 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Transformative AI Risks (MTAIR) Project -- Summary Report
Jun 19, 2022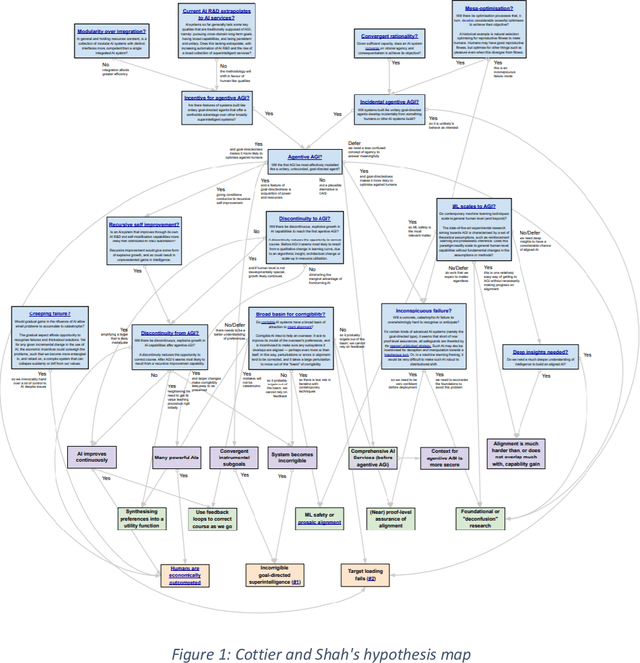
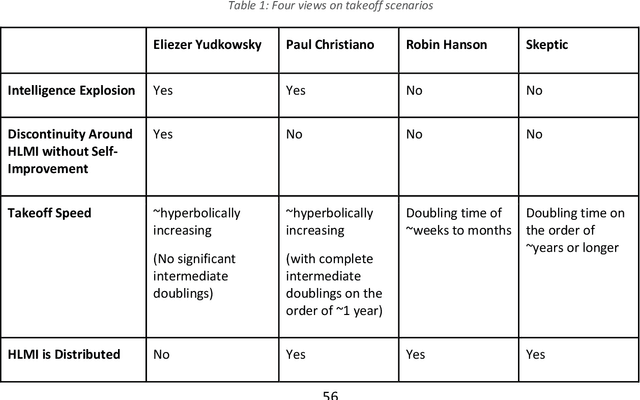
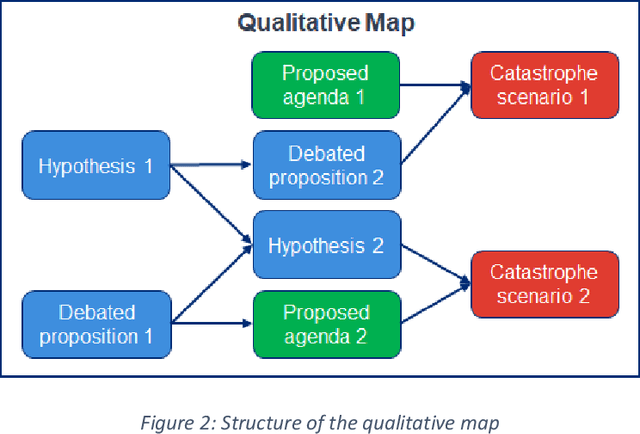
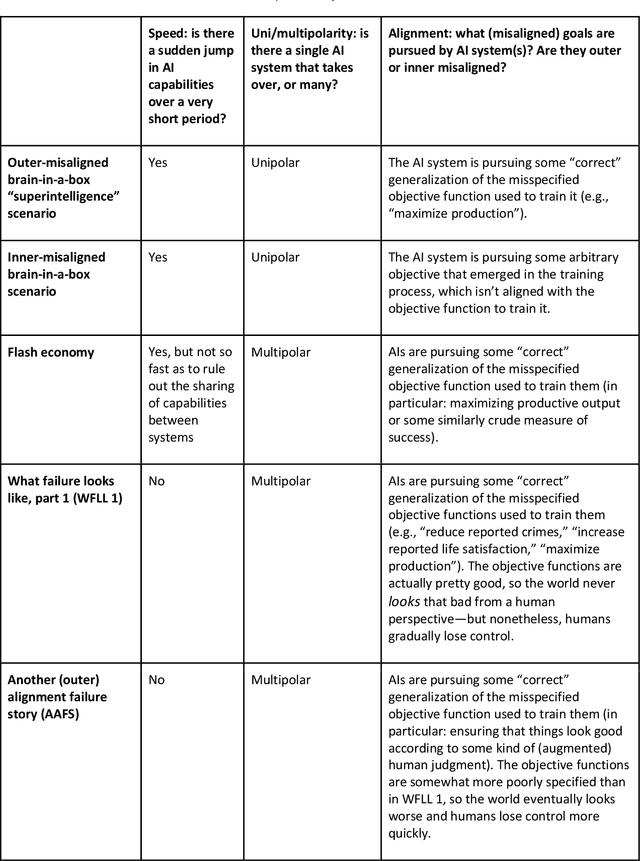
This report outlines work by the Modeling Transformative AI Risk (MTAIR) project, an attempt to map out the key hypotheses, uncertainties, and disagreements in debates about catastrophic risks from advanced AI, and the relationships between them. This builds on an earlier diagram by Ben Cottier and Rohin Shah which laid out some of the crucial disagreements ("cruxes") visually, with some explanation. Based on an extensive literature review and engagement with experts, the report explains a model of the issues involved, and the initial software-based implementation that can incorporate probability estimates or other quantitative factors to enable exploration, planning, and/or decision support. By gathering information from various debates and discussions into a single more coherent presentation, we hope to enable better discussions and debates about the issues involved. The model starts with a discussion of reasoning via analogies and general prior beliefs about artificial intelligence. Following this, it lays out a model of different paths and enabling technologies for high-level machine intelligence, and a model of how advances in the capabilities of these systems might proceed, including debates about self-improvement, discontinuous improvements, and the possibility of distributed, non-agentic high-level intelligence or slower improvements. The model also looks specifically at the question of learned optimization, and whether machine learning systems will create