 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-only sub-character decomposition improves translation of unseen logographic characters
Nov 12, 2020
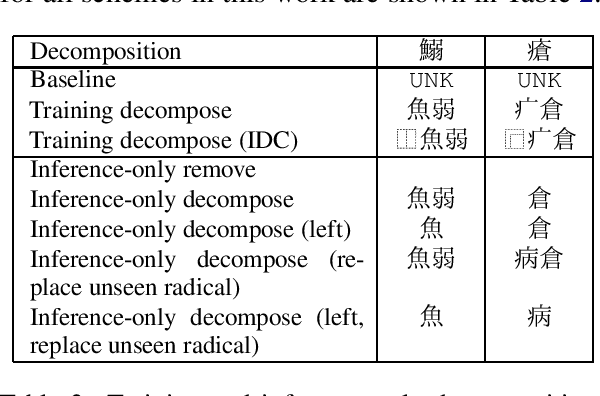
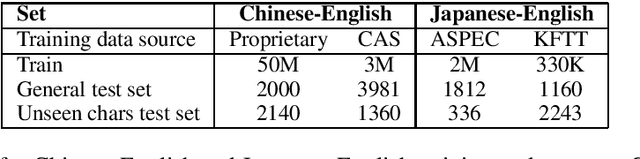

Neural Machine Translation (NMT) on logographic source languages struggles when translating `unseen' characters, which never appear in the training data. One possible approach to this problem uses sub-character decomposition for training and test sentences. However, this approach involves complete retraining, and its effectiveness for unseen character translation to non-logographic languages has not been fully explored. We investigate existing ideograph-based sub-character decomposition approaches for Chinese-to-English and Japanese-to-English NMT, for both high-resource and low-resource domains. For each language pair and domain we construct a test set where all source sentences contain at least one unseen logographic character. We find that complete sub-character decomposition often harms unseen character translation, and gives inconsistent results generally. We offer a simple alternative based on decomposition before inference for unseen characters only. Our approach allows flexible application, achieving translation adequacy improvements and requiring no additional models or training.