 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation and Multi-Domain Adaptation for Neural Machine Translation: A Survey
Paper and Code
Apr 14, 2021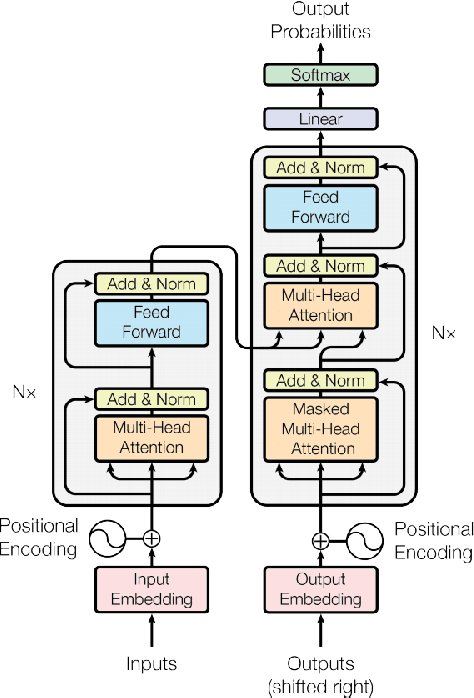

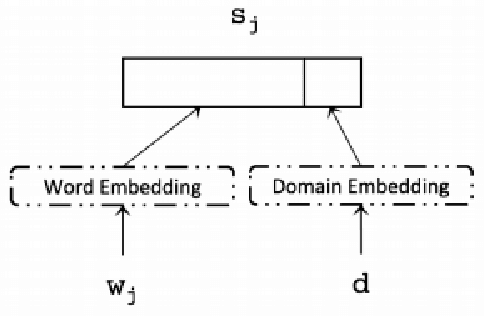

The development of deep learning techniques has allowed Neural Machine Translation (NMT) models to become extremely powerful, given sufficient training data and training time. However, systems struggle when translating text from a new domain with a distinct style or vocabulary. Tuning on a representative training corpus allows good in-domain translation, but such data-centric approaches can cause over-fitting to new data and `catastrophic forgetting' of previously learned behaviour. We concentrate on more robust approaches to domain adaptation for NMT, particularly the case where a system may need to translate sentences from multiple domains. We divide techniques into those relating to data selection, model architecture, parameter adaptation procedure, and inference procedure. We finally highlight the benefits of domain adaptation and multi-domain adaptation techniques to other lines of NMT research.