 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: A Comprehensive Linguistic Evaluation of Argument Rewriting by Large Language Models
Sep 18, 2025While LLMs have been extensively studied on general text generation tasks, there is less research on text rewriting, a task related to general text generation, and particularly on the behavior of models on this task. In this paper we analyze what changes LLMs make in a text rewriting setting. We focus specifically on argumentative texts and their improvement, a task named Argument Improvement (ArgImp). We present CLEAR: an evaluation pipeline consisting of 57 metrics mapped to four linguistic levels: lexical, syntactic, semantic and pragmatic. This pipeline is used to examine the qualities of LLM-rewritten arguments on a broad set of argumentation corpora and compare the behavior of different LLMs on this task and analyze the behavior of different LLMs on this task in terms of linguistic levels. By taking all four linguistic levels into consideration, we find that the models perform ArgImp by shortening the texts while simultaneously increasing average word length and merging sentences. Overall we note an increase in the persuasion and coherence dimensions.
Towards LLM-based Autograding for Short Textual Answers
Sep 09, 2023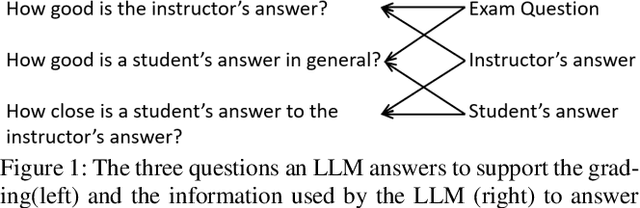
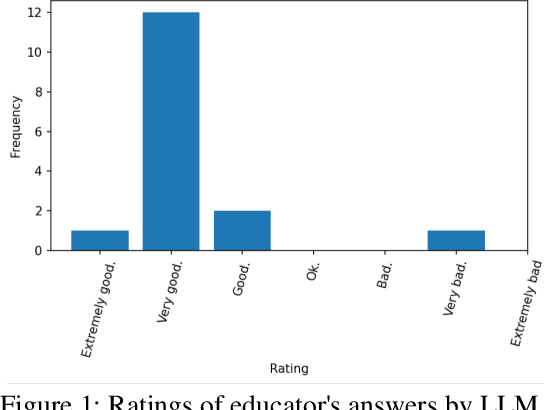
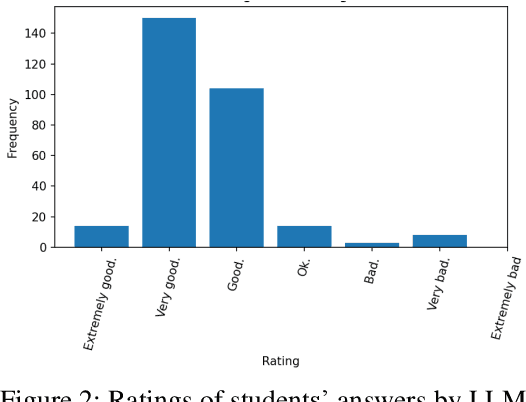
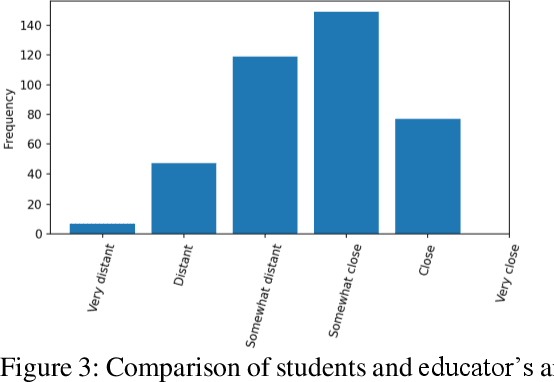
Grading of exams is an important, labor intensive, subjective, repetitive and frequently challenging task. The feasibility of autograding textual responses has greatly increased thanks to the availability of large language models (LLMs) such as ChatGPT and because of the substantial influx of data brought about by digitalization. However, entrusting AI models with decision-making roles raises ethical considerations, mainly stemming from potential biases and issues related to generating false information. Thus, in this manuscript we provide an evaluation of a large language model for the purpose of autograding, while also highlighting how LLMs can support educators in validating their grading procedures. Our evaluation is targeted towards automatic short textual answers grading (ASAG), spanning various languages and examinations from two distinct courses. Our findings suggest that while "out-of-the-box" LLMs provide a valuable tool to provide a complementary perspective, their readiness for independent automated grading remains a work in progress, necessitating human oversight.
Discourse-Aware Text Simplification: From Complex Sentences to Linked Propositions
Aug 01, 2023

