 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
Paper and Code
Jan 11, 2022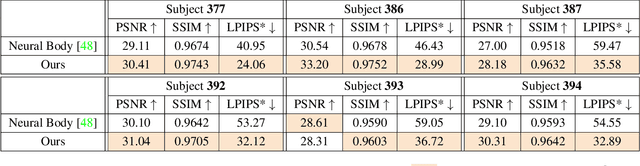
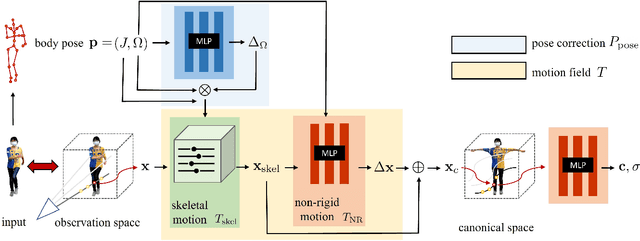
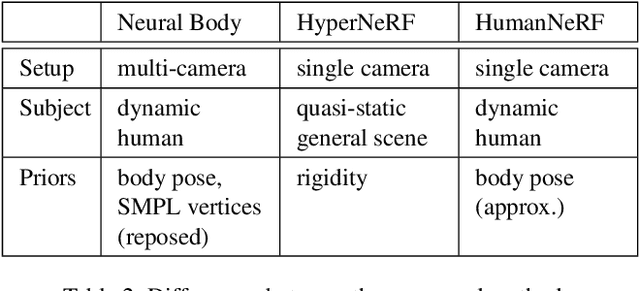

We introduce a free-viewpoint rendering method -- HumanNeRF -- that works on a given monocular video of a human performing complex body motions, e.g. a video from YouTube. Our method enables pausing the video at any frame and rendering the subject from arbitrary new camera viewpoints or even a full 360-degree camera path for that particular frame and body pose. This task is particularly challenging, as it requires synthesizing photorealistic details of the body, as seen from various camera angles that may not exist in the input video, as well as synthesizing fine details such as cloth folds and facial appearance. Our method optimizes for a volumetric representation of the person in a canonical T-pose, in concert with a motion field that maps the estimated canonical representation to every frame of the video via backward warps. The motion field is decomposed into skeletal rigid and non-rigid motions, produced by deep networks. We show significant performance improvements over prior work, and compelling examples of free-viewpoint renderings from monocular video of moving humans in challenging uncontrolled capture scenarios.