 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed data Deep Gaussian Mixture Model: A clustering model for mixed datasets
Oct 13, 2020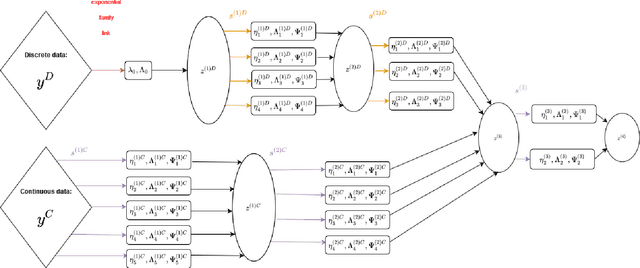
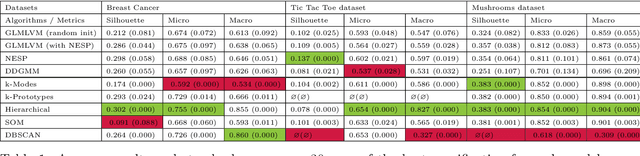
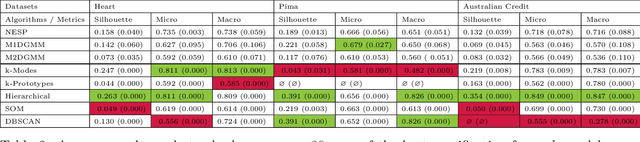
Clustering mixed data presents numerous challenges inherent to the very heterogeneous nature of the variables. Two major difficulties lie in the initialisation of the algorithms and in making variables comparable between types. This work is concerned with these two problems. We introduce a two-heads architecture model-based clustering method called Mixed data Deep Gaussian Mixture Model (MDGMM) that can be viewed as an automatic way to merge the clusterings performed separately on continuous and non continuous data. We also design a new initialisation strategy and a data driven method that selects "on the fly" the best specification of the model and the optimal number of clusters for a given dataset. Besides, our model provides continuous low-dimensional representations of the data which can be a useful tool to visualize mixed datasets. Finally, we validate the performance of our approach comparing its results with state-of-the-art mixed data clustering models over several commonly used datasets
Classifying textual data: shallow, deep and ensemble methods
Feb 18, 2019


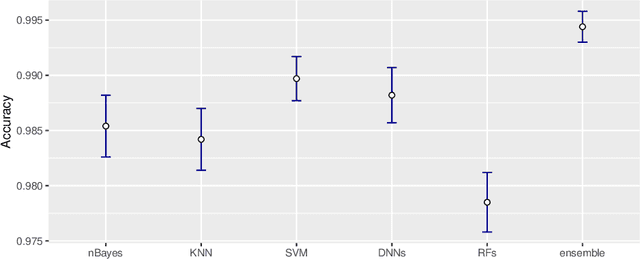
This paper focuses on a comparative evaluation of the most common and modern methods for text classification, including the recent deep learning strategies and ensemble methods. The study is motivated by a challenging real data problem, characterized by high-dimensional and extremely sparse data, deriving from incoming calls to the customer care of an Italian phone company. We will show that deep learning outperforms many classical (shallow) strategies but the combination of shallow and deep learning methods in a unique ensemble classifier may improve the robustness and the accuracy of "single" classification methods.
Going deep in clustering high-dimensional data: deep mixtures of unigrams for uncovering topics in textual data
Feb 18, 2019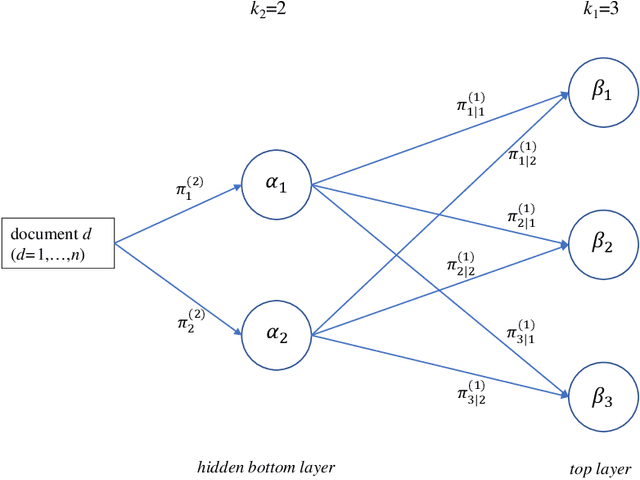



Mixtures of Unigrams (Nigam et al., 2000) are one of the simplest and most efficient tools for clustering textual data, as they assume that documents related to the same topic have similar distributions of terms, naturally described by Multinomials. When the classification task is particularly challenging, such as when the document-term matrix is high-dimensional and extremely sparse, a more composite representation can provide better insight on the grouping structure. In this work, we developed a deep version of mixtures of Unigrams for the unsupervised classification of very short documents with a large number of terms, by allowing for models with further deeper latent layers; the proposal is derived in a Bayesian framework. Simulation studies and real data analysis prove that going deep in clustering such data highly improves the classification accuracy with respect to more `shallow' methods.
Deep Gaussian Mixture Models
Nov 18, 2017



Deep learning is a hierarchical inference method formed by subsequent multiple layers of learning able to more efficiently describe complex relationships. In this work, Deep Gaussian Mixture Models are introduced and discussed. A Deep Gaussian Mixture model (DGMM) is a network of multiple layers of latent variables, where, at each layer, the variables follow a mixture of Gaussian distributions. Thus, the deep mixture model consists of a set of nested mixtures of linear models, which globally provide a nonlinear model able to describe the data in a very flexible way. In order to avoid overparameterized solutions, dimension reduction by factor models can be applied at each layer of the architecture thus resulting in deep mixtures of factor analysers.