 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Hierarchical Attention for 3D Point Cloud Analysis
Aug 07, 2022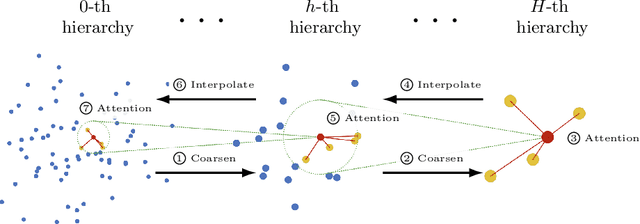
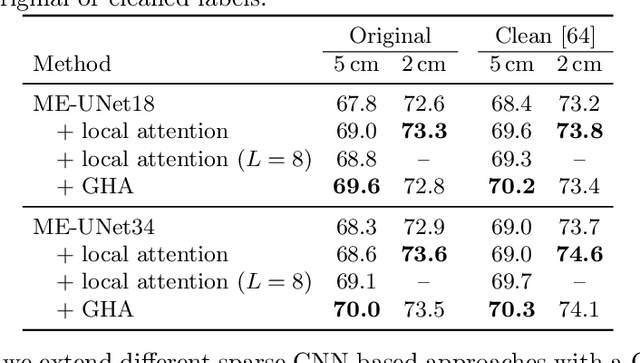
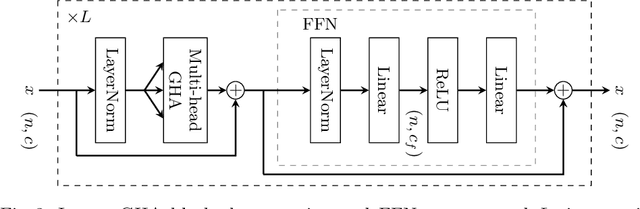
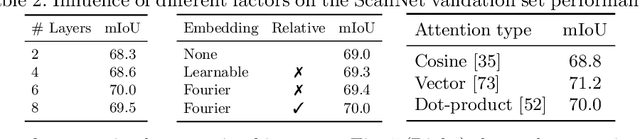
We propose a new attention mechanism, called Global Hierarchical Attention (GHA), for 3D point cloud analysis. GHA approximates the regular global dot-product attention via a series of coarsening and interpolation operations over multiple hierarchy levels. The advantage of GHA is two-fold. First, it has linear complexity with respect to the number of points, enabling the processing of large point clouds. Second, GHA inherently possesses the inductive bias to focus on spatially close points, while retaining the global connectivity among all points. Combined with a feedforward network, GHA can be inserted into many existing network architectures. We experiment with multiple baseline networks and show that adding GHA consistently improves performance across different tasks and datasets. For the task of semantic segmentation, GHA gives a +1.7% mIoU increase to the MinkowskiEngine baseline on ScanNet. For the 3D object detection task, GHA improves the CenterPoint baseline by +0.5% mAP on the nuScenes dataset, and the 3DETR baseline by +2.1% mAP25 and +1.5% mAP50 on ScanNet.
Pedestrian-Robot Interactions on Autonomous Crowd Navigation: Reactive Control Methods and Evaluation Metrics
Aug 03, 2022
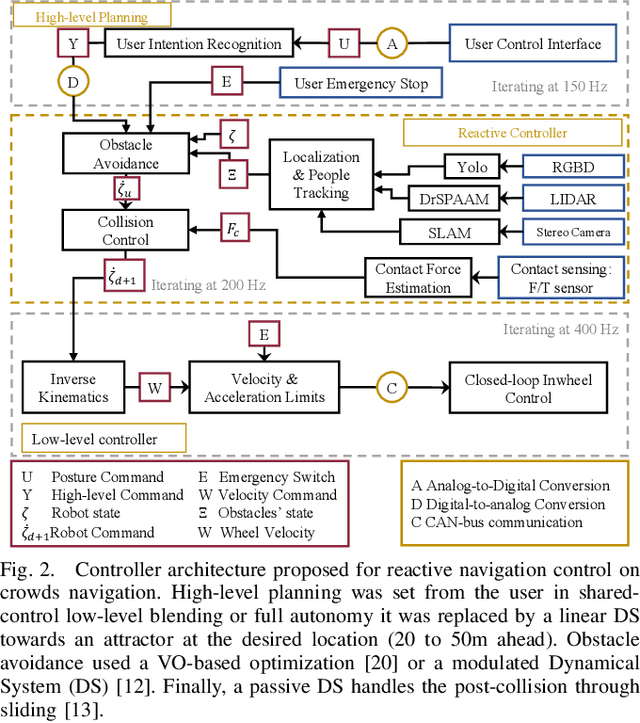
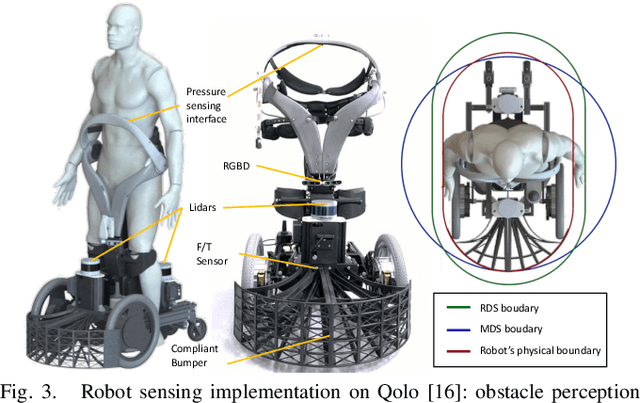
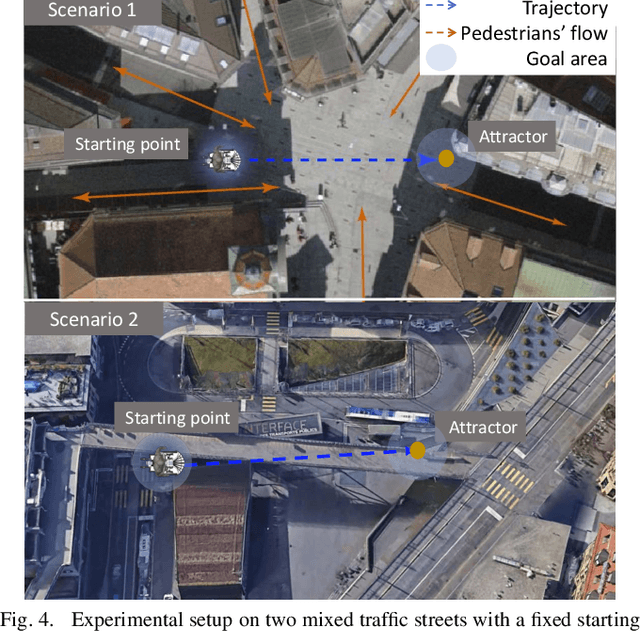
Autonomous navigation in highly populated areas remains a challenging task for robots because of the difficulty in guaranteeing safe interactions with pedestrians in unstructured situations. In this work, we present a crowd navigation control framework that delivers continuous obstacle avoidance and post-contact control evaluated on an autonomous personal mobility vehicle. We propose evaluation metrics for accounting efficiency, controller response and crowd interactions in natural crowds. We report the results of over 110 trials in different crowd types: sparse, flows, and mixed traffic, with low- (< 0.15 ppsm), mid- (< 