 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised estimation of event temporal length for cell event detection
Sep 22, 2019
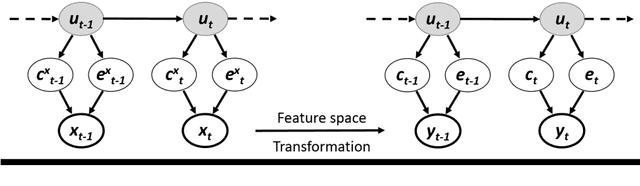
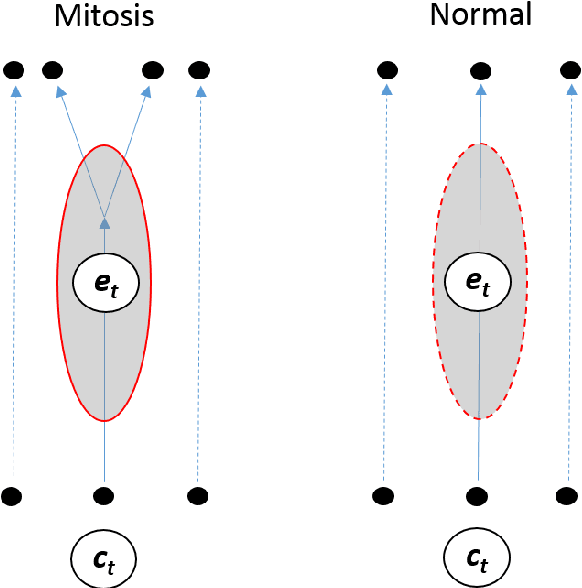
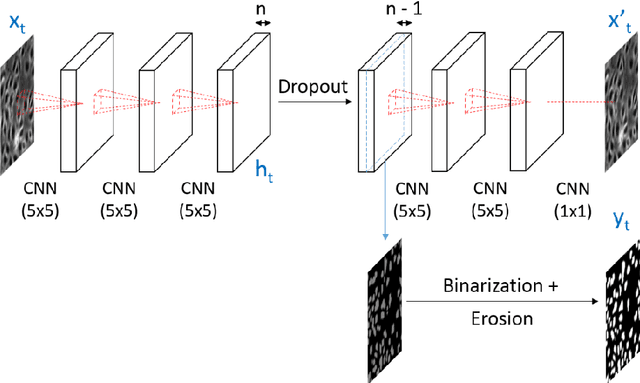
Cell event detection in cell videos is essential for monitoring of cellular behavior over extended time periods. Deep learning methods have shown great success in the detection of cell events for their ability to capture more discriminative features of cellular processes compared to traditional methods. In particular, convolutional long short-term memory (LSTM) models, which exploits the changes in cell events observable in video sequences, is the state-of-the-art for mitosis detection in cell videos. However, their limitations are the determination of the input sequence length, which is often performed empirically, and the need for a large annotated training dataset which is expensive to prepare. We propose a novel semi-supervised method of optimal length detection for mitosis detection with two key contributions: (i) an unsupervised step for learning the spatial and temporal locations of cells in their normal stage and approximating the distribution of temporal lengths of cell events and, (ii) a step of inferring, from that distribution, an optimal input sequence length and a minimal number of annotated frames for training a LSTM model for each particular video. We evaluated our method in detecting mitosis in densely packed stem cells in a phase-contrast microscopy videos. Our experimental data prove that increasing the input sequence length of LSTM can lead to a decrease in performance. Our results also show that by approximating the optimal input sequence length of the tested video, a model trained with only 18 annotated frames achieved F1-scores of 0.880-0.907, which are 10% higher than those of other published methods with a full set of 110 training annotated frames.
