 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARexp: A Python Framework for Technology-Assisted Review Experiments
Feb 23, 2022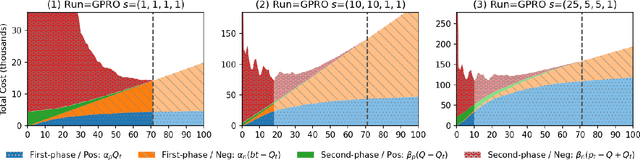
Technology-assisted review (TAR) is an important industrial application of information retrieval (IR) and machine learning (ML). While a small TAR research community exists, the complexity of TAR software and workflows is a major barrier to entry. Drawing on past open source TAR efforts, as well as design patterns from the IR and ML open source software, we present an open source Python framework for conducting experiments on TAR algorithms. Key characteristics of this framework are declarative representations of workflows and experiment plans, the ability for components to play variable numbers of workflow roles, and state maintenance and restart capabilities. Users can draw on reference implementations of standard TAR algorithms while incorporating novel components to explore their research interests. The framework is available at https://github.com/eugene-yang/tarexp.
TAR on Social Media: A Framework for Online Content Moderation
Aug 29, 2021
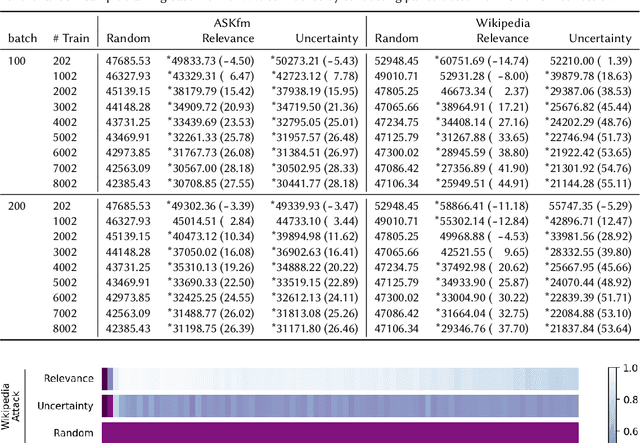
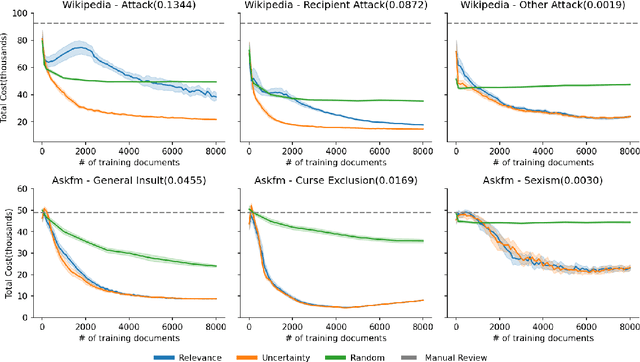
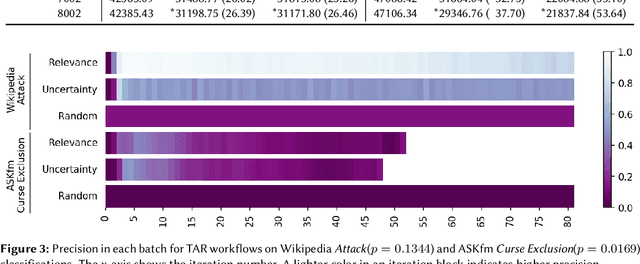
Content moderation (removing or limiting the distribution of posts based on their contents) is one tool social networks use to fight problems such as harassment and disinformation. Manually screening all content is usually impractical given the scale of social media data, and the need for nuanced human interpretations makes fully automated approaches infeasible. We consider content moderation from the perspective of technology-assisted review (TAR): a human-in-the-loop active learning approach developed for high recall retrieval problems in civil litigation and other fields. We show how TAR workflows, and a TAR cost model, can be adapted to the content moderation problem. We then demonstrate on two publicly available content moderation data sets that a TAR workflow can reduce moderation costs by 20% to 55% across a variety of conditions.