0.65 ppsm), and high- (< 1 ppsm) pedestrian densities. We present comparative results between two low-level obstacle avoidance methods and a baseline of shared control. Results show a 10% drop in relative time to goal on the highest density tests, and no other efficiency metric decrease. Moreover, autonomous navigation showed to be comparable to shared-control navigation with a lower relative jerk and significantly higher fluency in commands indicating high compatibility with the crowd. We conclude that the reactive controller fulfils a necessary task of fast and continuous adaptation to crowd navigation, and it should be coupled with high-level planners for environmental and situational awareness.
* \c{opyright}IEEE All rights reserved. IEEE-IROS-2022, Oct.23-27. Kyoto, Japan
Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud
Jul 03, 2021In this preliminary work we attempt to apply submanifold sparse convolution to the task of 3D person detection. In particular, we present Person-MinkUNet, a single-stage 3D person detection network based on Minkowski Engine with U-Net architecture. The network achieves a 76.4% average precision (AP) on the JRDB 3D detection benchmark.
Domain and Modality Gaps for LiDAR-based Person Detection on Mobile Robots
Jun 21, 2021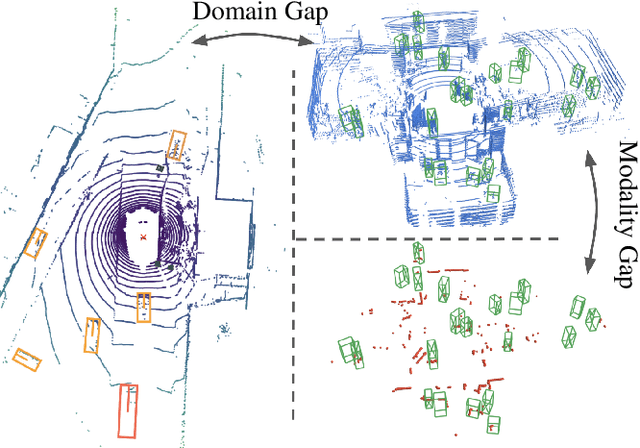
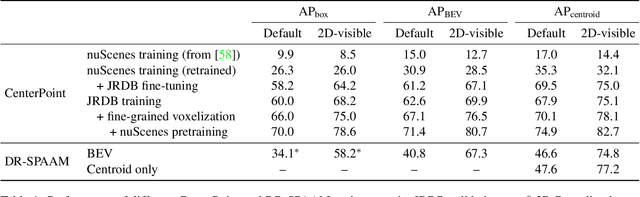
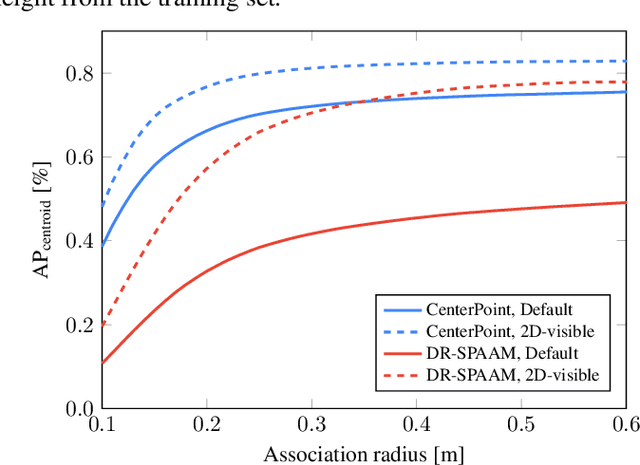

Person detection is a crucial task for mobile robots navigating in human-populated environments and LiDAR sensors are promising for this task, given their accurate depth measurements and large field of view. This paper studies existing LiDAR-based person detectors with a particular focus on mobile robot scenarios (e.g. service robot or social robot), where persons are observed more frequently and in much closer ranges, compared to the driving scenarios. We conduct a series of experiments, using the recently released JackRabbot dataset and the state-of-the-art detectors based on 3D or 2D LiDAR sensors (CenterPoint and DR-SPAAM respectively). These experiments revolve around the domain gap between driving and mobile robot scenarios, as well as the modality gap between 3D and 2D LiDAR sensors. For the domain gap, we aim