 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
The Necessity of AI Audit Standards Boards
Apr 11, 2024Auditing of AI systems is a promising way to understand and manage ethical problems and societal risks associated with contemporary AI systems, as well as some anticipated future risks. Efforts to develop standards for auditing Artificial Intelligence (AI) systems have therefore understandably gained momentum. However, we argue that creating auditing standards is not just insufficient, but actively harmful by proliferating unheeded and inconsistent standards, especially in light of the rapid evolution and ethical and safety challenges of AI. Instead, the paper proposes the establishment of an AI Audit Standards Board, responsible for developing and updating auditing methods and standards in line with the evolving nature of AI technologies. Such a body would ensure that auditing practices remain relevant, robust, and responsive to the rapid advancements in AI. The paper argues that such a governance structure would also be helpful for maintaining public trust in AI and for promoting a culture of safety and ethical responsibility within the AI industry. Throughout the paper, we draw parallels with other industries, including safety-critical industries like aviation and nuclear energy, as well as more prosaic ones such as financial accounting and pharmaceuticals. AI auditing should emulate those fields, and extend beyond technical assessments to include ethical considerations and stakeholder engagement, but we explain that this is not enough; emulating other fields' governance mechanisms for these processes, and for audit standards creation, is a necessity. We also emphasize the importance of auditing the entire development process of AI systems, not just the final products...
Modeling Transformative AI Risks (MTAIR) Project -- Summary Report
Jun 19, 2022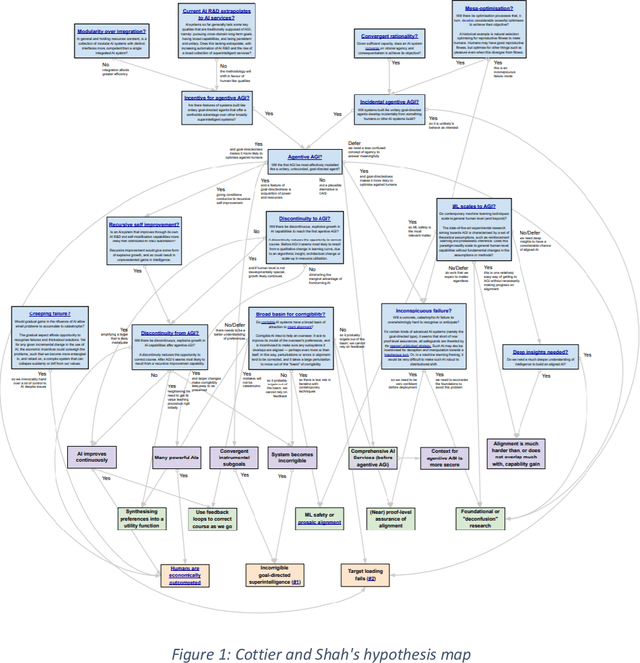
