 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix sketching for supervised classification with imbalanced classes
Dec 02, 2019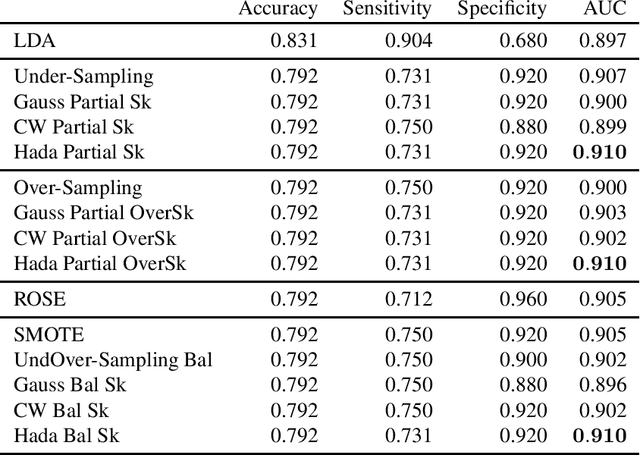
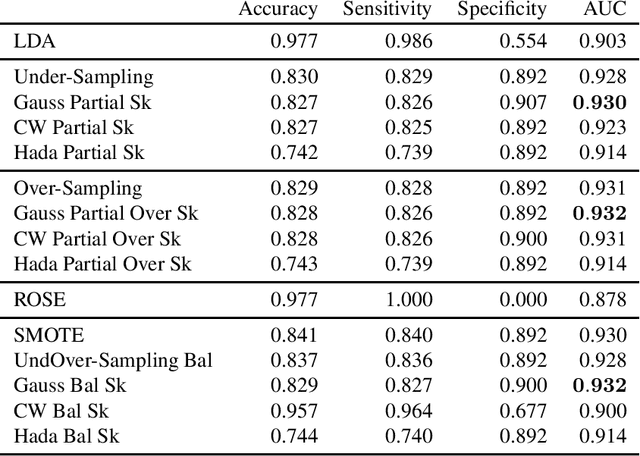
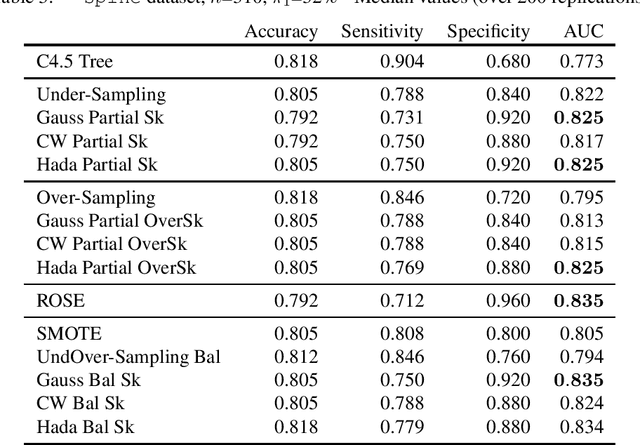
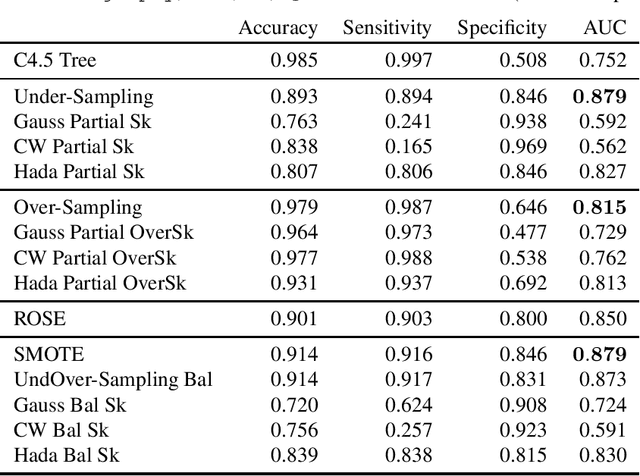
Matrix sketching is a recently developed data compression technique. An input matrix A is efficiently approximated with a smaller matrix B, so that B preserves most of the properties of A up to some guaranteed approximation ratio. In so doing numerical operations on big data sets become faster. Sketching algorithms generally use random projections to compress the original dataset and this stochastic generation process makes them amenable to statistical analysis. The statistical properties of sketching algorithms have been widely studied in the context of multiple linear regression. In this paper we propose matrix sketching as a tool for rebalancing class sizes in supervised classification with imbalanced classes. It is well-known in fact that class imbalance may lead to poor classification performances especially as far as the minority class is concerned.
Classifying textual data: shallow, deep and ensemble methods
Feb 18, 2019


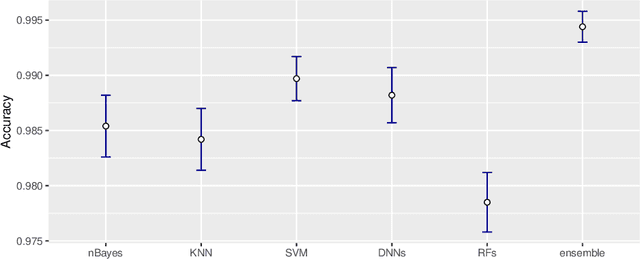
This paper focuses on a comparative evaluation of the most common and modern methods for text classification, including the recent deep learning strategies and ensemble methods. The study is motivated by a challenging real data problem, characterized by high-dimensional and extremely sparse data, deriving from incoming calls to the customer care of an Italian phone company. We will show that deep learning outperforms many classical (shallow) strategies but the combination of shallow and deep learning methods in a unique ensemble classifier may improve the robustness and the accuracy of "single" classification methods.
Going deep in clustering high-dimensional data: deep mixtures of unigrams for uncovering topics in textual data
Feb 18, 2019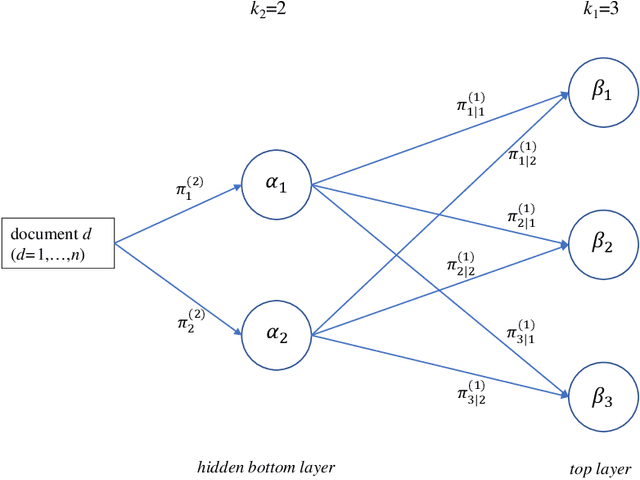



Mixtures of Unigrams (Nigam et al., 2000) are one of the simplest and most efficient tools for clustering textual data, as they assume that documents related to the same topic have similar distributions of terms, naturally described by Multinomials. When the classification task is particularly challenging, such as when the document-term matrix is high-dimensional and extremely sparse, a more composite representation can provide better insight on the grouping structure. In this work, we developed a deep version of mixtures of Unigrams for the unsupervised classification of very short documents with a large number of terms, by allowing for models with further deeper latent layers; the proposal is derived in a Bayesian framework. Simulation studies and real data analysis prove that going deep in clustering such data highly improves the classification accuracy with respect to more `shallow' methods.