 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Linear Classification from Limited Training Data
Paper and Code
Oct 04, 2021
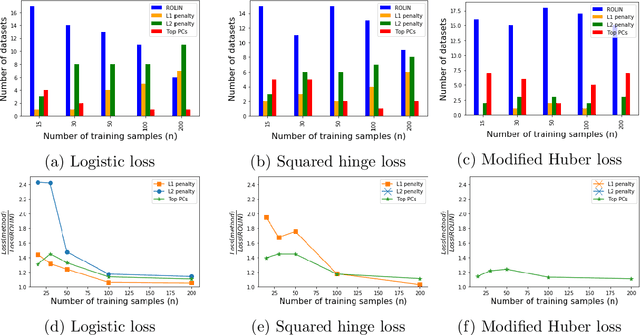
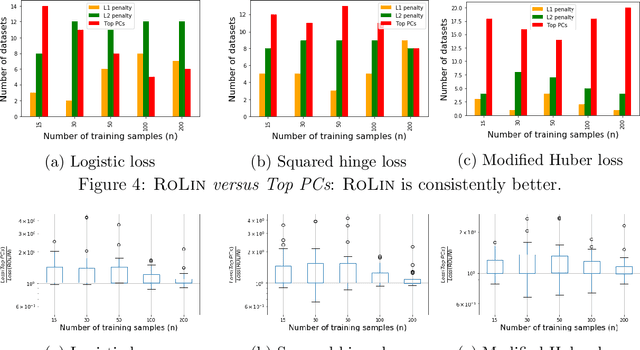
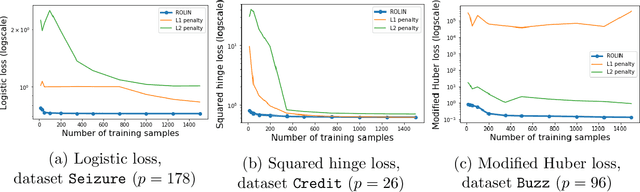
We consider the problem of linear classification under general loss functions in the limited-data setting. Overfitting is a common problem here. The standard approaches to prevent overfitting are dimensionality reduction and regularization. But dimensionality reduction loses information, while regularization requires the user to choose a norm, or a prior, or a distance metric. We propose an algorithm called RoLin that needs no user choice and applies to a large class of loss functions. RoLin combines reliable information from the top principal components with a robust optimization to extract any useful information from unreliable subspaces. It also includes a new robust cross-validation that is better than existing cross-validation methods in the limited-data setting. Experiments on $25$ real-world datasets and three standard loss functions show that RoLin broadly outperforms both dimensionality reduction and regularization. Dimensionality reduction has $14\%-40\%$ worse test loss on average as compared to RoLin. Against $L_1$ and $L_2$ regularization, RoLin can be up to 3x better for logistic loss and 12x better for squared hinge loss. The differences are greatest for small sample sizes, where RoLin achieves the best loss on 2x to 3x more datasets than any competing method. For some datasets, RoLin with $15$ training samples is better than the best norm-based regularization with $1500$ samples.