 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically constrained unfolded multi-dimensional OMP for large MIMO systems
Jan 15, 2026Sparse recovery methods are essential for channel estimation and localization in modern communication systems, but their reliability relies on accurate physical models, which are rarely perfectly known. Their computational complexity also grows rapidly with the dictionary dimensions in large MIMO systems. In this paper, we propose MOMPnet, a novel unfolded sparse recovery framework that addresses both the reliability and complexity challenges of traditional methods. By integrating deep unfolding with data-driven dictionary learning, MOMPnet mitigates hardware impairments while preserving interpretability. Instead of a single large dictionary, multiple smaller, independent dictionaries are employed, enabling a low-complexity multidimensional Orthogonal Matching Pursuit algorithm. The proposed unfolded network is evaluated on realistic channel data against multiple baselines, demonstrating its strong performance and potential.
El0ps: An Exact L0-regularized Problems Solver
Jun 04, 2025This paper presents El0ps, a Python toolbox providing several utilities to handle L0-regularized problems related to applications in machine learning, statistics, and signal processing, among other fields. In contrast to existing toolboxes, El0ps allows users to define custom instances of these problems through a flexible framework, provides a dedicated solver achieving state-of-the-art performance, and offers several built-in machine learning pipelines. Our aim with El0ps is to provide a comprehensive tool which opens new perspectives for the integration of L0-regularized problems in practical applications.
A Generic Branch-and-Bound Algorithm for $\ell_0$-Penalized Problems with Supplementary Material
Jun 04, 2025We present a generic Branch-and-Bound procedure designed to solve L0-penalized optimization problems. Existing approaches primarily focus on quadratic losses and construct relaxations using "Big-M" constraints and/or L2-norm penalties. In contrast, our method accommodates a broader class of loss functions and allows greater flexibility in relaxation design through a general penalty term, encompassing existing techniques as special cases. We establish theoretical results ensuring that all key quantities required for the Branch-and-Bound implementation admit closed-form expressions under the general blanket assumptions considered in our work. Leveraging this framework, we introduce El0ps, an open-source Python solver with a plug-and-play workflow that enables user-defined losses and penalties in L0-penalized problems. Through extensive numerical experiments, we demonstrate that El0ps achieves state-of-the-art performance on classical instances and extends computational feasibility to previously intractable ones.
Model-based learning for joint channel estimationand hybrid MIMO precoding
May 07, 2025Hybrid precoding is a key ingredient of cost-effective massive multiple-input multiple-output transceivers. However, setting jointly digital and analog precoders to optimally serve multiple users is a difficult optimization problem. Moreover, it relies heavily on precise knowledge of the channels, which is difficult to obtain, especially when considering realistic systems comprising hardware impairments. In this paper, a joint channel estimation and hybrid precoding method is proposed, which consists in an end-to-end architecture taking received pilots as inputs and outputting precoders. The resulting neural network is fully model-based, making it lightweight and interpretable with very few learnable parameters. The channel estimation step is performed using the unfolded matching pursuit algorithm, accounting for imperfect knowledge of the antenna system, while the precoding step is done via unfolded projected gradient ascent. The great potential of the proposed method is empirically demonstrated on realistic synthetic channels.
A New Branch-and-Bound Pruning Framework for $\ell_0$-Regularized Problems
Jun 03, 2024



We consider the resolution of learning problems involving $\ell_0$-regularization via Branch-and-Bound (BnB) algorithms. These methods explore regions of the feasible space of the problem and check whether they do not contain solutions through "pruning tests". In standard implementations, evaluating a pruning test requires to solve a convex optimization problem, which may result in computational bottlenecks. In this paper, we present an alternative to implement pruning tests for some generic family of $\ell_0$-regularized problems. Our proposed procedure allows the simultaneous assessment of several regions and can be embedded in standard BnB implementations with a negligible computational overhead. We show through numerical simulations that our pruning strategy can improve the solving time of BnB procedures by several orders of magnitude for typical problems encountered in machine-learning applications.
