 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed data Deep Gaussian Mixture Model: A clustering model for mixed datasets
Paper and Code
Oct 13, 2020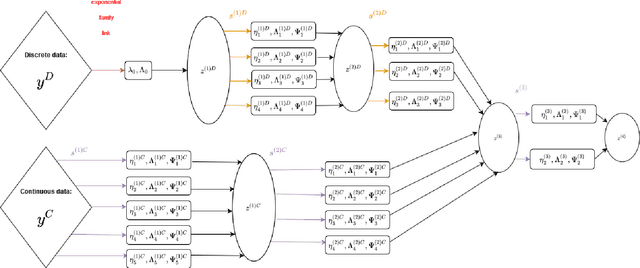
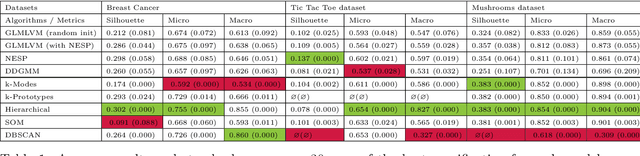
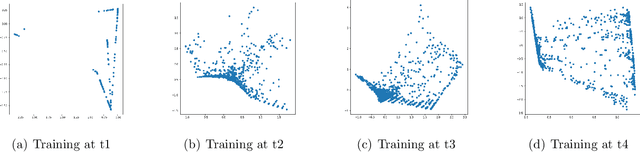
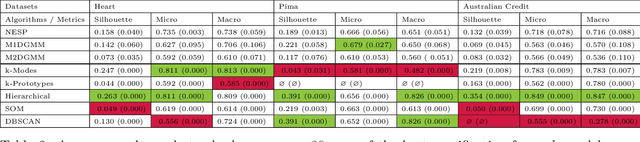
Clustering mixed data presents numerous challenges inherent to the very heterogeneous nature of the variables. Two major difficulties lie in the initialisation of the algorithms and in making variables comparable between types. This work is concerned with these two problems. We introduce a two-heads architecture model-based clustering method called Mixed data Deep Gaussian Mixture Model (MDGMM) that can be viewed as an automatic way to merge the clusterings performed separately on continuous and non continuous data. We also design a new initialisation strategy and a data driven method that selects "on the fly" the best specification of the model and the optimal number of clusters for a given dataset. Besides, our model provides continuous low-dimensional representations of the data which can be a useful tool to visualize mixed datasets. Finally, we validate the performance of our approach comparing its results with state-of-the-art mixed data clustering models over several commonly used datasets