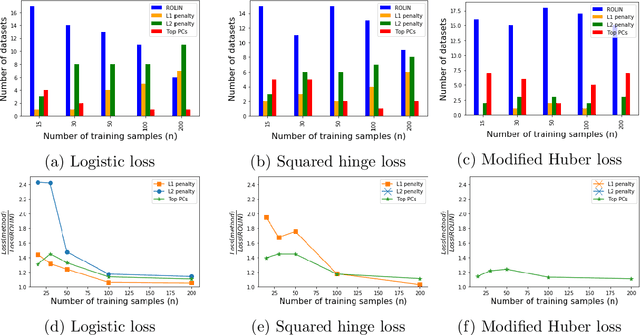
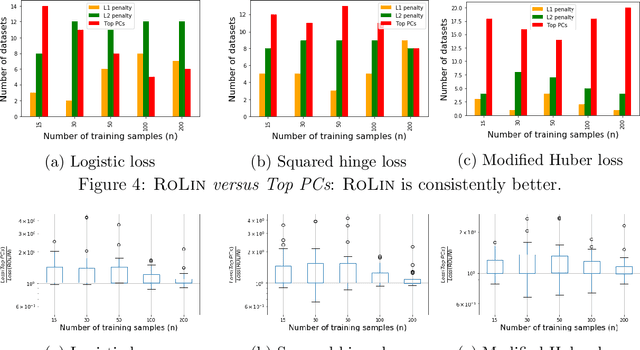
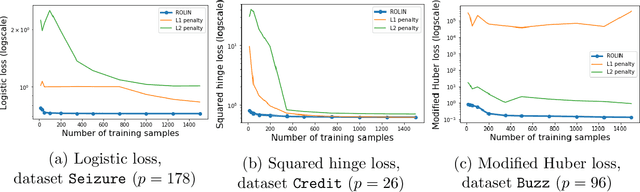
We consider the problem of linear classification under general loss functions in the limited-data setting. Overfitting is a common problem here. The standard approaches to prevent overfitting are dimensionality reduction and regularization. But dimensionality reduction loses information, while regularization requires the user to choose a norm, or a prior, or a distance metric. We propose an algorithm called RoLin that needs no user choice and applies to a large class of loss functions. RoLin combines reliable information from the top principal components with a robust optimization to extract any useful information from unreliable subspaces. It also includes a new robust cross-validation that is better than existing cross-validation methods in the limited-data setting. Experiments on $25$ real-world datasets and three standard loss functions show that RoLin broadly outperforms both dimensionality reduction and regularization. Dimensionality reduction has $14\%-40\%$ worse test loss on average as compared to RoLin. Against $L_1$ and $L_2$ regularization, RoLin can be up to 3x better for logistic loss and 12x better for squared hinge loss. The differences are greatest for small sample sizes, where RoLin achieves the best loss on 2x to 3x more datasets than any competing method. For some datasets, RoLin with $15$ training samples is better than the best norm-based regularization with $1500$ samples.
Overlapping Clustering Models, and One SVM to Bind Them All
Nov 05, 2018
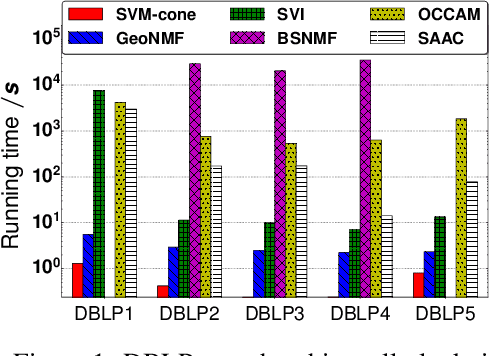
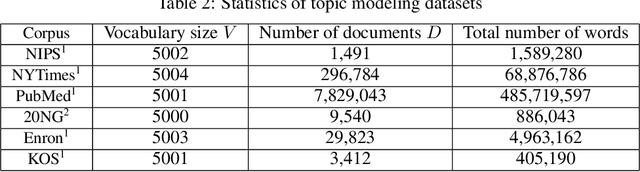
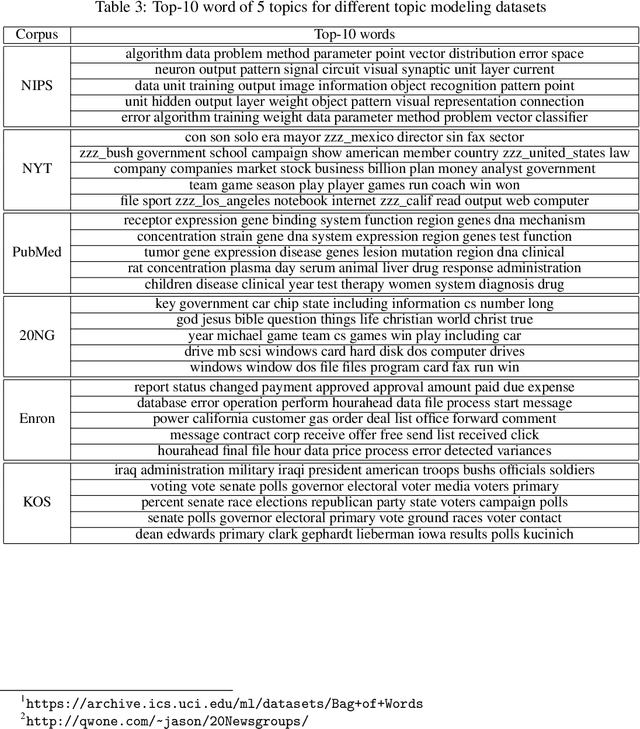