One to beat them all: "RYU'' -- a unifying framework for the construction of safe balls
Dec 01, 2023In this paper, we put forth a novel framework (named ``RYU'') for the construction of ``safe'' balls, i.e. regions that provably contain the dual solution of a target optimization problem. We concentrate on the standard setup where the cost function is the sum of two terms: a closed, proper, convex Lipschitz-smooth function and a closed, proper, convex function. The RYU framework is shown to generalize or improve upon all the results proposed in the last decade for the considered family of optimization problems.
Safe peeling for l0-regularized least-squares with supplementary material
Mar 03, 2023We introduce a new methodology dubbed ``safe peeling'' to accelerate the resolution of L0-regularized least-squares problems via a Branch-and-Bound (BnB) algorithm. Our procedure enables to tighten the convex relaxation considered at each node of the BnB decision tree and therefore potentially allows for more aggressive pruning. Numerical simulations show that our proposed methodology leads to significant gains in terms of number of nodes explored and overall solving time.s show that our proposed methodology leads to significant gains in terms of number of nodes explored and overall solving time.
Beyond GAP screening for Lasso by exploiting new dual cutting half-spaces with supplementary material
Mar 02, 2022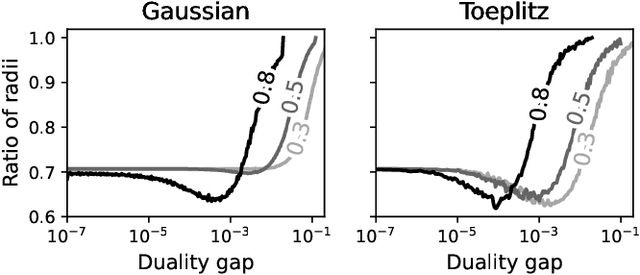
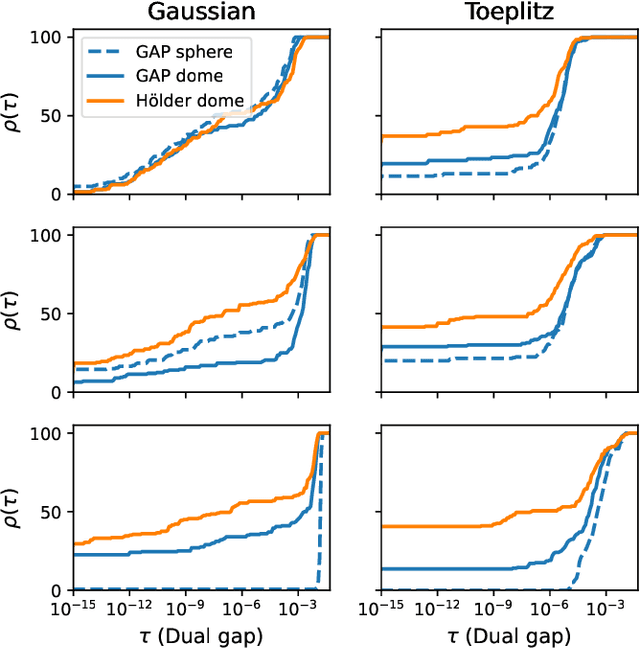
In this paper, we propose a novel safe screening test for Lasso. Our procedure is based on a safe region with a dome geometry and exploits a canonical representation of the set of half-spaces (referred to as "dual cutting half-spaces" in this paper) containing the dual feasible set. The proposed safe region is shown to be always included in the state-of-the-art "GAP Sphere" and "GAP Dome" proposed by Fercoq et al. (and strictly so under very mild conditions) while involving the same computational burden. Numerical experiments confirm that our new dome enables to devise more powerful screening tests than GAP regions and lead to significant acceleration to solve Lasso.