An unsupervised long short-term memory neural network for event detection in cell videos
Sep 07, 2017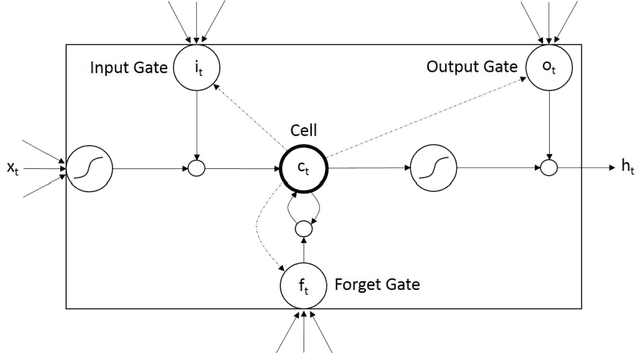
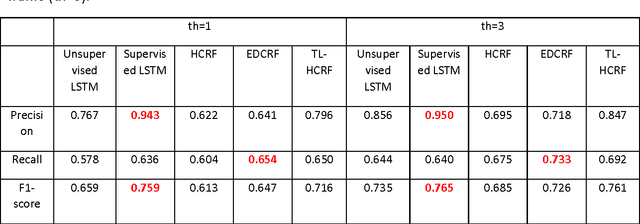
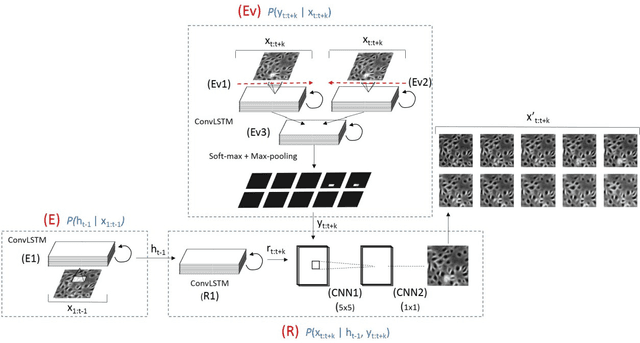
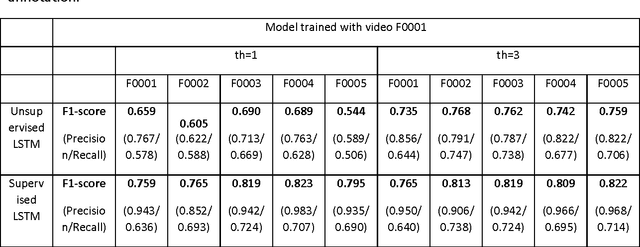
We propose an automatic unsupervised cell event detection and classification method, which expands convolutional Long Short-Term Memory (LSTM) neural networks, for cellular events in cell video sequences. Cells in images that are captured from various biomedical applications usually have different shapes and motility, which pose difficulties for the automated event detection in cell videos. Current methods to detect cellular events are based on supervised machine learning and rely on tedious manual annotation from investigators with specific expertise. So that our LSTM network could be trained in an unsupervised manner, we designed it with a branched structure where one branch learns the frequent, regular appearance and movements of objects and the second learns the stochastic events, which occur rarely and without warning in a cell video sequence. We tested our network on a publicly available dataset of densely packed stem cell phase-contrast microscopy images undergoing cell division. This dataset is considered to be more challenging that a dataset with sparse cells. We compared our method to several published supervised methods evaluated on the same dataset and to a supervised LSTM method with a similar design and configuration to our unsupervised method. We used an F1-score, which is a balanced measure for both precision and recall. Our results show that our unsupervised method has a higher or similar F1-score when compared to two fully supervised methods that are based on Hidden Conditional Random Fields (HCRF), and has comparable accuracy with the current best supervised HCRF-based method. Our method was generalizable as after being trained on one video it could be applied to videos where the cells were in different conditions. The accuracy of our unsupervised method approached that of its supervised counterpart.
Learning RGB-D Salient Object Detection using background enclosure, depth contrast, and top-down features
May 10, 2017
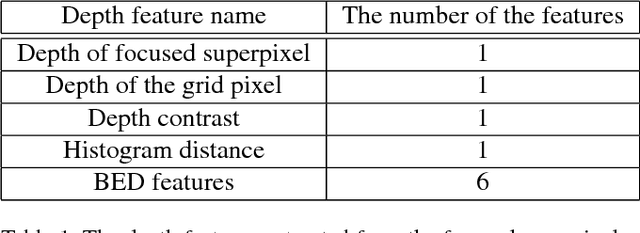
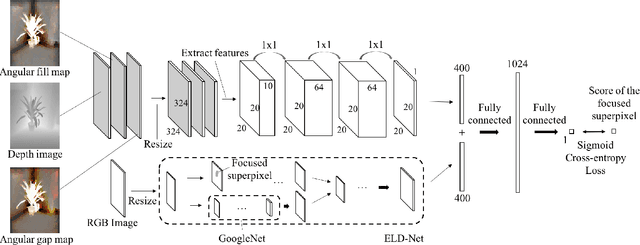
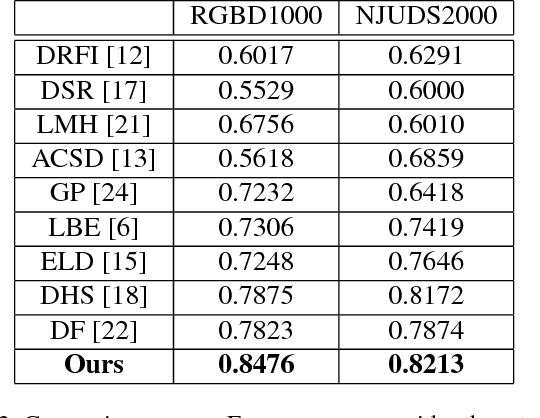
Recently, deep Convolutional Neural Networks (CNN) have demonstrated strong performance on RGB salient object detection. Although, depth information can help improve detection results, the exploration of CNNs for RGB-D salient object detection remains limited. Here we propose a novel deep CNN architecture for RGB-D salient object detection that exploits high-level, mid-level, and low level features. Further, we present novel depth features that capture the ideas of background enclosure and depth contrast that are suitable for a learned approach. We show improved results compared to state-of-the-art RGB-D salient object detection methods. We also show that the low-level and mid-level depth features both contribute to improvements in the results. Especially, F-Score of our method is 0.848 on RGBD1000 dataset, which is 10.7% better than the second place.