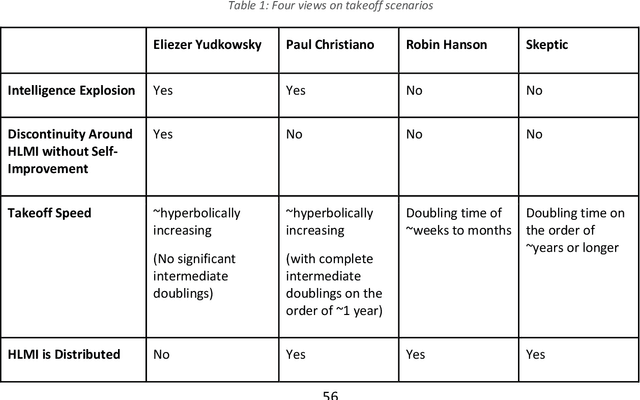
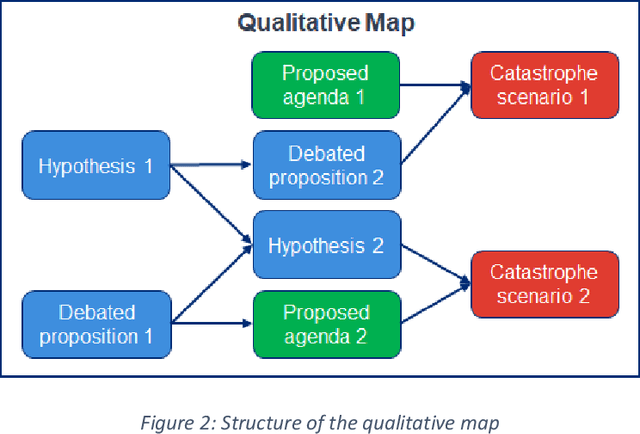
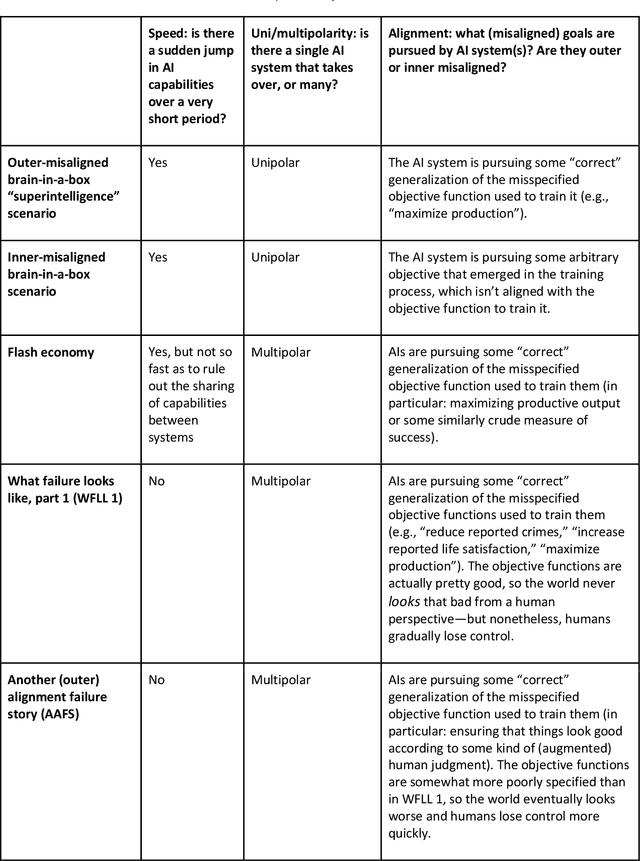
This report outlines work by the Modeling Transformative AI Risk (MTAIR) project, an attempt to map out the key hypotheses, uncertainties, and disagreements in debates about catastrophic risks from advanced AI, and the relationships between them. This builds on an earlier diagram by Ben Cottier and Rohin Shah which laid out some of the crucial disagreements ("cruxes") visually, with some explanation. Based on an extensive literature review and engagement with experts, the report explains a model of the issues involved, and the initial software-based implementation that can incorporate probability estimates or other quantitative factors to enable exploration, planning, and/or decision support. By gathering information from various debates and discussions into a single more coherent presentation, we hope to enable better discussions and debates about the issues involved. The model starts with a discussion of reasoning via analogies and general prior beliefs about artificial intelligence. Following this, it lays out a model of different paths and enabling technologies for high-level machine intelligence, and a model of how advances in the capabilities of these systems might proceed, including debates about self-improvement, discontinuous improvements, and the possibility of distributed, non-agentic high-level intelligence or slower improvements. The model also looks specifically at the question of learned optimization, and whether machine learning systems will create mesa-optimizers. The impact of different safety research on the previous sets of questions is then examined, to understand whether and how research could be useful in enabling safer systems. Finally, we discuss a model of different failure modes and loss of control or takeover scenarios.
