 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction Grammar and Language Models
Sep 04, 2023
Recent progress in deep learning and natural language processing has given rise to powerful models that are primarily trained on a cloze-like task and show some evidence of having access to substantial linguistic information, including some constructional knowledge. This groundbreaking discovery presents an exciting opportunity for a synergistic relationship between computational methods and Construction Grammar research. In this chapter, we explore three distinct approaches to the interplay between computational methods and Construction Grammar: (i) computational methods for text analysis, (ii) computational Construction Grammar, and (iii) deep learning models, with a particular focus on language models. We touch upon the first two approaches as a contextual foundation for the use of computational methods before providing an accessible, yet comprehensive overview of deep learning models, which also addresses reservations construction grammarians may have. Additionally, we delve into experiments that explore the emergence of constructionally relevant information within these models while also examining the aspects of Construction Grammar that may pose challenges for these models. This chapter aims to foster collaboration between researchers in the fields of natural language processing and Construction Grammar. By doing so, we hope to pave the way for new insights and advancements in both these fields.
Abstraction not Memory: BERT and the English Article System
Jun 08, 2022
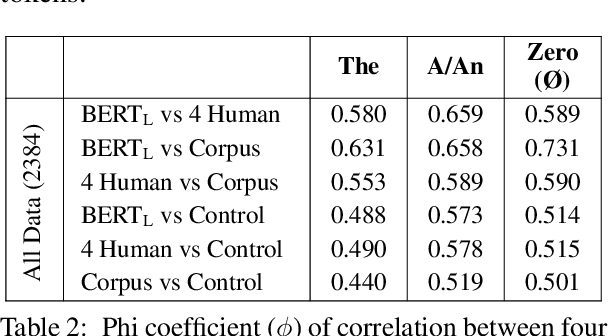

Article prediction is a task that has long defied accurate linguistic description. As such, this task is ideally suited to evaluate models on their ability to emulate native-speaker intuition. To this end, we compare the performance of native English speakers and pre-trained models on the task of article prediction set up as a three way choice (a/an, the, zero). Our experiments with BERT show that BERT outperforms humans on this task across all articles. In particular, BERT is far superior to humans at detecting the zero article, possibly because we insert them using rules that the deep neural model can easily pick up. More interestingly, we find that BERT tends to agree more with annotators than with the corpus when inter-annotator agreement is high but switches to agreeing more with the corpus as inter-annotator agreement drops. We contend that this alignment with annotators, despite being trained on the corpus, suggests that BERT is not memorising article use, but captures a high level generalisation of article use akin to human intuition.
A learning perspective on the emergence of abstractions: the curious case of phonemes
Dec 17, 2020
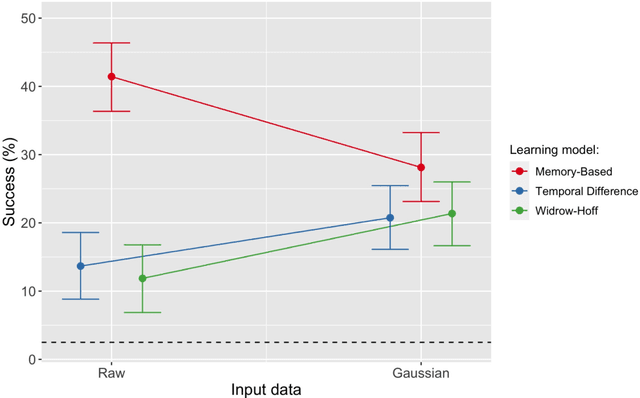


In the present paper we use a range of modeling techniques to investigate whether an abstract phone could emerge from exposure to speech sounds. We test two opposing principles regarding the development of language knowledge in linguistically untrained language users: Memory-Based Learning (MBL) and Error-Correction Learning (ECL). A process of generalization underlies the abstractions linguists operate with, and we probed whether MBL and ECL could give rise to a type of language knowledge that resembles linguistic abstractions. Each model was presented with a significant amount of pre-processed speech produced by one speaker. We assessed the consistency or stability of what the models have learned and their ability to give rise to abstract categories. Both types of models fare differently with regard to these tests. We show that ECL learning models can learn abstractions and that at least part of the phone inventory can be reliably identified from the input.