Certifying One-Phase Technology-Assisted Reviews
Aug 29, 2021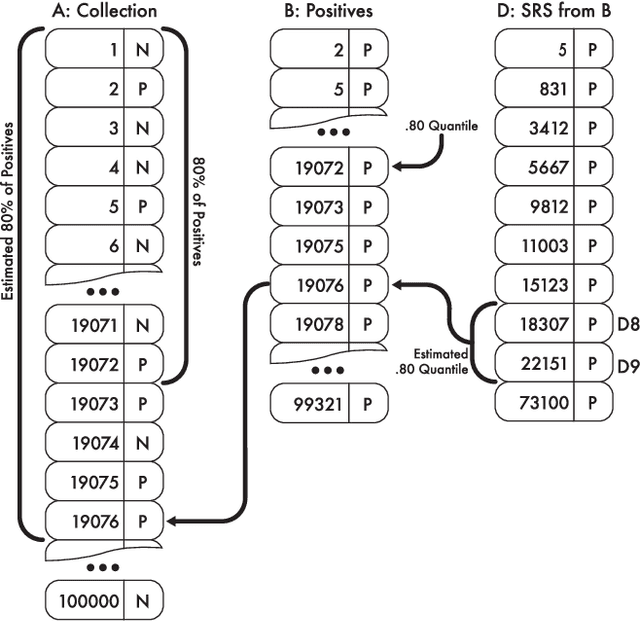
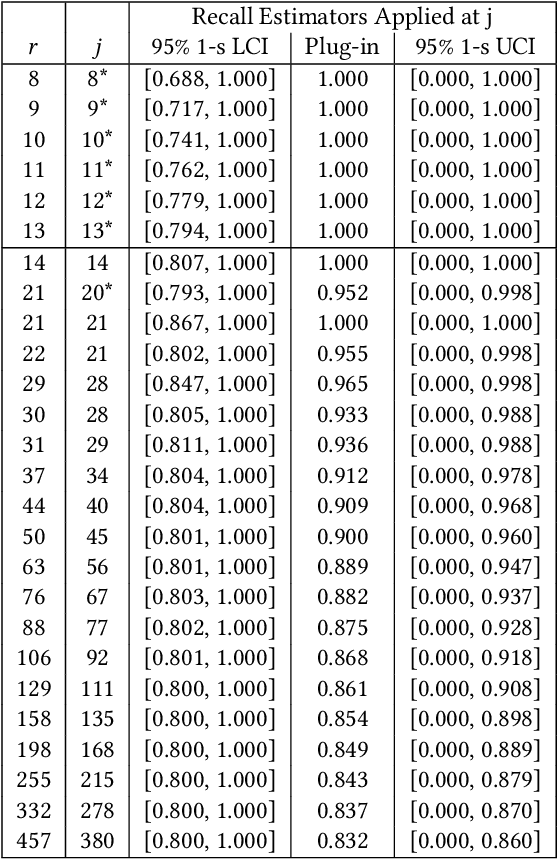
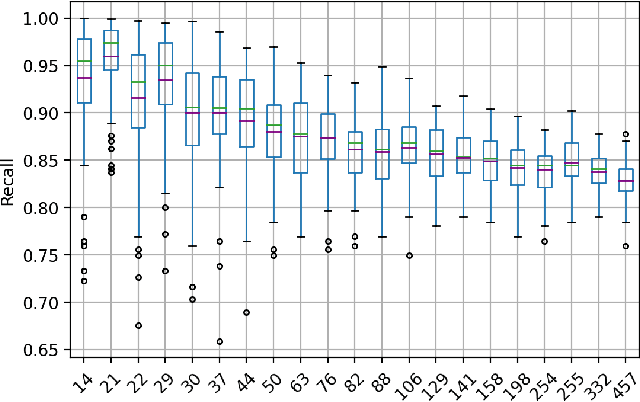
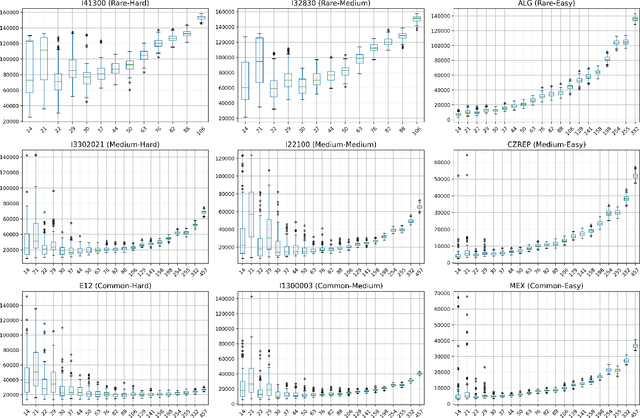
Technology-assisted review (TAR) workflows based on iterative active learning are widely used in document review applications. Most stopping rules for one-phase TAR workflows lack valid statistical guarantees, which has discouraged their use in some legal contexts. Drawing on the theory of quantile estimation, we provide the first broadly applicable and statistically valid sample-based stopping rules for one-phase TAR. We further show theoretically and empirically that overshooting a recall target, which has been treated as innocuous or desirable in past evaluations of stopping rules, is a major source of excess cost in one-phase TAR workflows. Counterintuitively, incurring a larger sampling cost to reduce excess recall leads to lower total cost in almost all scenarios.
