 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA model for efficient dynamical ranking in networks
Jul 25, 2023



We present a physics-inspired method for inferring dynamic rankings in directed temporal networks - networks in which each directed and timestamped edge reflects the outcome and timing of a pairwise interaction. The inferred ranking of each node is real-valued and varies in time as each new edge, encoding an outcome like a win or loss, raises or lowers the node's estimated strength or prestige, as is often observed in real scenarios including sequences of games, tournaments, or interactions in animal hierarchies. Our method works by solving a linear system of equations and requires only one parameter to be tuned. As a result, the corresponding algorithm is scalable and efficient. We test our method by evaluating its ability to predict interactions (edges' existence) and their outcomes (edges' directions) in a variety of applications, including both synthetic and real data. Our analysis shows that in many cases our method's performance is better than existing methods for predicting dynamic rankings and interaction outcomes.
Community Detection in Bipartite Networks with Stochastic Blockmodels
Jan 22, 2020


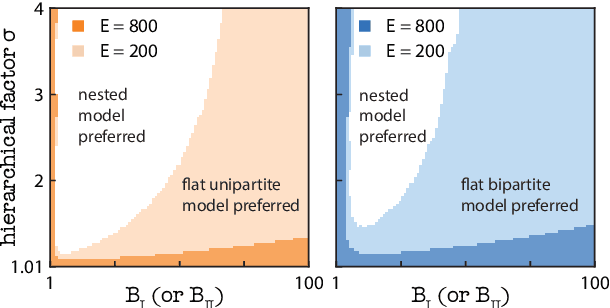
In bipartite networks, community structures are restricted to being disassortative, in that nodes of one type are grouped according to common patterns of connection with nodes of the other type. This makes the stochastic block model (SBM), a highly flexible generative model for networks with block structure, an intuitive choice for bipartite community detection. However, typical formulations of the SBM do not make use of the special structure of bipartite networks. In this work, we introduce a Bayesian nonparametric formulation of the SBM and a corresponding algorithm to efficiently find communities in bipartite networks without overfitting. The biSBM improves community detection results over general SBMs when data are noisy, improves the model resolution limit by a factor of $\sqrt{2}$, and expands our understanding of the complicated optimization landscape associated with community detection tasks. A direct comparison of certain terms of the prior distributions in the biSBM and a related high-resolution hierarchical SBM also reveals a counterintuitive regime of community detection problems, populated by smaller and sparser networks, where non-hierarchical models outperform their more flexible counterpart.
The ground truth about metadata and community detection in networks
May 03, 2017Across many scientific domains, there is a common need to automatically extract a simplified view or coarse-graining of how a complex system's components interact. This general task is called community detection in networks and is analogous to searching for clusters in independent vector data. It is common to evaluate the performance of community detection algorithms by their ability to find so-called "ground truth" communities. This works well in synthetic networks with planted communities because such networks' links are formed explicitly based on those known communities. However, there are no planted communities in real world networks. Instead, it is standard practice to treat some observed discrete-valued node attributes, or metadata, as ground truth. Here, we show that metadata are not the same as ground truth, and that treating them as such induces severe theoretical and practical problems. We prove that no algorithm can uniquely solve community detection, and we prove a general No Free Lunch theorem for community detection, which implies that there can be no algorithm that is optimal for all possible community detection tasks. However, community detection remains a powerful tool and node metadata still have value so a careful exploration of their relationship with network structure can yield insights of genuine worth. We illustrate this point by introducing two statistical techniques that can quantify the relationship between metadata and community structure for a broad class of models. We demonstrate these techniques using both synthetic and real-world networks, and for multiple types of metadata and community structure.
