 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Exposure Bias With Document Minimum Risk Training: Cambridge at the WMT20 Biomedical Translation Task
Paper and Code

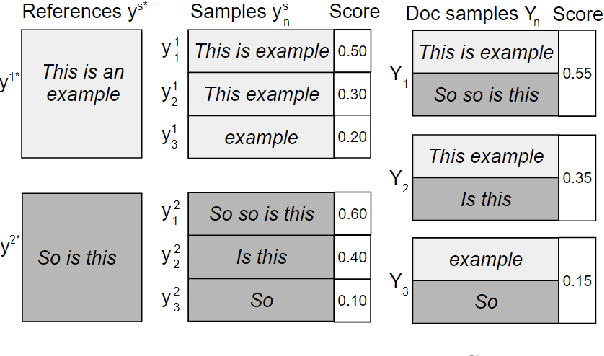
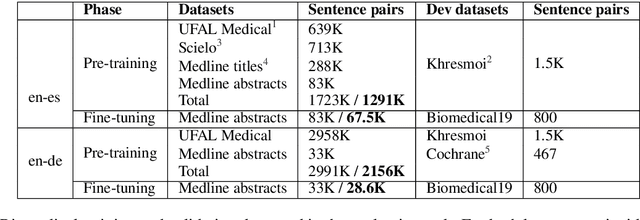
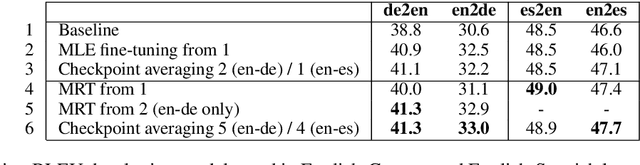
The 2020 WMT Biomedical translation task evaluated Medline abstract translations. This is a small-domain translation task, meaning limited relevant training data with very distinct style and vocabulary. Models trained on such data are susceptible to exposure bias effects, particularly when training sentence pairs are imperfect translations of each other. This can result in poor behaviour during inference if the model learns to neglect the source sentence. The UNICAM entry addresses this problem during fine-tuning using a robust variant on Minimum Risk Training. We contrast this approach with data-filtering to remove `problem' training examples. Under MRT fine-tuning we obtain good results for both directions of English-German and English-Spanish biomedical translation. In particular we achieve the best English-to-Spanish translation result and second-best Spanish-to-English result, despite using only single models with no ensembling.