 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hardware Evaluation Framework for Large Language Model Inference
Dec 05, 2023The past year has witnessed the increasing popularity of Large Language Models (LLMs). Their unprecedented scale and associated high hardware cost have impeded their broader adoption, calling for efficient hardware designs. With the large hardware needed to simply run LLM inference, evaluating different hardware designs becomes a new bottleneck. This work introduces LLMCompass, a hardware evaluation framework for LLM inference workloads. LLMCompass is fast, accurate, versatile, and able to describe and evaluate different hardware designs. LLMCompass includes a mapper to automatically find performance-optimal mapping and scheduling. It also incorporates an area-based cost model to help architects reason about their design choices. Compared to real-world hardware, LLMCompass' estimated latency achieves an average 10.4% error rate across various operators with various input sizes and an average 4.1% error rate for LLM inference. With LLMCompass, simulating a 4-NVIDIA A100 GPU node running GPT-3 175B inference can be done within 16 minutes on commodity hardware, including 26,400 rounds of the mapper's parameter search. With the aid of LLMCompass, this work draws architectural implications and explores new cost-effective hardware designs. By reducing the compute capability or replacing High Bandwidth Memory (HBM) with traditional DRAM, these new designs can achieve as much as 3.41x improvement in performance/cost compared to an NVIDIA A100, making them promising choices for democratizing LLMs. LLMCompass is planned to be fully open-source.
Evolving Transferable Pruning Functions
Oct 21, 2021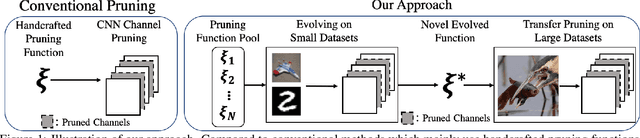
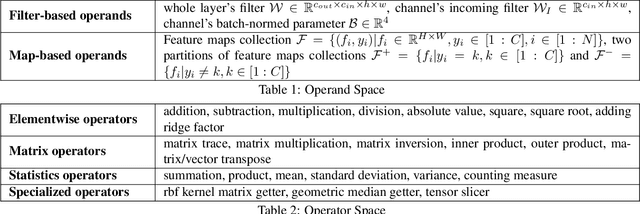
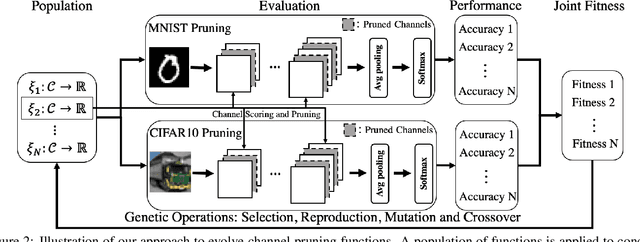
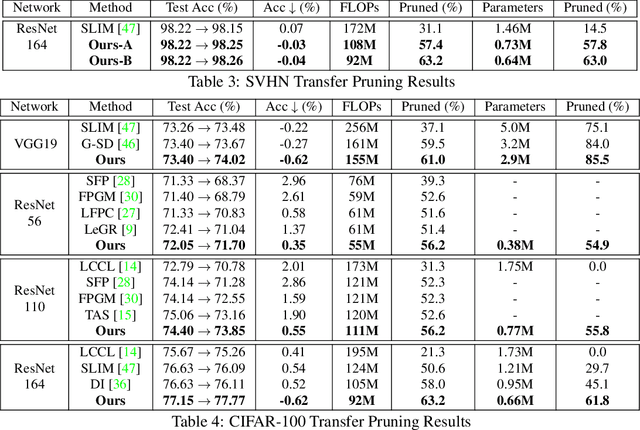
Channel pruning has made major headway in the design of efficient deep learning models. Conventional approaches adopt human-made pruning functions to score channels' importance for channel pruning, which requires domain knowledge and could be sub-optimal. In this work, we propose an end-to-end framework to automatically discover strong pruning metrics. Specifically, we craft a novel design space for expressing pruning functions and leverage an evolution strategy, genetic programming, to evolve high-quality and transferable pruning functions. Unlike prior methods, our approach can not only provide compact pruned networks for efficient inference, but also novel closed-form pruning metrics that are mathematically explainable and thus generalizable to different pruning tasks. The evolution is conducted on small datasets while the learned functions are transferable to larger datasets without any manual modification. Compared to direct evolution on a large dataset, our strategy shows better cost-effectiveness. When applied to more challenging datasets, different from those used in the evolution process, e.g., ILSVRC-2012, an evolved function achieves state-of-the-art pruning results.
