 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain adapted machine translation: What does catastrophic forgetting forget and why?
Dec 23, 2024



Neural Machine Translation (NMT) models can be specialized by domain adaptation, often involving fine-tuning on a dataset of interest. This process risks catastrophic forgetting: rapid loss of generic translation quality. Forgetting has been widely observed, with many mitigation methods proposed. However, the causes of forgetting and the relationship between forgetting and adaptation data are under-explored. This paper takes a novel approach to understanding catastrophic forgetting during NMT adaptation by investigating the impact of the data. We provide a first investigation of what is forgotten, and why. We examine the relationship between forgetting and the in-domain data, and show that the amount and type of forgetting is linked to that data's target vocabulary coverage. Our findings pave the way toward better informed NMT domain adaptation.
Gender, names and other mysteries: Towards the ambiguous for gender-inclusive translation
Jun 07, 2023The vast majority of work on gender in MT focuses on 'unambiguous' inputs, where gender markers in the source language are expected to be resolved in the output. Conversely, this paper explores the widespread case where the source sentence lacks explicit gender markers, but the target sentence contains them due to richer grammatical gender. We particularly focus on inputs containing person names. Investigating such sentence pairs casts a new light on research into MT gender bias and its mitigation. We find that many name-gender co-occurrences in MT data are not resolvable with 'unambiguous gender' in the source language, and that gender-ambiguous examples can make up a large proportion of training examples. From this, we discuss potential steps toward gender-inclusive translation which accepts the ambiguity in both gender and translation.
First the worst: Finding better gender translations during beam search
Apr 15, 2021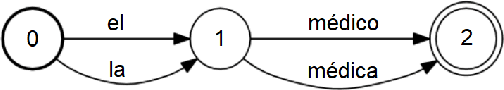
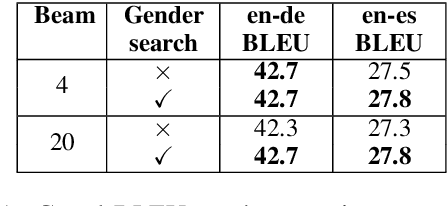


Neural machine translation inference procedures like beam search generate the most likely output under the model. This can exacerbate any demographic biases exhibited by the model. We focus on gender bias resulting from systematic errors in grammatical gender translation, which can lead to human referents being misrepresented or misgendered. Most approaches to this problem adjust the training data or the model. By contrast, we experiment with simply adjusting the inference procedure. We experiment with reranking nbest lists using gender features obtained automatically from the source sentence, and applying gender constraints while decoding to improve nbest list gender diversity. We find that a combination of these techniques allows large gains in WinoMT accuracy without requiring additional bilingual data or an additional NMT model.
Domain Adaptation and Multi-Domain Adaptation for Neural Machine Translation: A Survey
Apr 14, 2021

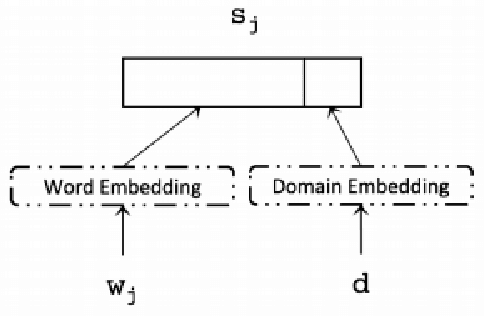

The development of deep learning techniques has allowed Neural Machine Translation (NMT) models to become extremely powerful, given sufficient training data and training time. However, systems struggle when translating text from a new domain with a distinct style or vocabulary. Tuning on a representative training corpus allows good in-domain translation, but such data-centric approaches can cause over-fitting to new data and `catastrophic forgetting' of previously learned behaviour. We concentrate on more robust approaches to domain adaptation for NMT, particularly the case where a system may need to translate sentences from multiple domains. We divide techniques into those relating to data selection, model architecture, parameter adaptation procedure, and inference procedure. We finally highlight the benefits of domain adaptation and multi-domain adaptation techniques to other lines of NMT research.
Inference-only sub-character decomposition improves translation of unseen logographic characters
Nov 12, 2020
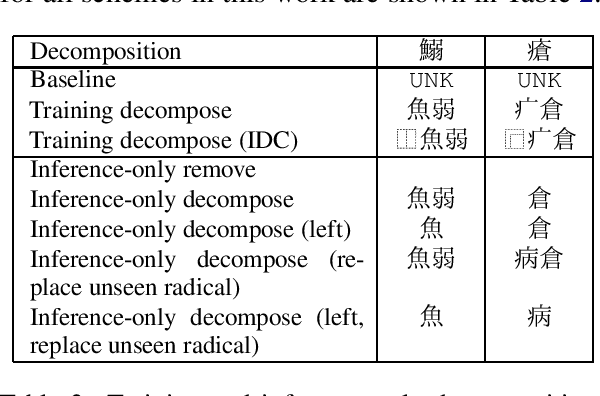