Safe rules for the identification of zeros in the solutions of the SLOPE problem
Oct 22, 2021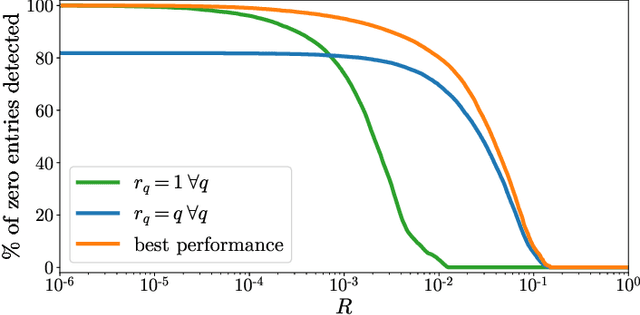
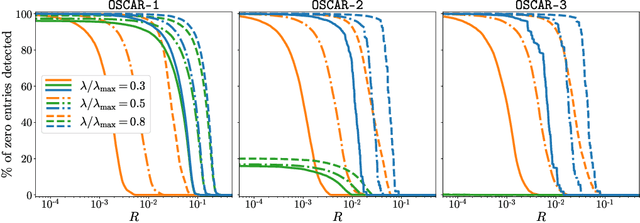
In this paper we propose a methodology to accelerate the resolution of the so-called ``Sorted L-One Penalized Estimation'' (SLOPE) problem. Our method leverages the concept of ``safe screening'', well-studied in the literature for \textit{group-separable} sparsity-inducing norms, and aims at identifying the zeros in the solution of SLOPE. More specifically, we introduce a family of \(n!\) safe screening rules for this problem, where \(n\) is the dimension of the primal variable, and propose a tractable procedure to verify if one of these tests is passed. Our procedure has a complexity \(\mathcal{O}(n\log n + LT)\) where \(T\leq n\) is a problem-dependent constant and \(L\) is the number of zeros identified by the tests. We assess the performance of our proposed method on a numerical benchmark and emphasize that it leads to significant computational savings in many setups.
Node-screening tests for L0-penalized least-squares problem with supplementary material
Oct 14, 2021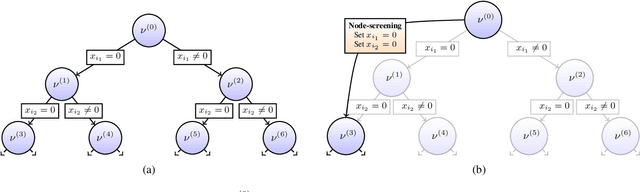
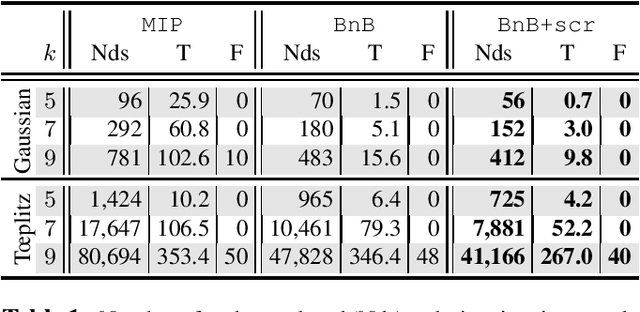
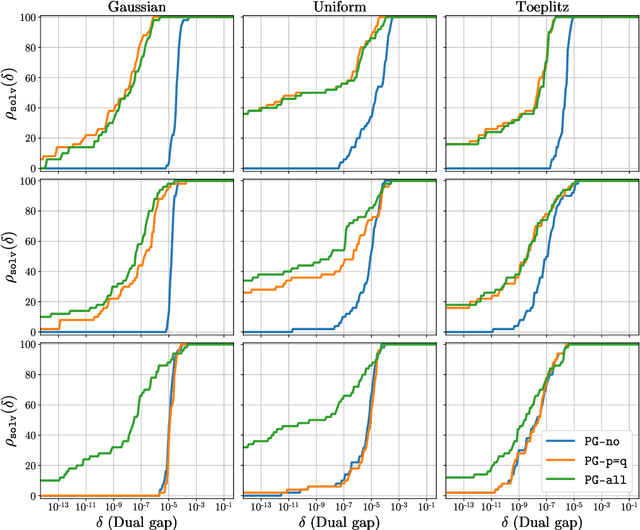
We present a novel screening methodology to safely discard irrelevant nodes within a generic branch-and-bound (BnB) algorithm solving the \(\ell_0\)-penalized least-squares problem. Our contribution is a set of two simple tests to detect sets of feasible vectors that cannot yield optimal solutions. This allows to prune nodes of the BnB exploration tree, thus reducing the overall solution time. One cornerstone of our contribution is a nesting property between tests at different nodes that allows to implement screening at low computational cost. Our work leverages the concept of safe screening, well known for sparsity-inducing convex problems, and some recent advances in this field for \(\ell_0\)-penalized regression problems.