Class-Discriminative CNN Compression
Oct 21, 2021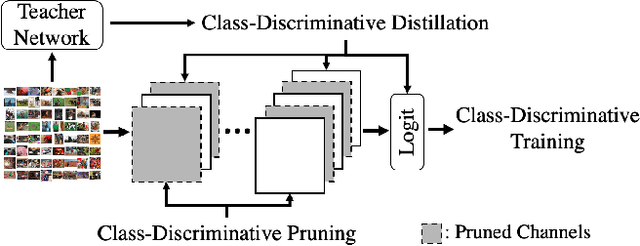
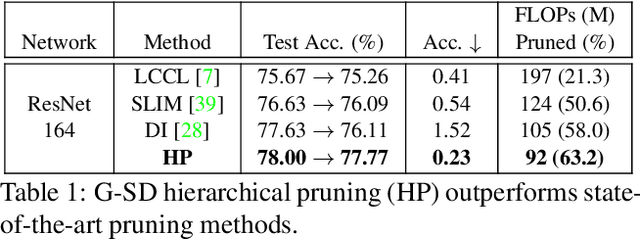
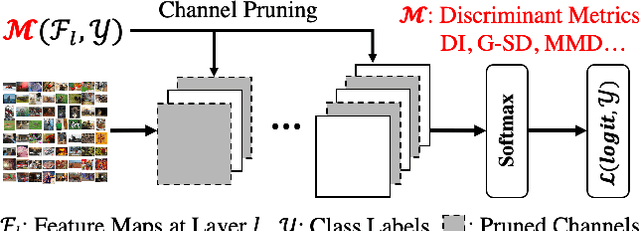
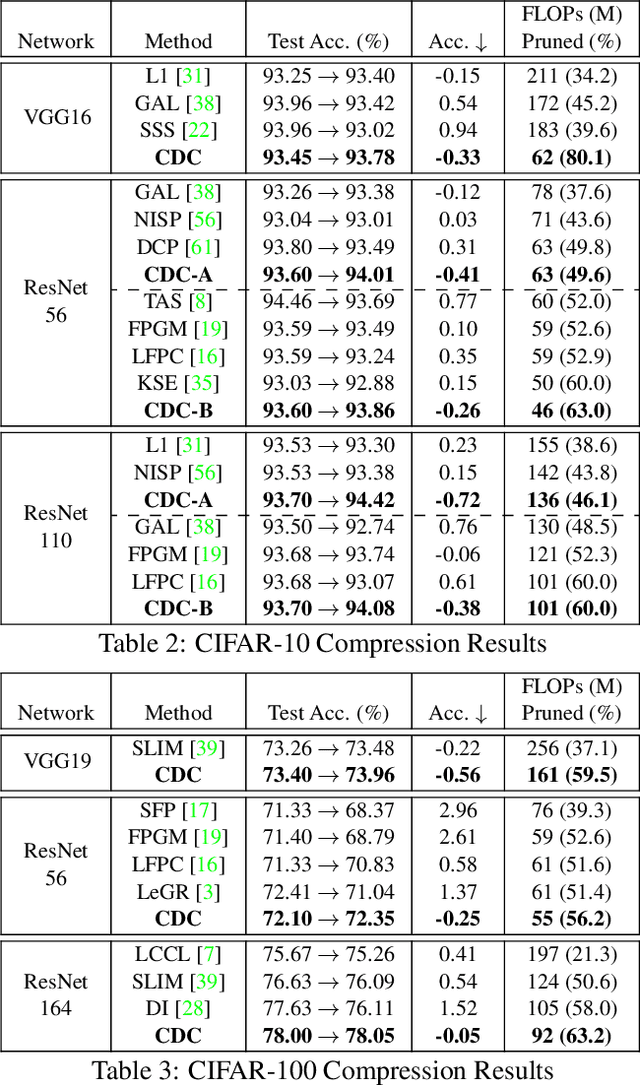
Compressing convolutional neural networks (CNNs) by pruning and distillation has received ever-increasing focus in the community. In particular, designing a class-discrimination based approach would be desired as it fits seamlessly with the CNNs training objective. In this paper, we propose class-discriminative compression (CDC), which injects class discrimination in both pruning and distillation to facilitate the CNNs training goal. We first study the effectiveness of a group of discriminant functions for channel pruning, where we include well-known single-variate binary-class statistics like Student's T-Test in our study via an intuitive generalization. We then propose a novel layer-adaptive hierarchical pruning approach, where we use a coarse class discrimination scheme for early layers and a fine one for later layers. This method naturally accords with the fact that CNNs process coarse semantics in the early layers and extract fine concepts at the later. Moreover, we leverage discriminant component analysis (DCA) to distill knowledge of intermediate representations in a subspace with rich discriminative information, which enhances hidden layers' linear separability and classification accuracy of the student. Combining pruning and distillation, CDC is evaluated on CIFAR and ILSVRC 2012, where we consistently outperform the state-of-the-art results.