Neural Machine Translation (NMT) on logographic source languages struggles when translating `unseen' characters, which never appear in the training data. One possible approach to this problem uses sub-character decomposition for training and test sentences. However, this approach involves complete retraining, and its effectiveness for unseen character translation to non-logographic languages has not been fully explored. We investigate existing ideograph-based sub-character decomposition approaches for Chinese-to-English and Japanese-to-English NMT, for both high-resource and low-resource domains. For each language pair and domain we construct a test set where all source sentences contain at least one unseen logographic character. We find that complete sub-character decomposition often harms unseen character translation, and gives inconsistent results generally. We offer a simple alternative based on decomposition before inference for unseen characters only. Our approach allows flexible application, achieving translation adequacy improvements and requiring no additional models or training.
Addressing Exposure Bias With Document Minimum Risk Training: Cambridge at the WMT20 Biomedical Translation Task
Oct 11, 2020
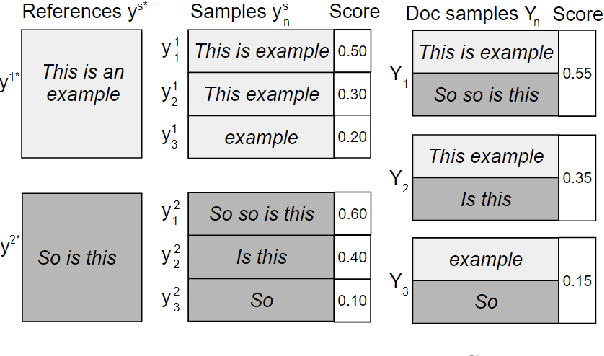
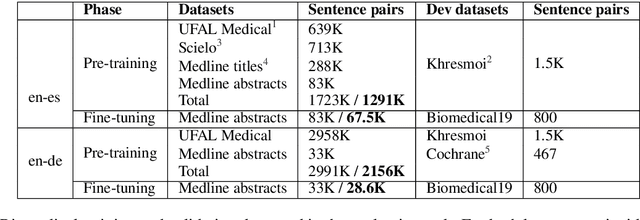
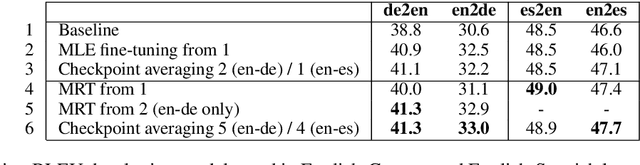
The 2020 WMT Biomedical translation task evaluated Medline abstract translations. This is a small-domain translation task, meaning limited relevant training data with very distinct style and vocabulary. Models trained on such data are susceptible to exposure bias effects, particularly when training sentence pairs are imperfect translations of each other. This can result in poor behaviour during inference if the model learns to neglect the source sentence. The UNICAM entry addresses this problem during fine-tuning using a robust variant on Minimum Risk Training. We contrast this approach with data-filtering to remove `problem' training examples. Under MRT fine-tuning we obtain good results for both directions of English-German and English-Spanish biomedical translation. In particular we achieve the best English-to-Spanish translation result and second-best Spanish-to-English result, despite using only single models with no ensembling.
Neural Machine Translation Doesn't Translate Gender Coreference Right Unless You Make It
Oct 11, 2020
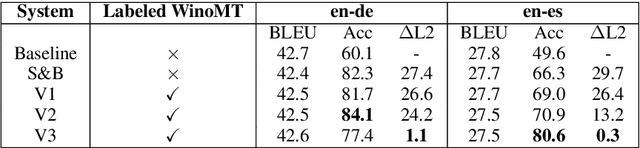
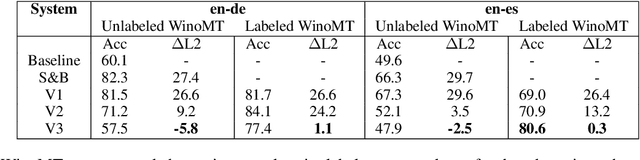
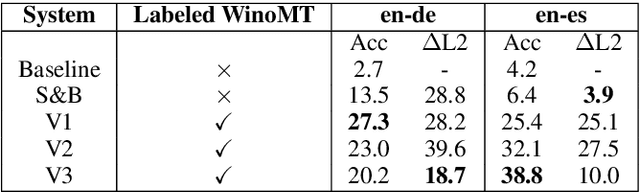
Neural Machine Translation (NMT) has been shown to struggle with grammatical gender that is dependent on the gender of human referents, which can cause gender bias effects. Many existing approaches to this problem seek to control gender inflection in the target language by explicitly or implicitly adding a gender feature to the source sentence, usually at the sentence level. In this paper we propose schemes for incorporating explicit word-level gender inflection tags into NMT. We explore the potential of this gender-inflection controlled translation when the gender feature can be determined from a human reference, assessing on English-to-Spanish and English-to-German translation. We find that simple existing approaches can over-generalize a gender-feature to multiple entities in a sentence, and suggest an effective alternative in the form of tagged coreference adaptation data. We also propose an extension to assess translations of gender-neutral entities from English given a corresponding linguistic convention in the inflected target language.
Using Context in Neural Machine Translation Training Objectives
May 04, 2020