Heuristic Stopping Rules For Technology-Assisted Review
Jun 18, 2021
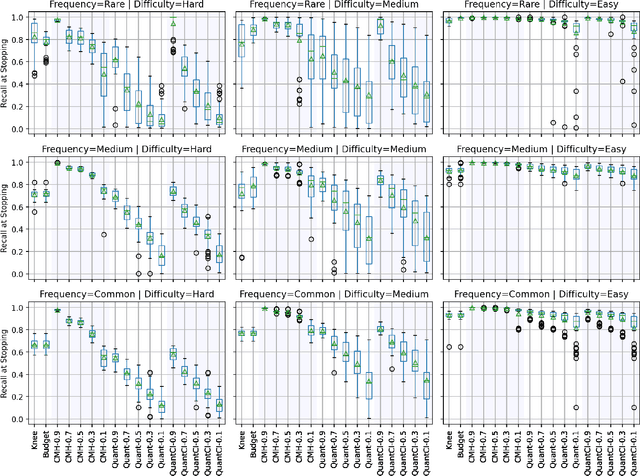
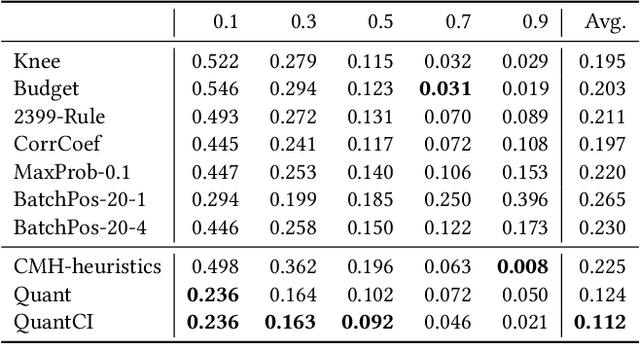

Technology-assisted review (TAR) refers to human-in-the-loop active learning workflows for finding relevant documents in large collections. These workflows often must meet a target for the proportion of relevant documents found (i.e. recall) while also holding down costs. A variety of heuristic stopping rules have been suggested for striking this tradeoff in particular settings, but none have been tested against a range of recall targets and tasks. We propose two new heuristic stopping rules, Quant and QuantCI based on model-based estimation techniques from survey research. We compare them against a range of proposed heuristics and find they are accurate at hitting a range of recall targets while substantially reducing review costs.
