 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSORT: A Systematically Optimized Ranking Transformer for Industrial-scale Recommenders
Mar 04, 2026While Transformers have achieved remarkable success in LLMs through superior scalability, their application in industrial-scale ranking models remains nascent, hindered by the challenges of high feature sparsity and low label density. In this paper, we propose SORT (Systematically Optimized Ranking Transformer), a scalable model designed to bridge the gap between Transformers and industrial-scale ranking models. We address the high feature sparsity and low label density challenges through a series of optimizations, including request-centric sample organization, local attention, query pruning and generative pre-training. Furthermore, we introduce a suite of refinements to the tokenization, multi-head attention (MHA), and feed-forward network (FFN) modules, which collectively stabilize the training process and enlarge the model capacity. To maximize hardware efficiency, we optimize our training system to elevate the model FLOPs utilization (MFU) to 22%. Extensive experiments demonstrate that SORT outperforms strong baselines and exhibits excellent scalability across data size, model size and sequence length, while remaining flexible at integrating diverse features. Finally, online A/B testing in large-scale e-commerce scenarios confirms that SORT achieves significant gains in key business metrics, including orders (+6.35%), buyers (+5.97%) and GMV (+5.47%), while simultaneously halving latency (-44.67%) and doubling throughput (+121.33%).
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
Aug 16, 2021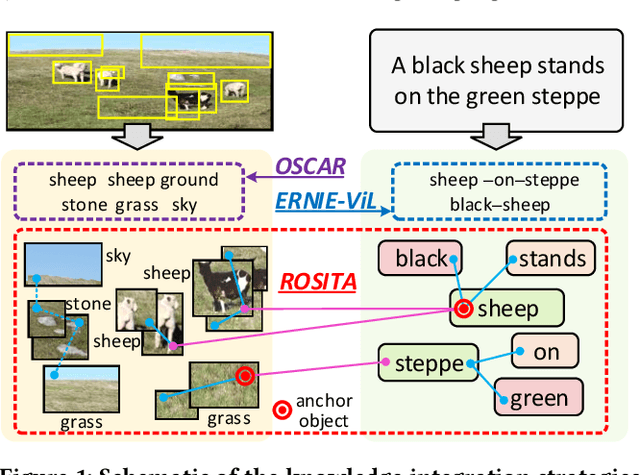
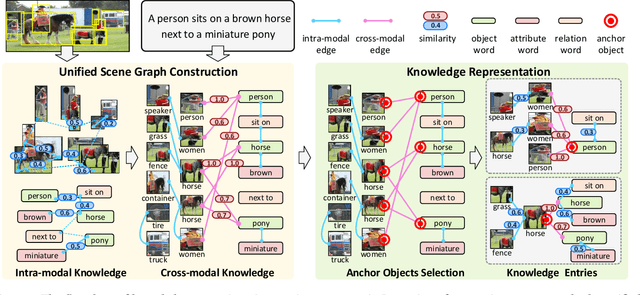
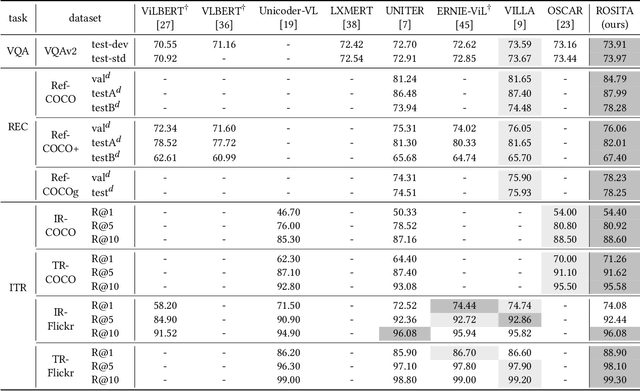
Vision-and-language pretraining (VLP) aims to learn generic multimodal representations from massive image-text pairs. While various successful attempts have been proposed, learning fine-grained semantic alignments between image-text pairs plays a key role in their approaches. Nevertheless, most existing VLP approaches have not fully utilized the intrinsic knowledge within the image-text pairs, which limits the effectiveness of the learned alignments and further restricts the performance of their models. To this end, we introduce a new VLP method called ROSITA, which integrates the cross- and intra-modal knowledge in a unified scene graph to enhance the semantic alignments. Specifically, we introduce a novel structural knowledge masking (SKM) strategy to use the scene graph structure as a priori to perform masked language (region) modeling, which enhances the semantic alignments by eliminating the interference information within and across modalities. Extensive ablation studies and comprehensive analysis verifies the effectiveness of ROSITA in semantic alignments. Pretrained with both in-domain and out-of-domain datasets, ROSITA significantly outperforms existing state-of-the-art VLP methods on three typical vision-and-language tasks over six benchmark datasets.