to understand if detectors pretrained on driving datasets can achieve good performance on the mobile robot scenarios, for which there are currently no trained models readily available. For the modality gap, we compare detectors that use 3D or 2D LiDAR, from various aspects, including performance, runtime, localization accuracy, robustness to range and crowdedness. The results from our experiments provide practical insights into LiDAR-based person detection and facilitate informed decisions for relevant mobile robot designs and applications.
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
Dec 16, 2020



Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self-supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
DR-SPAAM: A Spatial-Attention and Auto-regressive Model for Person Detection in 2D Range Data
Apr 29, 2020
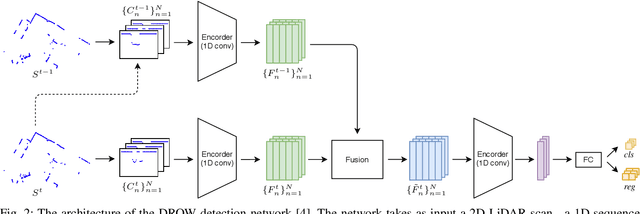

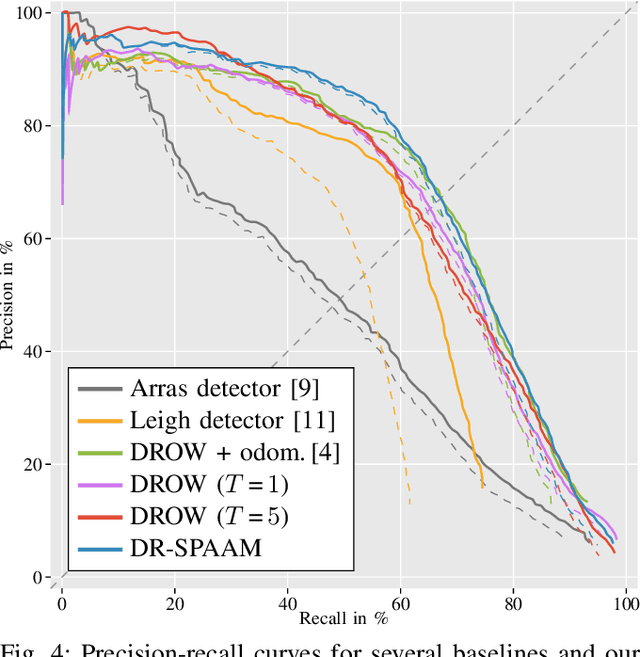
Detecting persons using a 2D LiDAR is a challenging task due to the low information content of 2D range data. To alleviate the problem caused by the sparsity of the LiDAR points, current state-of-the-art methods fuse multiple previous scans and perform detection using the combined scans. The downside of such a backward looking fusion is that all the scans need to be aligned explicitly, and the necessary alignment operation makes the whole pipeline more expensive -- often too expensive for real-world applications. In this paper, we propose a person detection network which uses an alternative strategy to combine scans obtained at different times. Our method, Distance Robust SPatial Attention and Auto-regressive Model (DR-SPAAM), follows a forward looking paradigm. It keeps the intermediate features from the backbone network as a template and recurrently updates the template when a new scan becomes available. The updated feature template is in turn used for detecting persons currently in the scene. On the DROW dataset, our method outperforms the existing state-of-the-art, while being approximately four times faster, running at 87.2 FPS on a laptop with a dedicated GPU and at 22.6 FPS on an NVIDIA Jetson AGX embedded GPU. We release our code in PyTorch and a ROS node including pre-trained models.