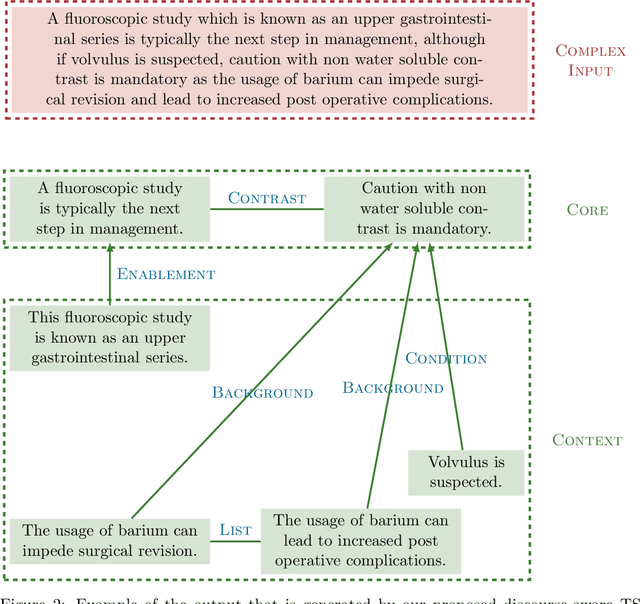

Sentences that present a complex syntax act as a major stumbling block for downstream Natural Language Processing applications whose predictive quality deteriorates with sentence length and complexity. The task of Text Simplification (TS) may remedy this situation. It aims to modify sentences in order to make them easier to process, using a set of rewriting operations, such as reordering, deletion, or splitting. State-of-the-art syntactic TS approaches suffer from two major drawbacks: first, they follow a very conservative approach in that they tend to retain the input rather than transforming it, and second, they ignore the cohesive nature of texts, where context spread across clauses or sentences is needed to infer the true meaning of a statement. To address these problems, we present a discourse-aware TS approach that splits and rephrases complex English sentences within the semantic context in which they occur. Based on a linguistically grounded transformation stage that uses clausal and phrasal disembedding mechanisms, complex sentences are transformed into shorter utterances with a simple canonical structure that can be easily analyzed by downstream applications. With sentence splitting, we thus address a TS task that has hardly been explored so far. Moreover, we introduce the notion of minimality in this context, as we aim to decompose source sentences into a set of self-contained minimal semantic units. To avoid breaking down the input into a disjointed sequence of statements that is difficult to interpret because important contextual information is missing, we incorporate the semantic context between the split propositions in the form of hierarchical structures and semantic relationships. In that way, we generate a semantic hierarchy of minimal propositions that leads to a novel representation of complex assertions that puts a semantic layer on top of the simplified sentences.
Supporting Cognitive and Emotional Empathic Writing of Students
May 31, 2021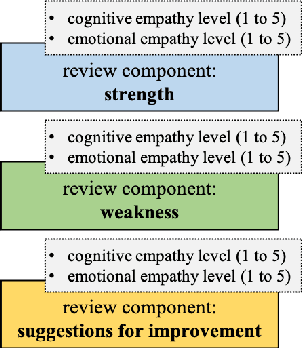


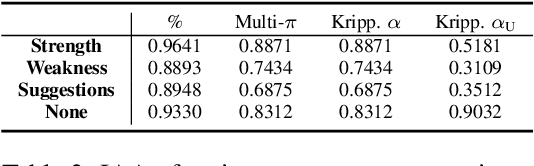
We present an annotation approach to capturing emotional and cognitive empathy in student-written peer reviews on business models in German. We propose an annotation scheme that allows us to model emotional and cognitive empathy scores based on three types of review components. Also, we conducted an annotation study with three annotators based on 92 student essays to evaluate our annotation scheme. The obtained inter-rater agreement of {\alpha}=0.79 for the components and the multi-{\pi}=0.41 for the empathy scores indicate that the proposed annotation scheme successfully guides annotators to a substantial to moderate agreement. Moreover, we trained predictive models to detect the annotated empathy structures and embedded them in an adaptive writing support system for students to receive individual empathy feedback independent of an instructor, time, and location. We evaluated our tool in a peer learning exercise with 58 students and found promising results for perceived empathy skill learning, perceived feedback accuracy, and intention to use. Finally, we present our freely available corpus of 500 empathy-annotated, student-written peer reviews on business models and our annotation guidelines to encourage future research on the design and development of empathy support systems.
Context-Preserving Text Simplification
May 24, 2021

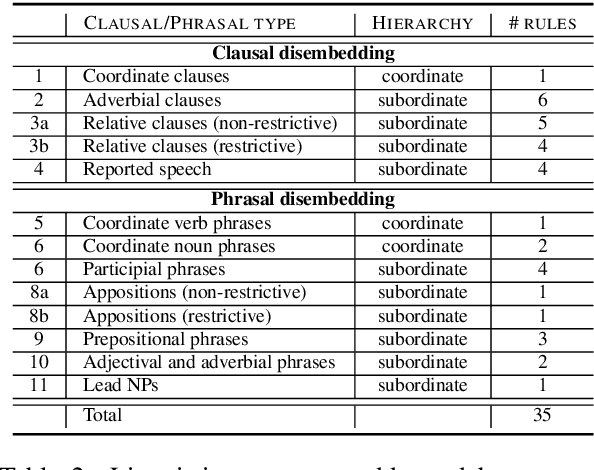
We present a context-preserving text simplification (TS) approach that recursively splits and rephrases complex English sentences into a semantic hierarchy of simplified sentences. Using a set of linguistically principled transformation patterns, input sentences are converted into a hierarchical representation in the form of core sentences and accompanying contexts that are linked via rhetorical relations. Hence, as opposed to previously proposed sentence splitting approaches, which commonly do not take into account discourse-level aspects, our TS approach preserves the semantic relationship of the decomposed constituents in the output. A comparative analysis with the annotations contained in the RST-DT shows that we are able to capture the contextual hierarchy between the split sentences with a precision of 89% and reach an average precision of 69% for the classification of the rhetorical relations that hold between them.
A Corpus for Argumentative Writing Support in German
Oct 26, 2020