Semi-Autoregressive Neural Machine Translation
Oct 27, 2018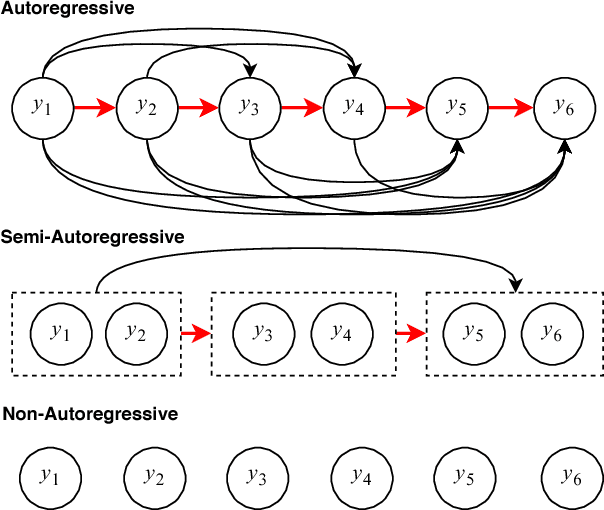
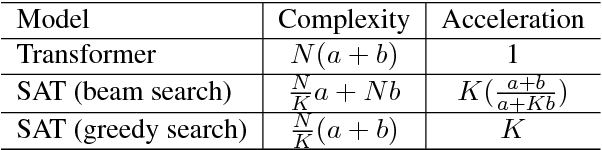

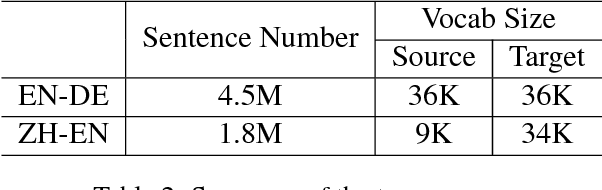
Existing approaches to neural machine translation are typically autoregressive models. While these models attain state-of-the-art translation quality, they are suffering from low parallelizability and thus slow at decoding long sequences. In this paper, we propose a novel model for fast sequence generation --- the semi-autoregressive Transformer (SAT). The SAT keeps the autoregressive property in global but relieves in local and thus is able to produce multiple successive words in parallel at each time step. Experiments conducted on English-German and Chinese-English translation tasks show that the SAT achieves a good balance between translation quality and decoding speed. On WMT'14 English-German translation, the SAT achieves 5.58$\times$ speedup while maintains 88\% translation quality, significantly better than the previous non-autoregressive methods. When produces two words at each time step, the SAT is almost lossless (only 1\% degeneration in BLEU score).
Convolutional Neural Network with Word Embeddings for Chinese Word Segmentation
Nov 13, 2017



Character-based sequence labeling framework is flexible and efficient for Chinese word segmentation (CWS). Recently, many character-based neural models have been applied to CWS. While they obtain good performance, they have two obvious weaknesses. The first is that they heavily rely on manually designed bigram feature, i.e. they are not good at capturing n-gram features automatically. The second is that they make no use of full word information. For the first weakness, we propose a convolutional neural model, which is able to capture rich n-gram features without any feature engineering. For the second one, we propose an effective approach to integrate the proposed model with word embeddings. We evaluate the model on two benchmark datasets: PKU and MSR. Without any feature engineering, the model obtains competitive performance -- 95.7% on PKU and 97.3% on MSR. Armed with word embeddings, the model achieves state-of-the-art performance on both datasets -- 96.5% on PKU and 98.0% on MSR, without using any external labeled resource.