 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
Beyond the training set: an intuitive method for detecting distribution shift in model-based optimization
Nov 09, 2023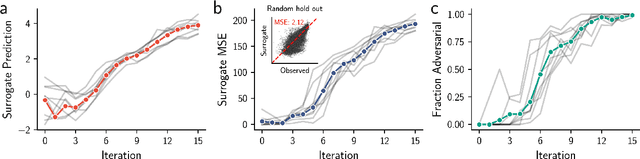
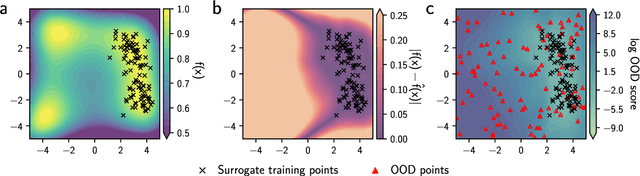
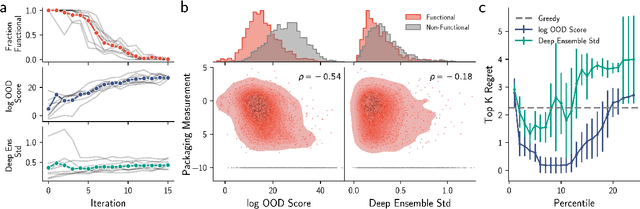
Model-based optimization (MBO) is increasingly applied to design problems in science and engineering. A common scenario involves using a fixed training set to train models, with the goal of designing new samples that outperform those present in the training data. A major challenge in this setting is distribution shift, where the distributions of training and design samples are different. While some shift is expected, as the goal is to create better designs, this change can negatively affect model accuracy and subsequently, design quality. Despite the widespread nature of this problem, addressing it demands deep domain knowledge and artful application. To tackle this issue, we propose a straightforward method for design practitioners that detects distribution shifts. This method trains a binary classifier using knowledge of the unlabeled design distribution to separate the training data from the design data. The classifier's logit scores are then used as a proxy measure of distribution shift. We validate our method in a real-world application by running offline MBO and evaluate the effect of distribution shift on design quality. We find that the intensity of the shift in the design distribution varies based on the number of steps taken by the optimization algorithm, and our simple approach can identify these shifts. This enables users to constrain their search to regions where the model's predictions are reliable, thereby increasing the quality of designs.