 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifying One-Phase Technology-Assisted Reviews
Paper and Code
Aug 29, 2021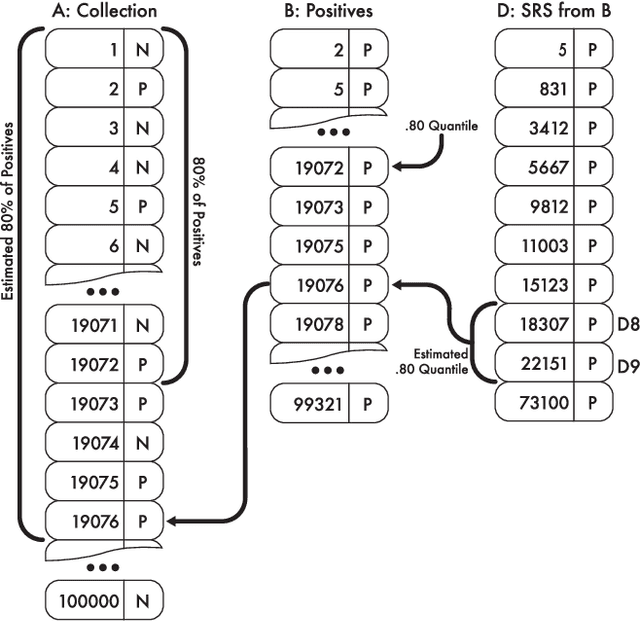
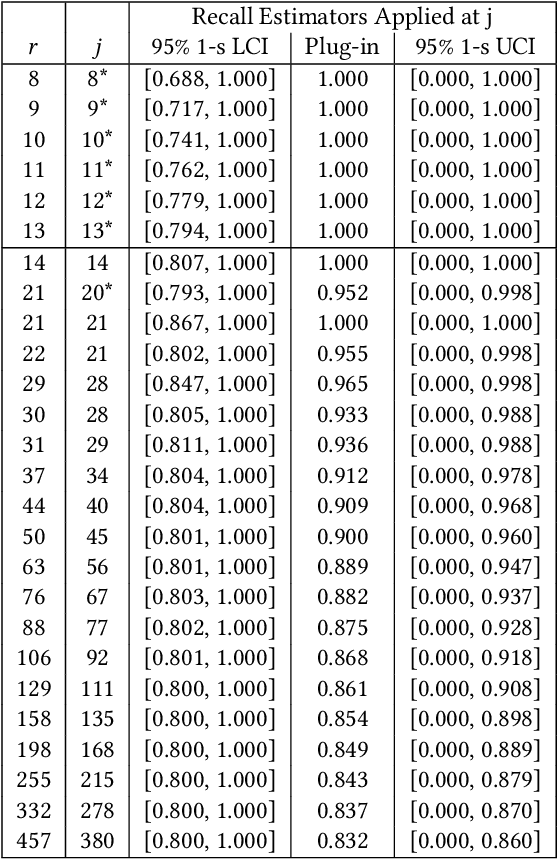
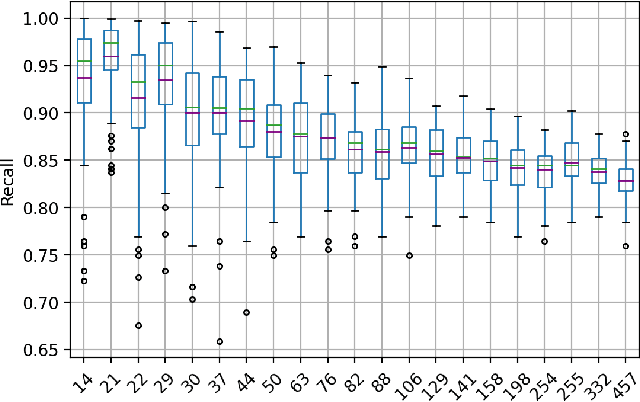
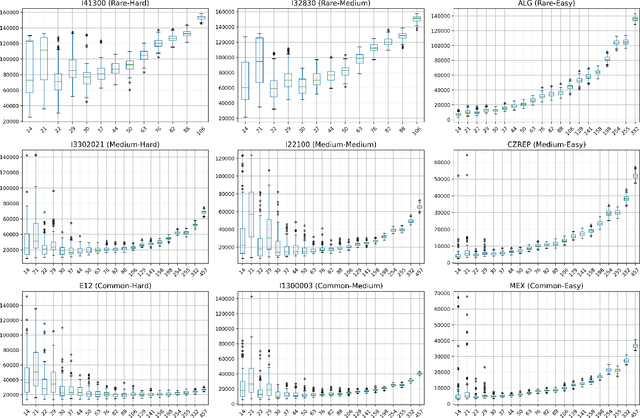
Technology-assisted review (TAR) workflows based on iterative active learning are widely used in document review applications. Most stopping rules for one-phase TAR workflows lack valid statistical guarantees, which has discouraged their use in some legal contexts. Drawing on the theory of quantile estimation, we provide the first broadly applicable and statistically valid sample-based stopping rules for one-phase TAR. We further show theoretically and empirically that overshooting a recall target, which has been treated as innocuous or desirable in past evaluations of stopping rules, is a major source of excess cost in one-phase TAR workflows. Counterintuitively, incurring a larger sampling cost to reduce excess recall leads to lower total cost in almost all scenarios.