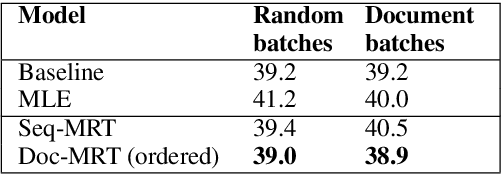
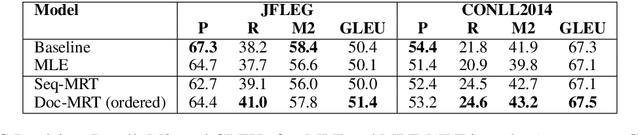
We present Neural Machine Translation (NMT) training using document-level metrics with batch-level documents. Previous sequence-objective approaches to NMT training focus exclusively on sentence-level metrics like sentence BLEU which do not correspond to the desired evaluation metric, typically document BLEU. Meanwhile research into document-level NMT training focuses on data or model architecture rather than training procedure. We find that each of these lines of research has a clear space in it for the other, and propose merging them with a scheme that allows a document-level evaluation metric to be used in the NMT training objective. We first sample pseudo-documents from sentence samples. We then approximate the expected document BLEU gradient with Monte Carlo sampling for use as a cost function in Minimum Risk Training (MRT). This two-level sampling procedure gives NMT performance gains over sequence MRT and maximum-likelihood training. We demonstrate that training is more robust for document-level metrics than with sequence metrics. We further demonstrate improvements on NMT with TER and Grammatical Error Correction (GEC) using GLEU, both metrics used at the document level for evaluations.
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Apr 21, 2020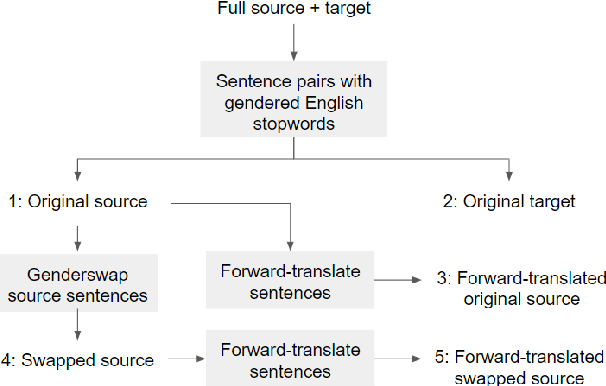