On Minimizing Cost in Legal Document Review Workflows
Jun 18, 2021
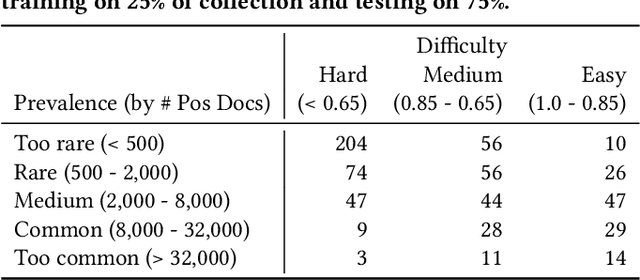

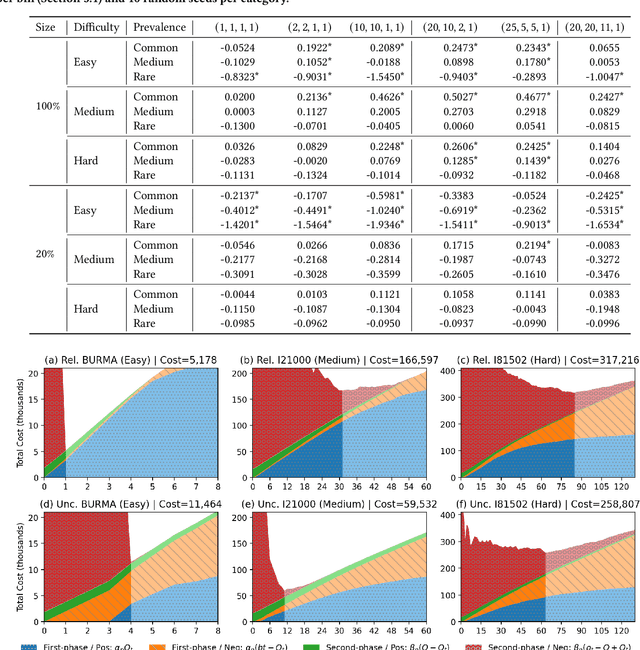
Technology-assisted review (TAR) refers to human-in-the-loop machine learning workflows for document review in legal discovery and other high recall review tasks. Attorneys and legal technologists have debated whether review should be a single iterative process (one-phase TAR workflows) or whether model training and review should be separate (two-phase TAR workflows), with implications for the choice of active learning algorithm. The relative cost of manual labeling for different purposes (training vs. review) and of different documents (positive vs. negative examples) is a key and neglected factor in this debate. Using a novel cost dynamics analysis, we show analytically and empirically that these relative costs strongly impact whether a one-phase or two-phase workflow minimizes cost. We also show how category prevalence, classification task difficulty, and collection size impact the optimal choice not only of workflow type, but of active learning method and stopping point.
Goldilocks: Just-Right Tuning of BERT for Technology-Assisted Review
May 03, 2021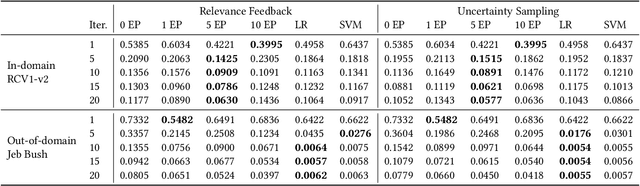
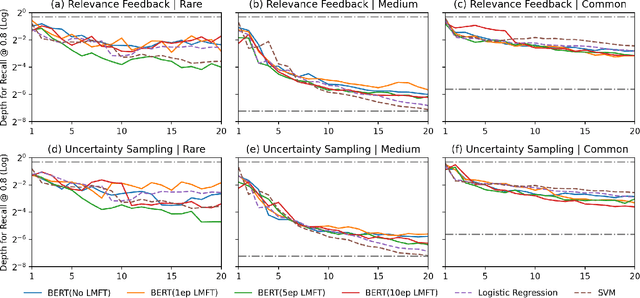
Technology-assisted review (TAR) refers to iterative active learning workflows for document review in high recall retrieval (HRR) tasks. TAR research and most commercial TAR software have applied linear models such as logistic regression or support vector machines to lexical features. Transformer-based models with supervised tuning have been found to improve effectiveness on many text classification tasks, suggesting their use in TAR. We indeed find that the pre-trained BERT model reduces review volume by 30% in TAR workflows simulated on the RCV1-v2 newswire collection. In contrast, we find that linear models outperform BERT for simulated legal discovery topics on the Jeb Bush e-mail collection. This suggests the match between transformer pre-training corpora and the task domain is more important than generally appreciated. Additionally, we show that just-right language model fine-tuning on the task collection before starting active learning is critical. Both too little or too much fine-tuning results in performance worse than that of linear models, even for RCV1-v2.