mesa-optimizers. The impact of different safety research on the previous sets of questions is then examined, to understand whether and how research could be useful in enabling safer systems. Finally, we discuss a model of different failure modes and loss of control or takeover scenarios.
Arguments about Highly Reliable Agent Designs as a Useful Path to Artificial Intelligence Safety
Jan 09, 2022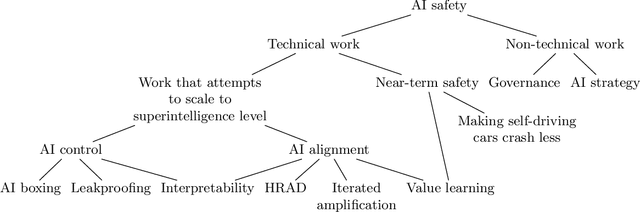
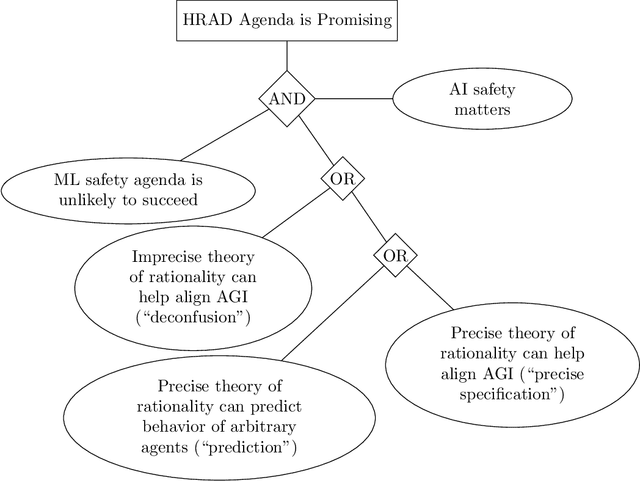
Several different approaches exist for ensuring the safety of future Transformative Artificial Intelligence (TAI) or Artificial Superintelligence (ASI) systems, and proponents of different approaches have made different and debated claims about the importance or usefulness of their work in the near term, and for future systems. Highly Reliable Agent Designs (HRAD) is one of the most controversial and ambitious approaches, championed by the Machine Intelligence Research Institute, among others, and various arguments have been made about whether and how it reduces risks from future AI systems. In order to reduce confusion in the debate about AI safety, here we build on a previous discussion by Rice which collects and presents four central arguments which are used to justify HRAD as a path towards safety of AI systems. We have titled the arguments (1) incidental utility,(2) deconfusion, (3) precise specification, and (4) prediction. Each of these makes different, partly conflicting claims about how future AI systems can be risky. We have explained the assumptions and claims based on a review of published and informal literature, along with consultation with experts who have stated positions on the topic. Finally, we have briefly outlined arguments against each approach and against the agenda overall.