Rethinking Class-Discrimination Based CNN Channel Pruning
Apr 29, 2020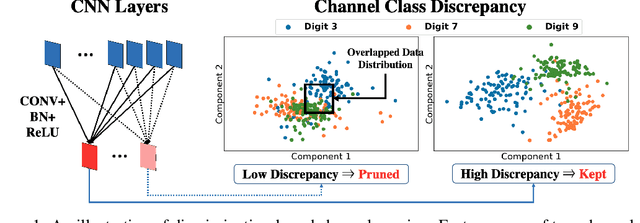
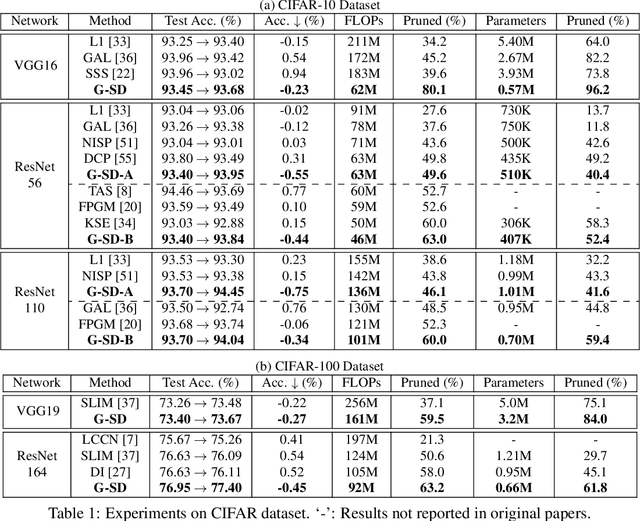
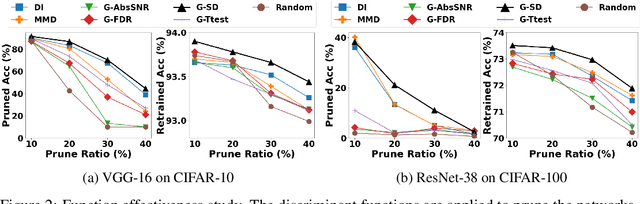
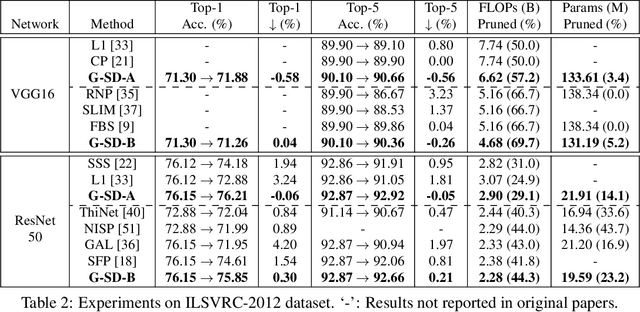
Channel pruning has received ever-increasing focus on network compression. In particular, class-discrimination based channel pruning has made major headway, as it fits seamlessly with the classification objective of CNNs and provides good explainability. Prior works singly propose and evaluate their discriminant functions, while further study on the effectiveness of the adopted metrics is absent. To this end, we initiate the first study on the effectiveness of a broad range of discriminant functions on channel pruning. Conventional single-variate binary-class statistics like Student's T-Test are also included in our study via an intuitive generalization. The winning metric of our study has a greater ability to select informative channels over other state-of-the-art methods, which is substantiated by our qualitative and quantitative analysis. Moreover, we develop a FLOP-normalized sensitivity analysis scheme to automate the structural pruning procedure. On CIFAR-10, CIFAR-100, and ILSVRC-2012 datasets, our pruned models achieve higher accuracy with less inference cost compared to state-of-the-art results. For example, on ILSVRC-2012, our 44.3% FLOPs-pruned ResNet-50 has only a 0.3% top-1 accuracy drop, which significantly outperforms the state of the art.