People belong to multiple communities, words belong to multiple topics, and books cover multiple genres; overlapping clusters are commonplace. Many existing overlapping clustering methods model each person (or word, or book) as a non-negative weighted combination of "exemplars" who belong solely to one community, with some small noise. Geometrically, each person is a point on a cone whose corners are these exemplars. This basic form encompasses the widely used Mixed Membership Stochastic Blockmodel of networks (Airoldi et al., 2008) and its degree-corrected variants (Jin et al., 2017), as well as topic models such as LDA (Blei et al., 2003). We show that a simple one-class SVM yields provably consistent parameter inference for all such models, and scales to large datasets. Experimental results on several simulated and real datasets show our algorithm (called SVM-cone) is both accurate and scalable.
On Mixed Memberships and Symmetric Nonnegative Matrix Factorizations
Jun 23, 2017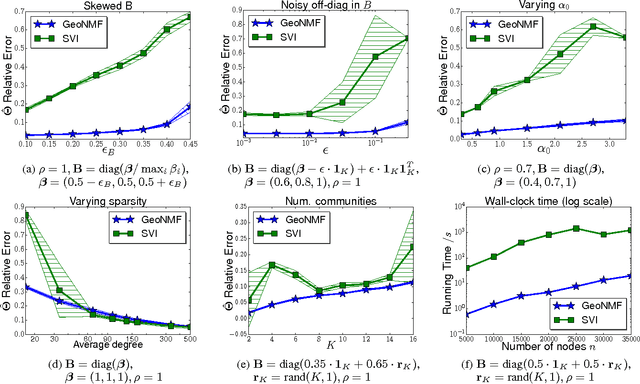
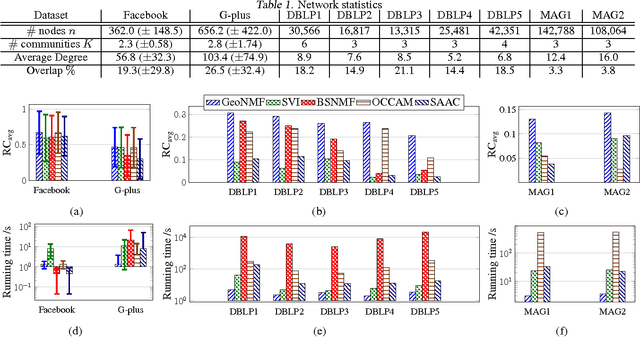
The problem of finding overlapping communities in networks has gained much attention recently. Optimization-based approaches use non-negative matrix factorization (NMF) or variants, but the global optimum cannot be provably attained in general. Model-based approaches, such as the popular mixed-membership stochastic blockmodel or MMSB (Airoldi et al., 2008), use parameters for each node to specify the overlapping communities, but standard inference techniques cannot guarantee consistency. We link the two approaches, by (a) establishing sufficient conditions for the symmetric NMF optimization to have a unique solution under MMSB, and (b) proposing a computationally efficient algorithm called GeoNMF that is provably optimal and hence consistent for a broad parameter regime. We demonstrate its accuracy on both simulated and real-world datasets.