CxGBERT: BERT meets Construction Grammar
Nov 09, 2020
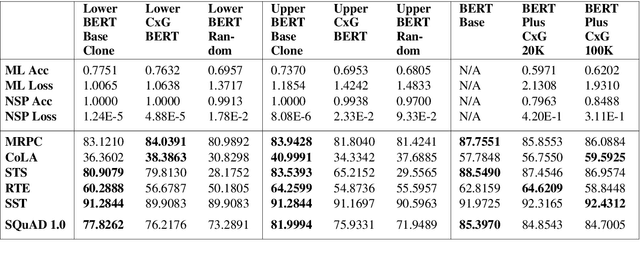
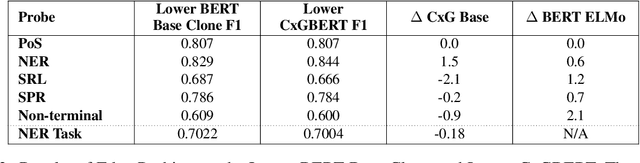
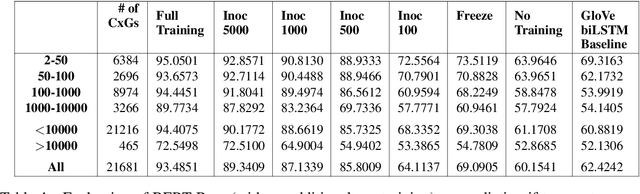
While lexico-semantic elements no doubt capture a large amount of linguistic information, it has been argued that they do not capture all information contained in text. This assumption is central to constructionist approaches to language which argue that language consists of constructions, learned pairings of a form and a function or meaning that are either frequent or have a meaning that cannot be predicted from its component parts. BERT's training objectives give it access to a tremendous amount of lexico-semantic information, and while BERTology has shown that BERT captures certain important linguistic dimensions, there have been no studies exploring the extent to which BERT might have access to constructional information. In this work we design several probes and conduct extensive experiments to answer this question. Our results allow us to conclude that BERT does indeed have access to a significant amount of information, much of which linguists typically call constructional information. The impact of this observation is potentially far-reaching as it provides insights into what deep learning methods learn from text, while also showing that information contained in constructions is redundantly encoded in lexico-semantics.
Keeping it simple: Implementation and performance of the proto-principle of adaptation and learning in the language sciences
Mar 08, 2020
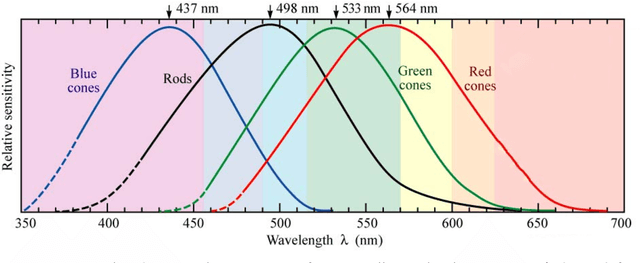
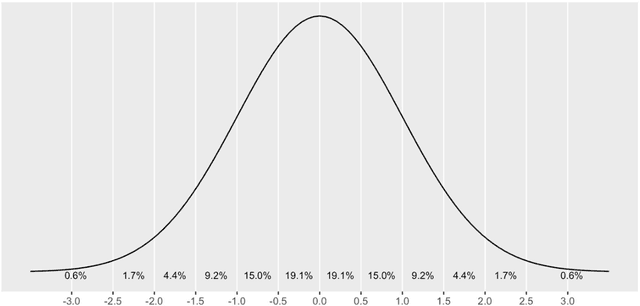
In this paper we present the Widrow-Hoff rule and its applications to language data. After contextualizing the rule historically and placing it in the chain of neurally inspired artificial learning models, we explain its rationale and implementational considerations. Using a number of case studies we illustrate how the Widrow-Hoff rule offers unexpected opportunities for the computational simulation of a range of language phenomena that make it possible to approach old problems from a novel perspective.