 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonNeRF: Personalized Reconstruction from Photo Collections
Feb 16, 2023



We present PersonNeRF, a method that takes a collection of photos of a subject (e.g. Roger Federer) captured across multiple years with arbitrary body poses and appearances, and enables rendering the subject with arbitrary novel combinations of viewpoint, body pose, and appearance. PersonNeRF builds a customized neural volumetric 3D model of the subject that is able to render an entire space spanned by camera viewpoint, body pose, and appearance. A central challenge in this task is dealing with sparse observations; a given body pose is likely only observed by a single viewpoint with a single appearance, and a given appearance is only observed under a handful of different body poses. We address this issue by recovering a canonical T-pose neural volumetric representation of the subject that allows for changing appearance across different observations, but uses a shared pose-dependent motion field across all observations. We demonstrate that this approach, along with regularization of the recovered volumetric geometry to encourage smoothness, is able to recover a model that renders compelling images from novel combinations of viewpoint, pose, and appearance from these challenging unstructured photo collections, outperforming prior work for free-viewpoint human rendering.
HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
Jan 11, 2022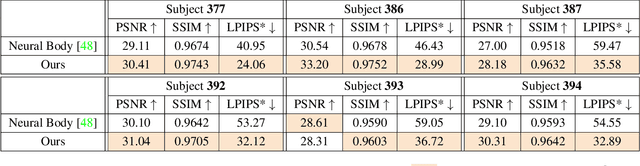
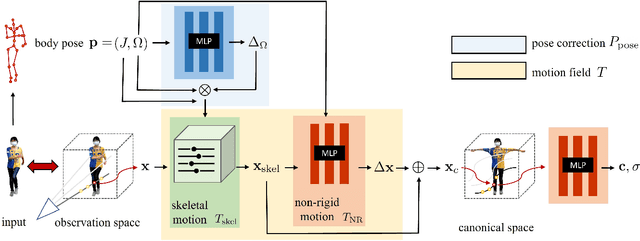
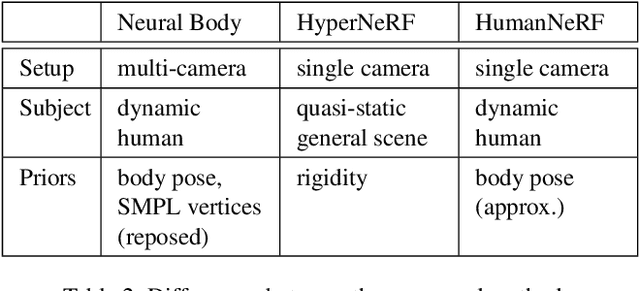

We introduce a free-viewpoint rendering method -- HumanNeRF -- that works on a given monocular video of a human performing complex body motions, e.g. a video from YouTube. Our method enables pausing the video at any frame and rendering the subject from arbitrary new camera viewpoints or even a full 360-degree camera path for that particular frame and body pose. This task is particularly challenging, as it requires synthesizing photorealistic details of the body, as seen from various camera angles that may not exist in the input video, as well as synthesizing fine details such as cloth folds and facial appearance. Our method optimizes for a volumetric representation of the person in a canonical T-pose, in concert with a motion field that maps the estimated canonical representation to every frame of the video via backward warps. The motion field is decomposed into skeletal rigid and non-rigid motions, produced by deep networks. We show significant performance improvements over prior work, and compelling examples of free-viewpoint renderings from monocular video of moving humans in challenging uncontrolled capture scenarios.
Vid2Actor: Free-viewpoint Animatable Person Synthesis from Video in the Wild
Dec 23, 2020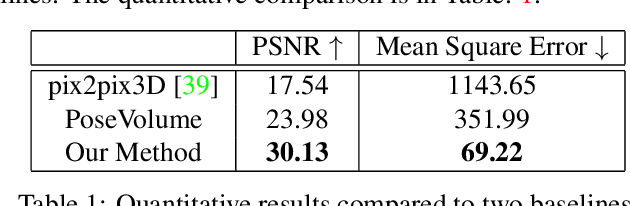

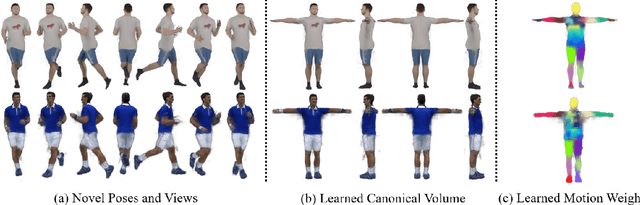

Given an "in-the-wild" video of a person, we reconstruct an animatable model of the person in the video. The output model can be rendered in any body pose to any camera view, via the learned controls, without explicit 3D mesh reconstruction. At the core of our method is a volumetric 3D human representation reconstructed with a deep network trained on input video, enabling novel pose/view synthesis. Our method is an advance over GAN-based image-to-image translation since it allows image synthesis for any pose and camera via the internal 3D representation, while at the same time it does not require a pre-rigged model or ground truth meshes for training, as in mesh-based learning. Experiments validate the design choices and yield results on synthetic data and on real videos of diverse people performing unconstrained activities (e.g. dancing or playing tennis). Finally, we demonstrate motion re-targeting and bullet-time rendering with the learned models.
Photo Wake-Up: 3D Character Animation from a Single Photo
Dec 05, 2018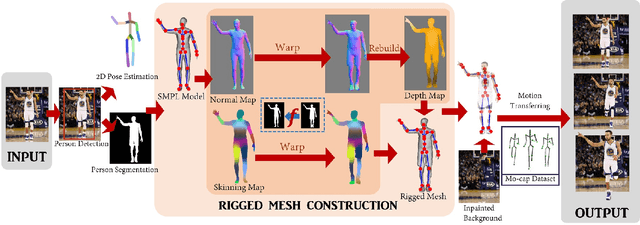
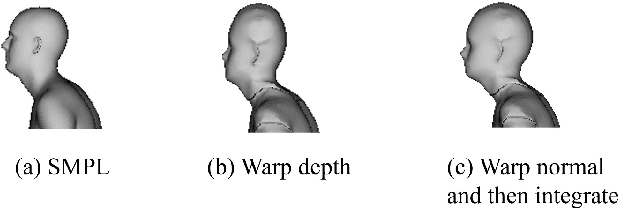

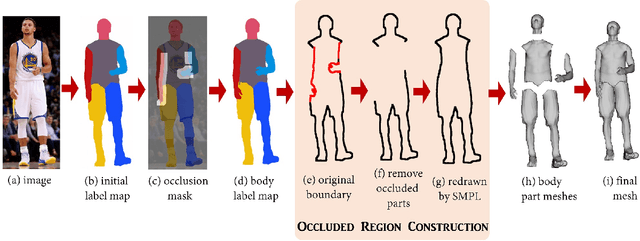
We present a method and application for animating a human subject from a single photo. E.g., the character can walk out, run, sit, or jump in 3D. The key contributions of this paper are: 1) an application of viewing and animating humans in single photos in 3D, 2) a novel 2D warping method to deform a posable template body model to fit the person's complex silhouette to create an animatable mesh, and 3) a method for handling partial self occlusions. We compare to state-of-the-art related methods and evaluate results with human studies. Further, we present an interactive interface that allows re-posing the person in 3D, and an augmented reality setup where the animated 3D person can emerge from the photo into the real world. We demonstrate the method on photos, posters, and art.