Joint Inference of Multiple Label Types in Large Networks
Jan 30, 2014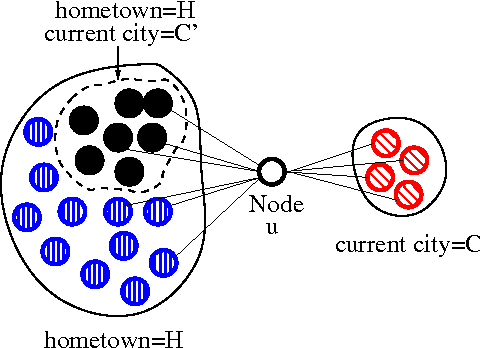
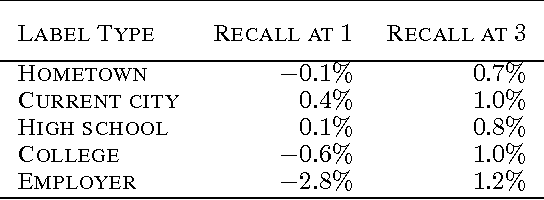
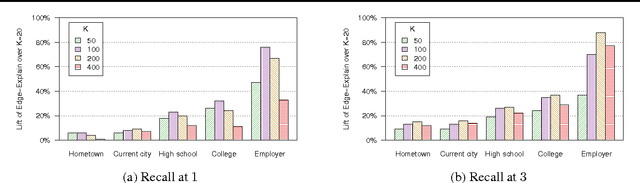
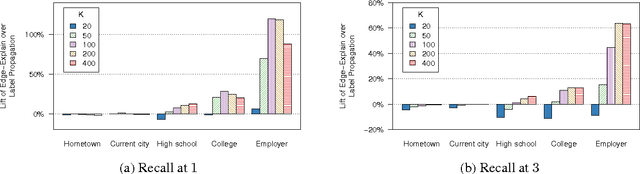
We tackle the problem of inferring node labels in a partially labeled graph where each node in the graph has multiple label types and each label type has a large number of possible labels. Our primary example, and the focus of this paper, is the joint inference of label types such as hometown, current city, and employers, for users connected by a social network. Standard label propagation fails to consider the properties of the label types and the interactions between them. Our proposed method, called EdgeExplain, explicitly models these, while still enabling scalable inference under a distributed message-passing architecture. On a billion-node subset of the Facebook social network, EdgeExplain significantly outperforms label propagation for several label types, with lifts of up to 120% for recall@1 and 60% for recall@3.
Nonparametric Link Prediction in Large Scale Dynamic Networks
Nov 16, 2013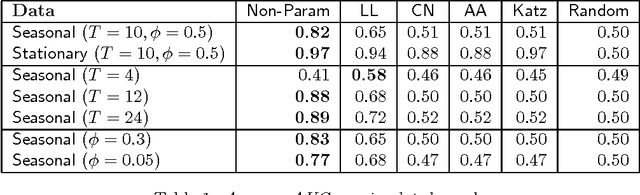

We propose a nonparametric approach to link prediction in large-scale dynamic networks. Our model uses graph-based features of pairs of nodes as well as those of their local neighborhoods to predict whether those nodes will be linked at each time step. The model allows for different types of evolution in different parts of the graph (e.g, growing or shrinking communities). We focus on large-scale graphs and present an implementation of our model that makes use of locality-sensitive hashing to allow it to be scaled to large problems. Experiments with simulated data as well as five real-world dynamic graphs show that we outperform the state of the art, especially when sharp fluctuations or nonlinearities are present. We also establish theoretical properties of our estimator, in particular consistency and weak convergence, the latter making use of an elaboration of Stein's method for dependency graphs.
Nonparametric Link Prediction in Dynamic Networks
Jun 27, 2012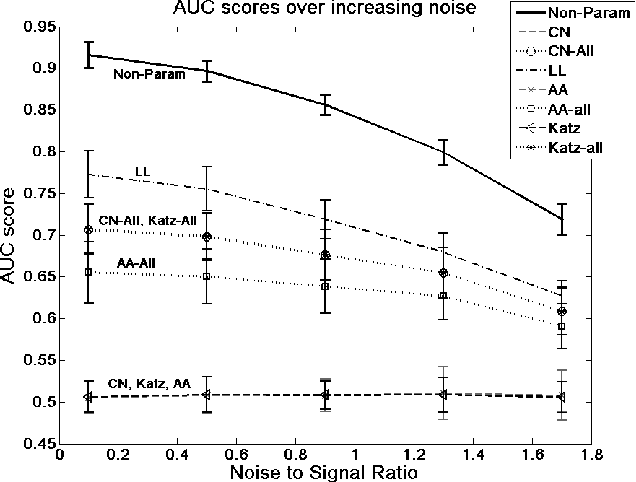
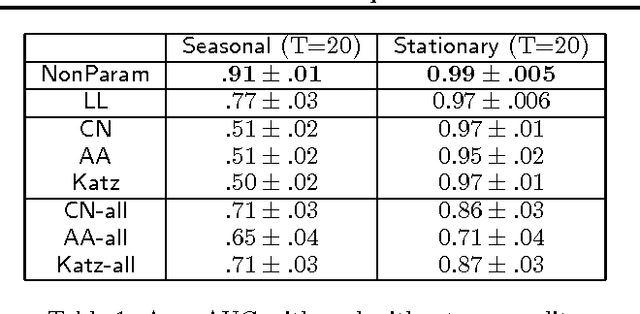
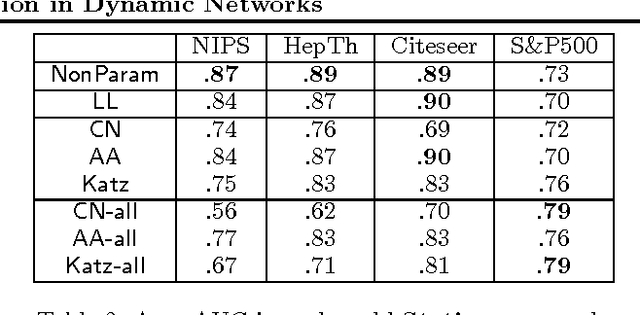
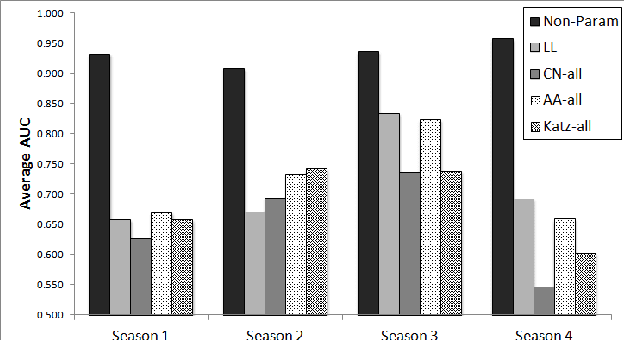