Arguments about Highly Reliable Agent Designs as a Useful Path to Artificial Intelligence Safety
Jan 09, 2022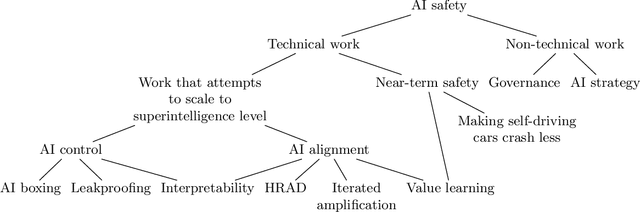
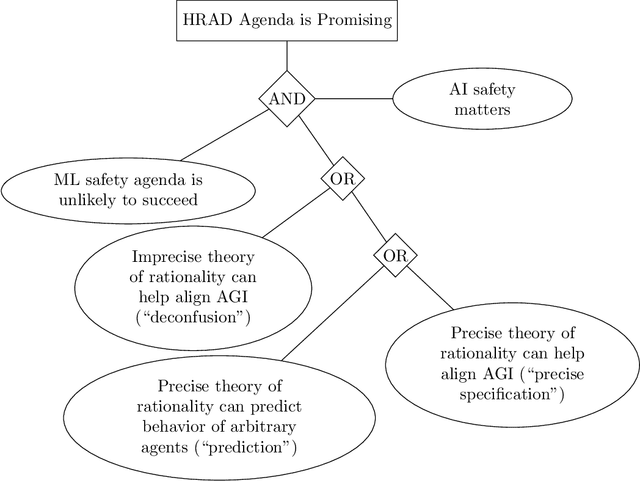
Several different approaches exist for ensuring the safety of future Transformative Artificial Intelligence (TAI) or Artificial Superintelligence (ASI) systems, and proponents of different approaches have made different and debated claims about the importance or usefulness of their work in the near term, and for future systems. Highly Reliable Agent Designs (HRAD) is one of the most controversial and ambitious approaches, championed by the Machine Intelligence Research Institute, among others, and various arguments have been made about whether and how it reduces risks from future AI systems. In order to reduce confusion in the debate about AI safety, here we build on a previous discussion by Rice which collects and presents four central arguments which are used to justify HRAD as a path towards safety of AI systems. We have titled the arguments (1) incidental utility,(2) deconfusion, (3) precise specification, and (4) prediction. Each of these makes different, partly conflicting claims about how future AI systems can be risky. We have explained the assumptions and claims based on a review of published and informal literature, along with consultation with experts who have stated positions on the topic. Finally, we have briefly outlined arguments against each approach and against the agenda overall.
Forecasting AI Progress: A Research Agenda
Aug 04, 2020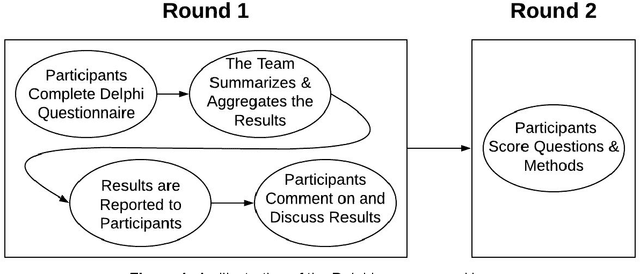

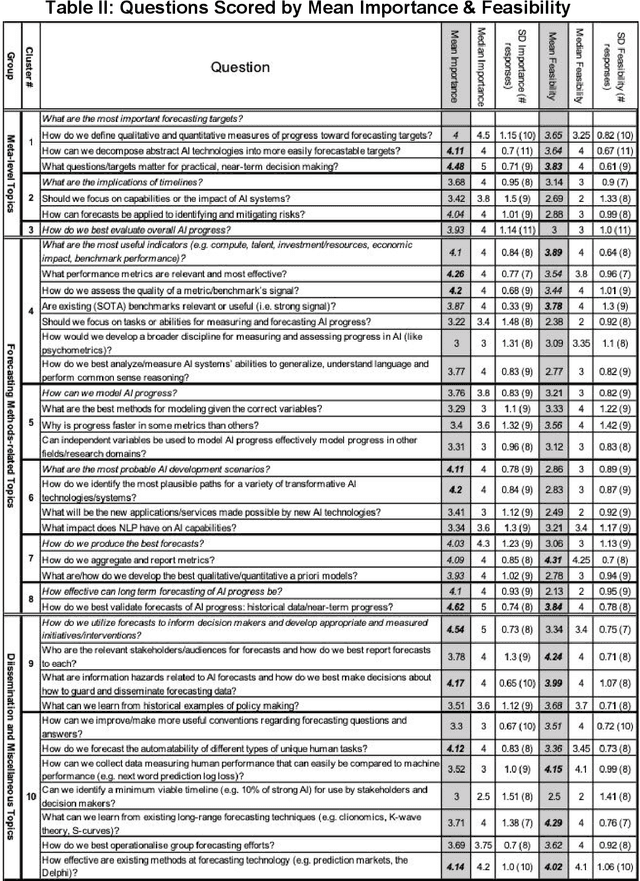
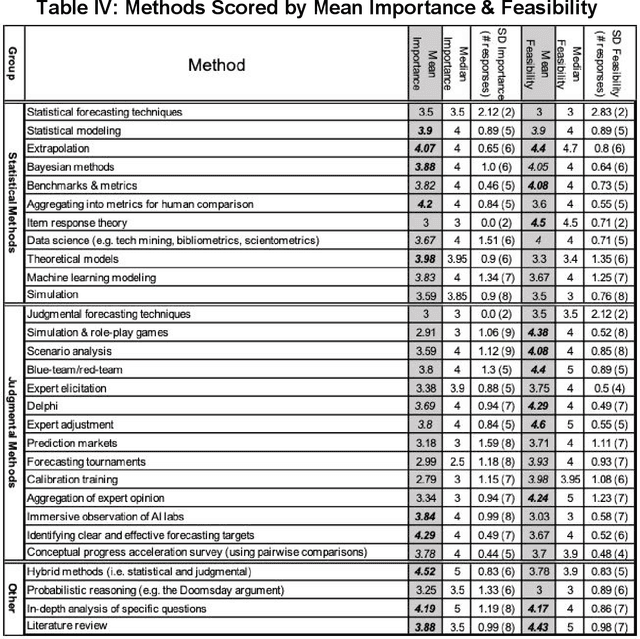
Forecasting AI progress is essential to reducing uncertainty in order to appropriately plan for research efforts on AI safety and AI governance. While this is generally considered to be an important topic, little work has been conducted on it and there is no published document that gives and objective overview of the field. Moreover, the field is very diverse and there is no published consensus regarding its direction. This paper describes the development of a research agenda for forecasting AI progress which utilized the Delphi technique to elicit and aggregate experts' opinions on what questions and methods to prioritize. The results of the Delphi are presented; the remainder of the paper follow the structure of these results, briefly reviewing relevant literature and suggesting future work for each topic. Experts indicated that a wide variety of methods should be considered for forecasting AI progress. Moreover, experts identified salient questions that were both general and completely unique to the problem of forecasting AI progress. Some of the highest priority topics include the validation of (partially unresolved) forecasts, how to make forecasting action-guiding and the quality of different performance metrics. While statistical methods seem more promising, there is also recognition that supplementing judgmental techniques can be quite beneficial.