* 27 pages, 10 figures, 11 tables
Efficiently inferring community structure in bipartite networks
Jul 10, 2014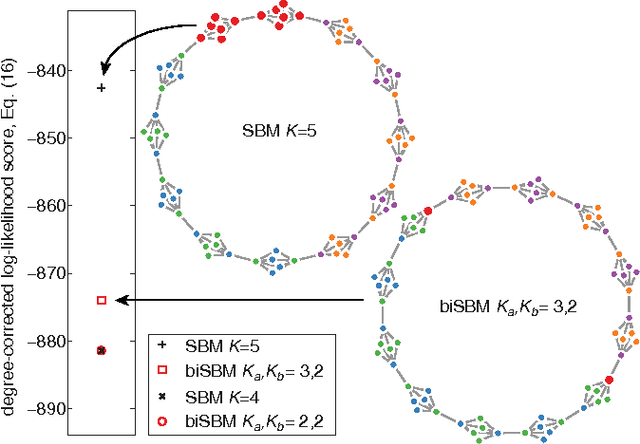
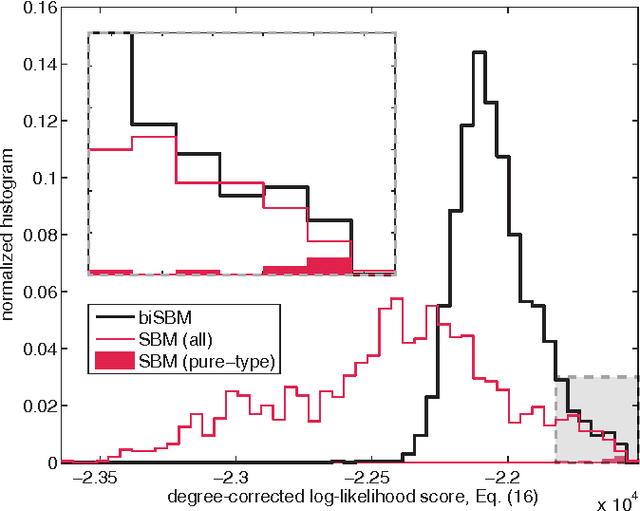
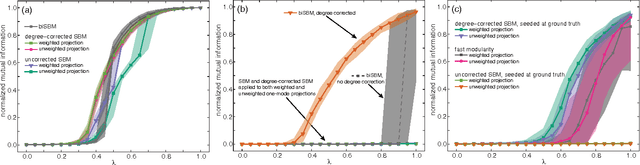
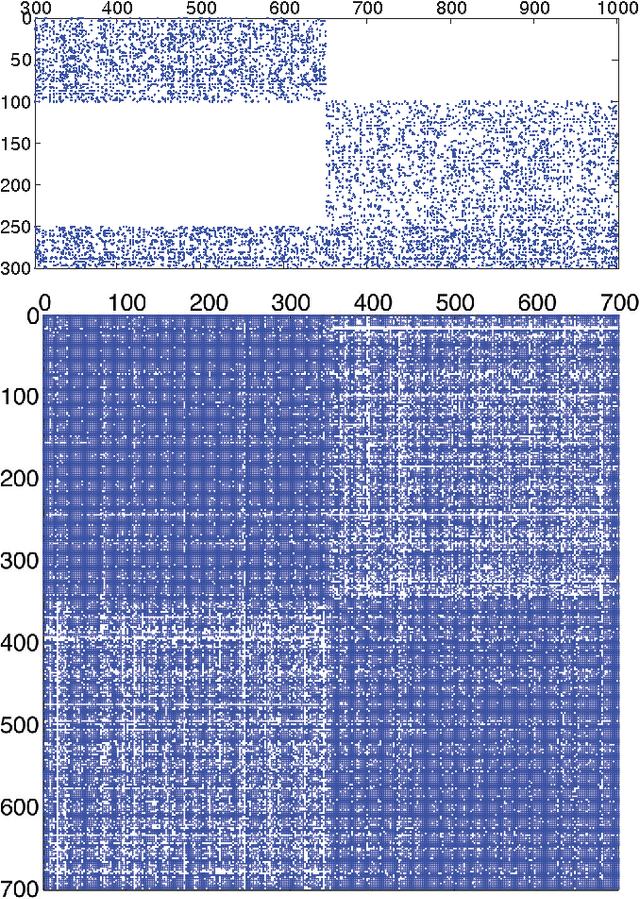
Bipartite networks are a common type of network data in which there are two types of vertices, and only vertices of different types can be connected. While bipartite networks exhibit community structure like their unipartite counterparts, existing approaches to bipartite community detection have drawbacks, including implicit parameter choices, loss of information through one-mode projections, and lack of interpretability. Here we solve the community detection problem for bipartite networks by formulating a bipartite stochastic block model, which explicitly includes vertex type information and may be trivially extended to $k$-partite networks. This bipartite stochastic block model yields a projection-free and statistically principled method for community detection that makes clear assumptions and parameter choices and yields interpretable results. We demonstrate this model's ability to efficiently and accurately find community structure in synthetic bipartite networks with known structure and in real-world bipartite networks with unknown structure, and we characterize its performance in practical contexts.
* 12 pages, 9 figures