 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing deep in clustering high-dimensional data: deep mixtures of unigrams for uncovering topics in textual data
Paper and Code
Feb 18, 2019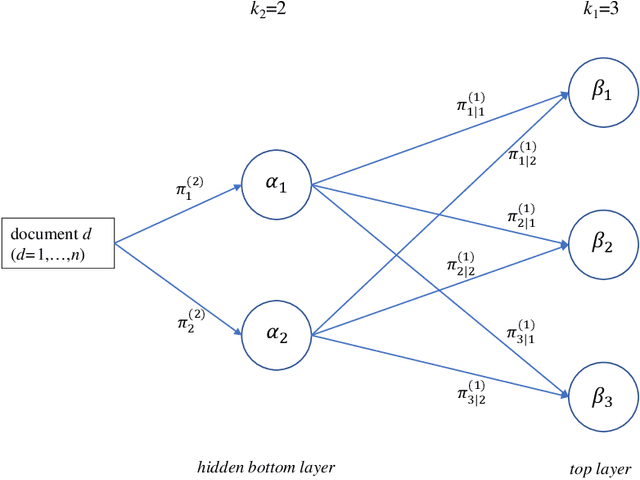



Mixtures of Unigrams (Nigam et al., 2000) are one of the simplest and most efficient tools for clustering textual data, as they assume that documents related to the same topic have similar distributions of terms, naturally described by Multinomials. When the classification task is particularly challenging, such as when the document-term matrix is high-dimensional and extremely sparse, a more composite representation can provide better insight on the grouping structure. In this work, we developed a deep version of mixtures of Unigrams for the unsupervised classification of very short documents with a large number of terms, by allowing for models with further deeper latent layers; the proposal is derived in a Bayesian framework. Simulation studies and real data analysis prove that going deep in clustering such data highly improves the classification accuracy with respect to more `shallow' methods.