 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Adaptive Composition of Quantum Circuit Optimisation Passes
Jan 29, 2026Many quantum software development kits provide a suite of circuit optimisation passes. These passes have been highly optimised and tested in isolation. However, the order in which they are applied is left to the user, or else defined in general-purpose default pass sequences. While general-purpose sequences miss opportunities for optimisation which are particular to individual circuits, designing pass sequences bespoke to particular circuits requires exceptional knowledge about quantum circuit design and optimisation. Here we propose and demonstrate training a reinforcement learning agent to compose optimisation-pass sequences. In particular the agent's action space consists of passes for two-qubit gate count reduction used in default PyTKET pass sequences. For the circuits in our diverse test set, the (mean, median) fraction of two-qubit gates removed by the agent is $(57.7\%, \ 56.7 \%)$, compared to $(41.8 \%, \ 50.0 \%)$ for the next best default pass sequence.
Deep Learning Approaches to Quantum Error Mitigation
Jan 20, 2026We present a systematic investigation of deep learning methods applied to quantum error mitigation of noisy output probability distributions from measured quantum circuits. We compare different architectures, from fully connected neural networks to transformers, and we test different design/training modalities, identifying sequence-to-sequence, attention-based models as the most effective on our datasets. These models consistently produce mitigated distributions that are closer to the ideal outputs when tested on both simulated and real device data obtained from IBM superconducting quantum processing units (QPU) up to five qubits. Across several different circuit depths, our approach outperforms other baseline error mitigation techniques. We perform a series of ablation studies to examine: how different input features (circuit, device properties, noisy output statistics) affect performance; cross-dataset generalization across circuit families; and transfer learning to a different IBM QPU. We observe that generalization performance across similar devices with the same architecture works effectively, without needing to fully retrain models.
The Born Supremacy: Quantum Advantage and Training of an Ising Born Machine
Apr 03, 2019
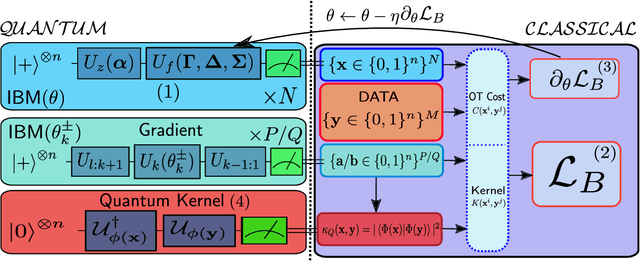
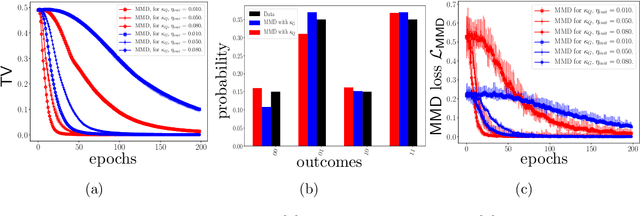
The search for an application of near-term quantum devices is widespread. Quantum Machine Learning is touted as a potential utilisation of such devices, particularly those which are out of the reach of the simulation capabilities of classical computers. In this work, we propose a generative Quantum Machine Learning Model, called the Ising Born Machine (IBM), which we show cannot, in the worst case, and up to suitable notions of error, be simulated efficiently by a classical device. We also show this holds for all the circuit families encountered during training. In particular, we explore quantum circuit learning using non-universal circuits derived from Ising Model Hamiltonians, which are implementable on near term quantum devices. We propose two novel training methods for the IBM by utilising the Stein Discrepancy and the Sinkhorn Divergence cost functions. We show numerically, both using a simulator within Rigetti's Forest platform and on the Aspen-1 16Q chip, that the cost functions we suggest outperform the more commonly used Maximum Mean Discrepancy (MMD) for differentiable training. We also propose an improvement to the MMD by proposing a novel utilisation of quantum kernels which we demonstrate provides improvements over its classical counterpart. We discuss the potential of these methods to learn `hard' quantum distributions, a feat which would demonstrate the advantage of quantum over classical computers, and provide the first formal definitions for what we call `Quantum Learning Supremacy'. Finally, we propose a novel view on the area of quantum circuit compilation by using the IBM to `mimic' target quantum circuits using classical output data only.