A Sequential Algorithm for Training Text Classifiers
Jul 25, 1994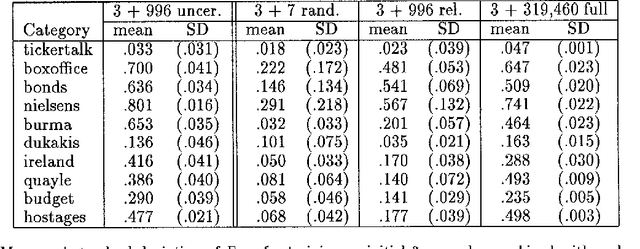
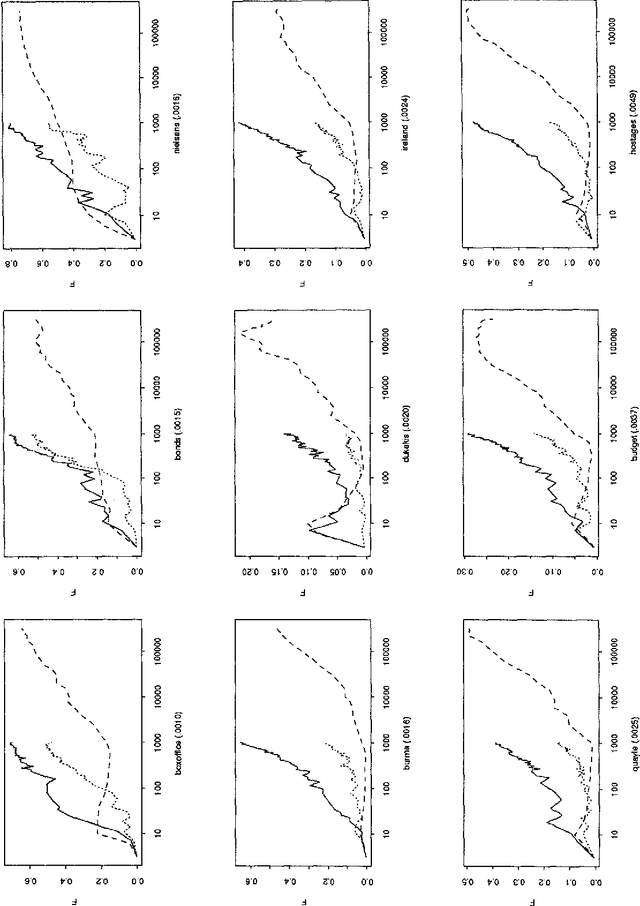
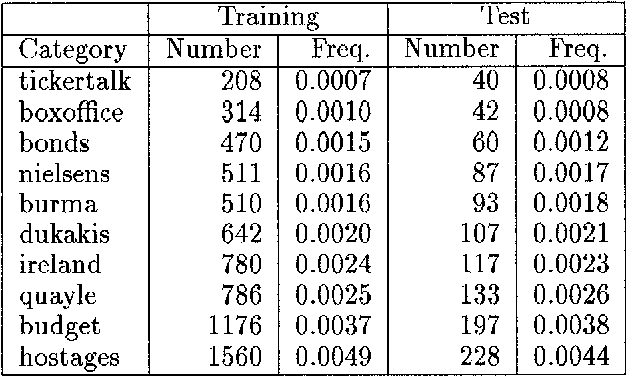
The ability to cheaply train text classifiers is critical to their use in information retrieval, content analysis, natural language processing, and other tasks involving data which is partly or fully textual. An algorithm for sequential sampling during machine learning of statistical classifiers was developed and tested on a newswire text categorization task. This method, which we call uncertainty sampling, reduced by as much as 500-fold the amount of training data that would have to be manually classified to achieve a given level of effectiveness.