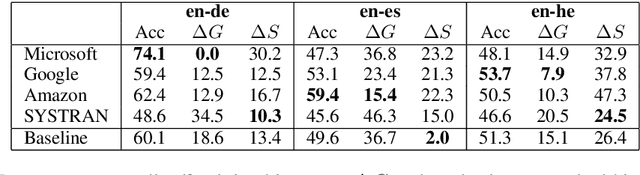

Training data for NLP tasks often exhibits gender bias in that fewer sentences refer to women than to men. In Neural Machine Translation (NMT) gender bias has been shown to reduce translation quality, particularly when the target language has grammatical gender. The recent WinoMT challenge set allows us to measure this effect directly (Stanovsky et al, 2019). Ideally we would reduce system bias by simply debiasing all data prior to training, but achieving this effectively is itself a challenge. Rather than attempt to create a `balanced' dataset, we use transfer learning on a small set of trusted, gender-balanced examples. This approach gives strong and consistent improvements in gender debiasing with much less computational cost than training from scratch. A known pitfall of transfer learning on new domains is `catastrophic forgetting', which we address both in adaptation and in inference. During adaptation we show that Elastic Weight Consolidation allows a performance trade-off between general translation quality and bias reduction. During inference we propose a lattice-rescoring scheme which outperforms all systems evaluated in Stanovsky et al (2019) on WinoMT with no degradation of general test set BLEU, and we show this scheme can be applied to remove gender bias in the output of `black box` online commercial MT systems. We demonstrate our approach translating from English into three languages with varied linguistic properties and data availability.
UCAM Biomedical translation at WMT19: Transfer learning multi-domain ensembles
Jun 13, 2019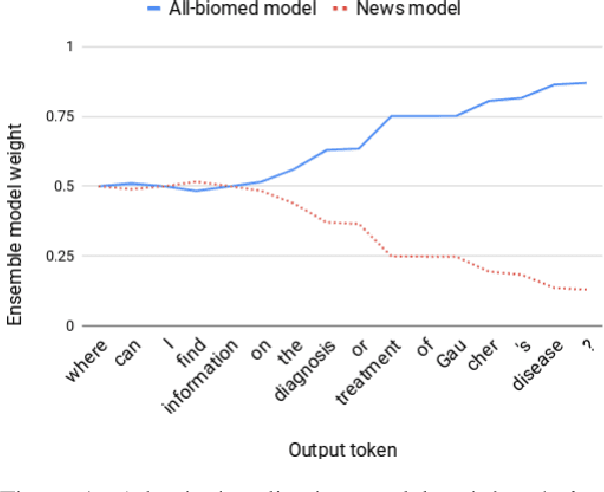
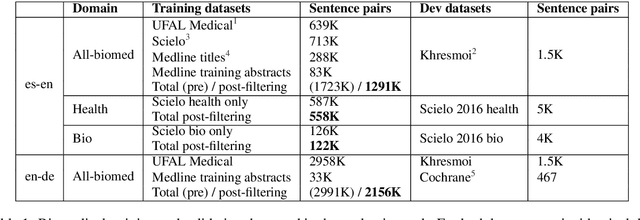
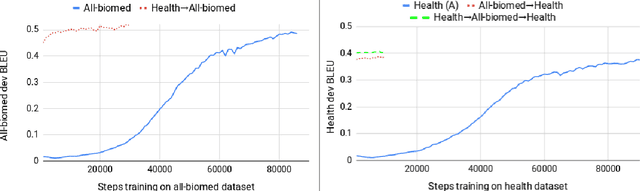
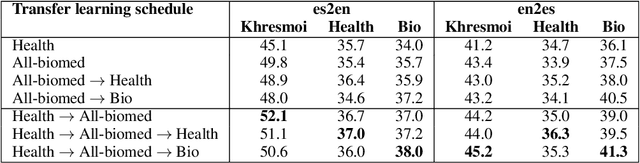
The 2019 WMT Biomedical translation task involved translating Medline abstracts. We approached this using transfer learning to obtain a series of strong neural models on distinct domains, and combining them into multi-domain ensembles. We further experiment with an adaptive language-model ensemble weighting scheme. Our submission achieved the best submitted results on both directions of English-Spanish.