Oversight of Unsafe Systems via Dynamic Safety Envelopes
Nov 22, 2018This paper reviews the reasons that Human-in-the-Loop is both critical for preventing widely-understood failure modes for machine learning, and not a practical solution. Following this, we review two current heuristic methods for addressing this. The first is provable safety envelopes, which are possible only when the dynamics of the system are fully known, but can be useful safety guarantees when optimal behavior is based on machine learning with poorly-understood safety characteristics. The second is the simpler circuit breaker model, which can forestall or prevent catastrophic outcomes by stopping the system, without any specific model of the system. This paper proposes using heuristic, dynamic safety envelopes, which are a plausible halfway point between these approaches that allows human oversight without some of the more difficult problems faced by Human-in-the-Loop systems. Finally, the paper concludes with how this approach can be used for governance of systems where otherwise unsafe systems are deployed.
Overoptimization Failures and Specification Gaming in Multi-agent Systems
Oct 31, 2018Overoptimization failures in machine learning and AI can involve specification gaming, reward hacking, fragility to distributional shifts, and Goodhart's or Campbell's law. These failure modes are an important challenge in building safe AI systems, but multi-agent systems have additional related failure modes. The equivalent failure modes for multi-agent systems are more complex, more problematic, and less well understood. This paper explains why this is the case, then lays out some of the classes of such failure, such as accidental steering, coordination failures, adversarial misalignment, input spoofing and filtering, and goal co-option or direct hacking.
Categorizing Variants of Goodhart's Law
Apr 09, 2018There are several distinct failure modes for overoptimization of systems on the basis of metrics. This occurs when a metric which can be used to improve a system is used to an extent that further optimization is ineffective or harmful, and is sometimes termed Goodhart's Law. This class of failure is often poorly understood, partly because terminology for discussing them is ambiguous, and partly because discussion using this ambiguous terminology ignores distinctions between different failure modes of this general type. This paper expands on an earlier discussion by Garrabrant, which notes there are "(at least) four different mechanisms" that relate to Goodhart's Law. This paper is intended to explore these mechanisms further, and specify more clearly how they occur. This discussion should be helpful in better understanding these types of failures in economic regulation, in public policy, in machine learning, and in Artificial Intelligence alignment. The importance of Goodhart effects depends on the amount of power directed towards optimizing the proxy, and so the increased optimization power offered by artificial intelligence makes it especially critical for that field.