 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic trace estimation with tensor train random vectors
Jun 14, 2026Stochastic trace estimation is a standard tool for approximating the trace of a large-scale matrix available only through matrix-vector products. However, in tensor-structured settings, unstructured Gaussian or Rademacher test vectors may be prohibitively expensive to store and compute with, while cheaper rank-one tensor-product vectors can require sample complexities that grow exponentially with the tensor order. This work studies Gaussian random tensor train vectors as a structured alternative for stochastic trace estimation. We show that, with a suitable choice of the tensor train rank, random tensor train vectors recover dimension-independent guarantees for the Girard--Hutchinson estimator. In particular, a median-of-means variant with tensor train rank $r \geq d-1$ achieves the same dependence on the accuracy $\varepsilon$ and failure probability $δ$ as the classical estimator based on unstructured Gaussian vectors. We further prove an oblivious subspace injection result for sketches formed from independent Gaussian random tensor train vectors: tensor train rank $r\geq d-1$ and $\mathcal{O}(\varepsilon^{-2}(k+\log(1/δ)))$ samples suffice for a $k$-dimensional target subspace. Finally, we investigate the use of such sketches within the Nyström++ framework. We show that the resulting estimator can achieve the desired $\mathcal{O}(\varepsilon^{-1})$ sample complexity under an additional spectral-tail condition. These results provide clarififcation on both the potential and the limitations of random tensor train vectors in stochastic trace estimation.
Certified and fast computations with shallow covariance kernels
Jan 30, 2020


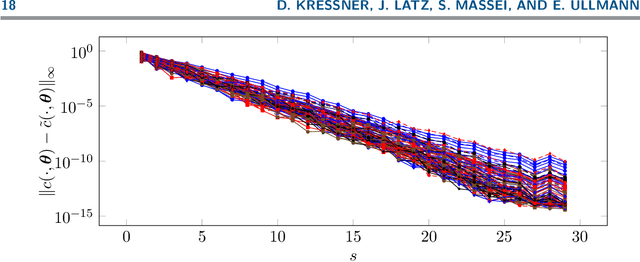
Many techniques for data science and uncertainty quantification demand efficient tools to handle Gaussian random fields, which are defined in terms of their mean functions and covariance operators. Recently, parameterized Gaussian random fields have gained increased attention, due to their higher degree of flexibility. However, especially if the random field is parameterized through its covariance operator, classical random field discretization techniques fail or become inefficient. In this work we introduce and analyze a new and certified algorithm for the low-rank approximation of a parameterized family of covariance operators which represents an extension of the adaptive cross approximation method for symmetric positive definite matrices. The algorithm relies on an affine linear expansion of the covariance operator with respect to the parameters, which needs to be computed in a preprocessing step using, e.g., the empirical interpolation method. We discuss and test our new approach for isotropic covariance kernels, such as Mat\'ern kernels. The numerical results demonstrate the advantages of our approach in terms of computational time and confirm that the proposed algorithm provides the basis of a fast sampling procedure for parameter dependent Gaussian random fields.
Learning heat diffusion graphs
Nov 04, 2016
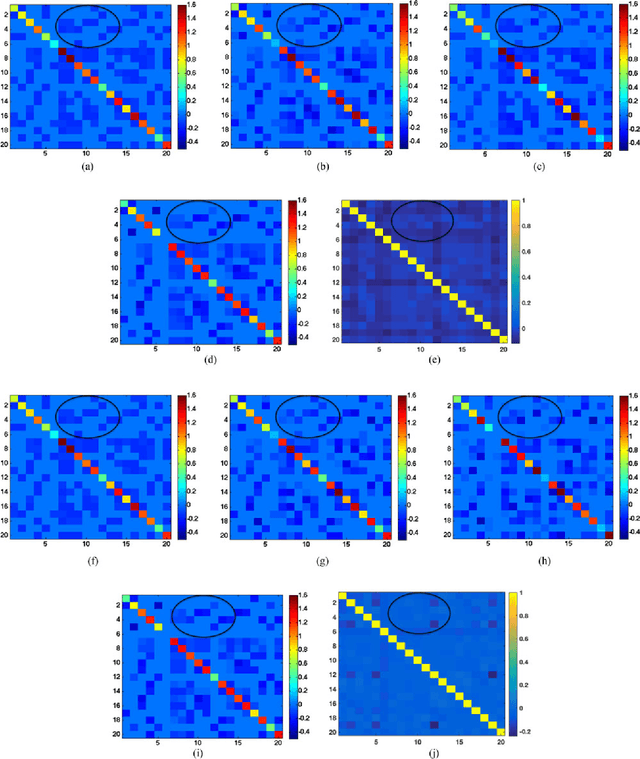
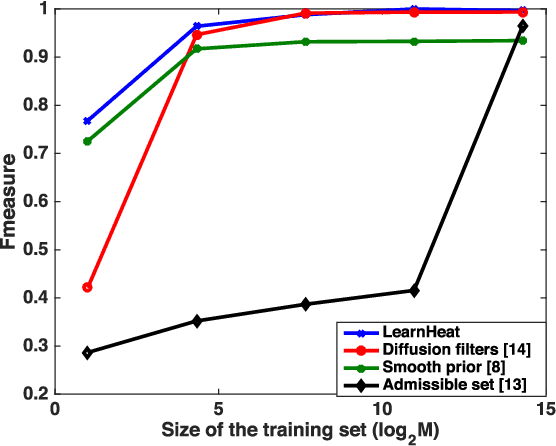
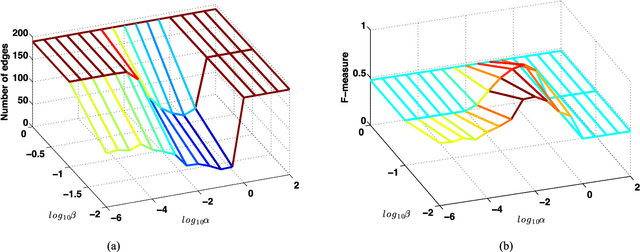
Effective information analysis generally boils down to properly identifying the structure or geometry of the data, which is often represented by a graph. In some applications, this structure may be partly determined by design constraints or pre-determined sensing arrangements, like in road transportation networks for example. In general though, the data structure is not readily available and becomes pretty difficult to define. In particular, the global smoothness assumptions, that most of the existing works adopt, are often too general and unable to properly capture localized properties of data. In this paper, we go beyond this classical data model and rather propose to represent information as a sparse combination of localized functions that live on a data structure represented by a graph. Based on this model, we focus on the problem of inferring the connectivity that best explains the data samples at different vertices of a graph that is a priori unknown. We concentrate on the case where the observed data is actually the sum of heat diffusion processes, which is a quite common model for data on networks or other irregular structures. We cast a new graph learning problem and solve it with an efficient nonconvex optimization algorithm. Experiments on both synthetic and real world data finally illustrate the benefits of the proposed graph learning framework and confirm that the data structure can be efficiently learned from data observations only. We believe that our algorithm will help solving key questions in diverse application domains such as social and biological network analysis where it is crucial to unveil proper geometry for data understanding and inference.