We propose a non-parametric link prediction algorithm for a sequence of graph snapshots over time. The model predicts links based on the features of its endpoints, as well as those of the local neighborhood around the endpoints. This allows for different types of neighborhoods in a graph, each with its own dynamics (e.g, growing or shrinking communities). We prove the consistency of our estimator, and give a fast implementation based on locality-sensitive hashing. Experiments with simulated as well as five real-world dynamic graphs show that we outperform the state of the art, especially when sharp fluctuations or non-linearities are present.
Kronecker Graphs: An Approach to Modeling Networks
Aug 21, 2009

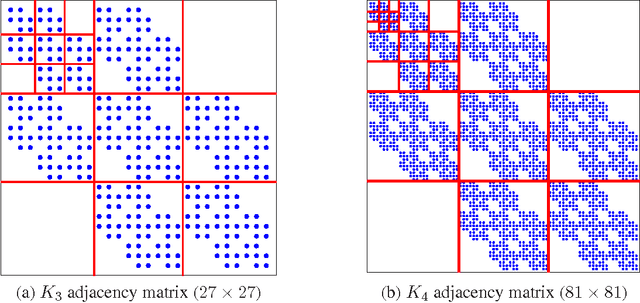
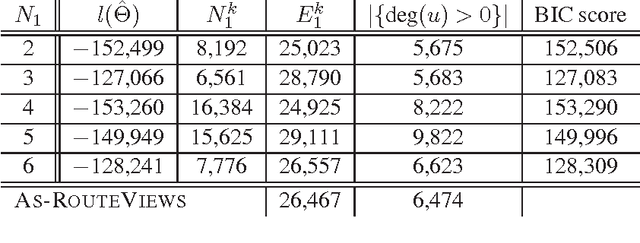
How can we model networks with a mathematically tractable model that allows for rigorous analysis of network properties? Networks exhibit a long list of surprising properties: heavy tails for the degree distribution; small diameters; and densification and shrinking diameters over time. Most present network models either fail to match several of the above properties, are complicated to analyze mathematically, or both. In this paper we propose a generative model for networks that is both mathematically tractable and can generate networks that have the above mentioned properties. Our main idea is to use the Kronecker product to generate graphs that we refer to as "Kronecker graphs". First, we prove that Kronecker graphs naturally obey common network properties. We also provide empirical evidence showing that Kronecker graphs can effectively model the structure of real networks. We then present KronFit, a fast and scalable algorithm for fitting the Kronecker graph generation model to large real networks. A naive approach to fitting would take super- exponential time. In contrast, KronFit takes linear time, by exploiting the structure of Kronecker matrix multiplication and by using statistical simulation techniques. Experiments on large real and synthetic networks show that KronFit finds accurate parameters that indeed very well mimic the properties of target networks. Once fitted, the model parameters can be used to gain insights about the network structure, and the resulting synthetic graphs can be used for null- models, anonymization, extrapolations, and graph summarization.