 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Mixed-Effect Models to Learn Bayesian Networks from Related Data Sets
Jun 08, 2022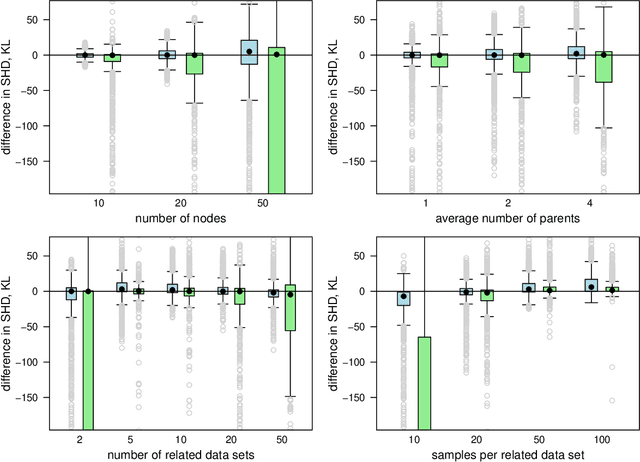
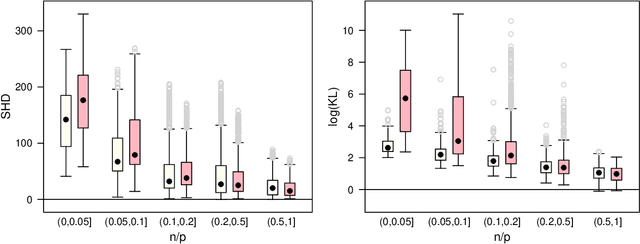

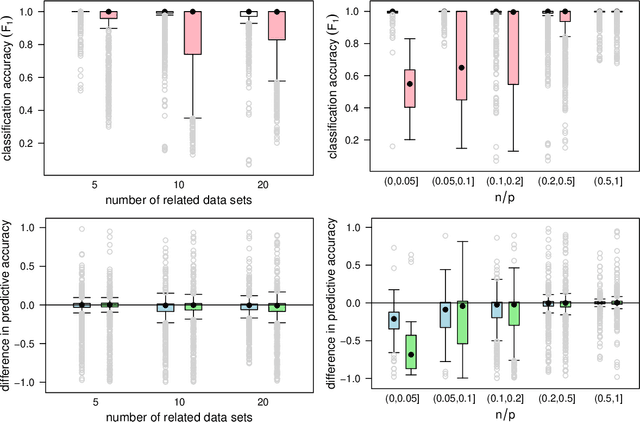
We commonly assume that data are a homogeneous set of observations when learning the structure of Bayesian networks. However, they often comprise different data sets that are related but not homogeneous because they have been collected in different ways or from different populations. In our previous work (Azzimonti, Corani and Scutari, 2021), we proposed a closed-form Bayesian Hierarchical Dirichlet score for discrete data that pools information across related data sets to learn a single encompassing network structure, while taking into account the differences in their probabilistic structures. In this paper, we provide an analogous solution for learning a Bayesian network from continuous data using mixed-effects models to pool information across the related data sets. We study its structural, parametric, predictive and classification accuracy and we show that it outperforms both conditional Gaussian Bayesian networks (that do not perform any pooling) and classical Gaussian Bayesian networks (that disregard the heterogeneous nature of the data). The improvement is marked for low sample sizes and for unbalanced data sets.
An initial alignment between neural network and target is needed for gradient descent to learn
Feb 25, 2022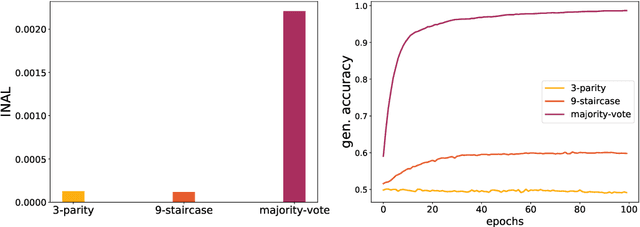
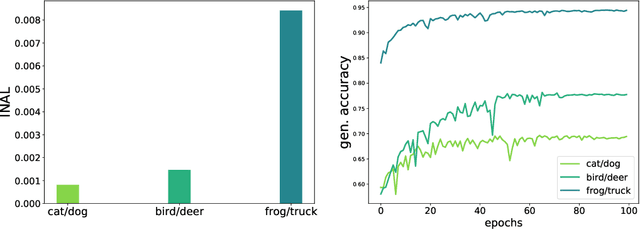
This paper introduces the notion of "Initial Alignment" (INAL) between a neural network at initialization and a target function. It is proved that if a network and target function do not have a noticeable INAL, then noisy gradient descent on a fully connected network with normalized i.i.d. initialization will not learn in polynomial time. Thus a certain amount of knowledge about the target (measured by the INAL) is needed in the architecture design. This also provides an answer to an open problem posed in [AS20]. The results are based on deriving lower-bounds for descent algorithms on symmetric neural networks without explicit knowledge of the target function beyond its INAL.