In this paper, we present a novel annotation approach to capture claims and premises of arguments and their relations in student-written persuasive peer reviews on business models in German language. We propose an annotation scheme based on annotation guidelines that allows to model claims and premises as well as support and attack relations for capturing the structure of argumentative discourse in student-written peer reviews. We conduct an annotation study with three annotators on 50 persuasive essays to evaluate our annotation scheme. The obtained inter-rater agreement of $\alpha=0.57$ for argument components and $\alpha=0.49$ for argumentative relations indicates that the proposed annotation scheme successfully guides annotators to moderate agreement. Finally, we present our freely available corpus of 1,000 persuasive student-written peer reviews on business models and our annotation guidelines to encourage future research on the design and development of argumentative writing support systems for students.
DisSim: A Discourse-Aware Syntactic Text Simplification Frameworkfor English and German
Sep 26, 2019

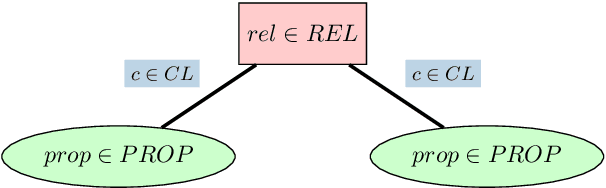
We introduce DisSim, a discourse-aware sentence splitting framework for English and German whose goal is to transform syntactically complex sentences into an intermediate representation that presents a simple and more regular structure which is easier to process for downstream semantic applications. For this purpose, we turn input sentences into a two-layered semantic hierarchy in the form of core facts and accompanying contexts, while identifying the rhetorical relations that hold between them. In that way, we preserve the coherence structure of the input and, hence, its interpretability for downstream tasks.
MinWikiSplit: A Sentence Splitting Corpus with Minimal Propositions
Sep 26, 2019



We compiled a new sentence splitting corpus that is composed of 203K pairs of aligned complex source and simplified target sentences. Contrary to previously proposed text simplification corpora, which contain only a small number of split examples, we present a dataset where each input sentence is broken down into a set of minimal propositions, i.e. a sequence of sound, self-contained utterances with each of them presenting a minimal semantic unit that cannot be further decomposed into meaningful propositions. This corpus is useful for developing sentence splitting approaches that learn how to transform sentences with a complex linguistic structure into a fine-grained representation of short sentences that present a simple and more regular structure which is easier to process for downstream applications and thus facilitates and improves their performance.
Transforming Complex Sentences into a Semantic Hierarchy
Jun 03, 2019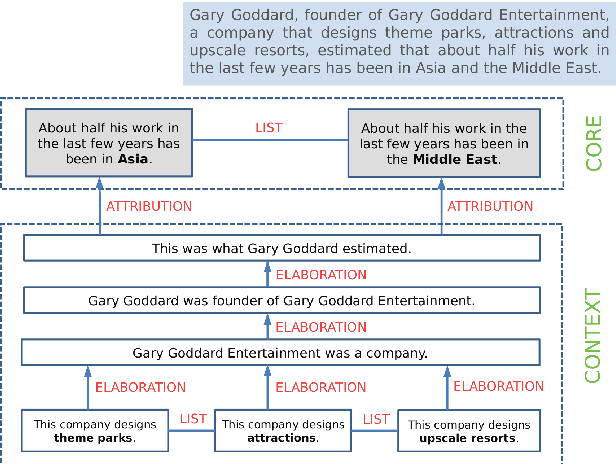
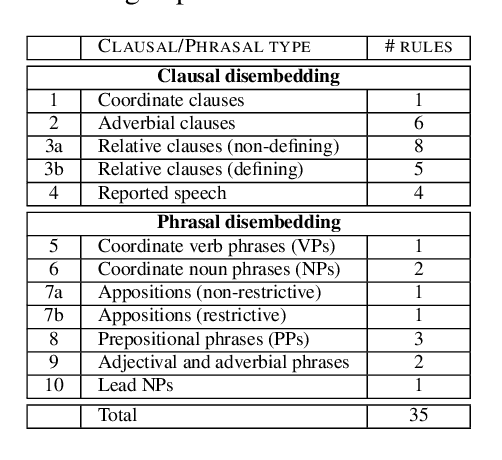

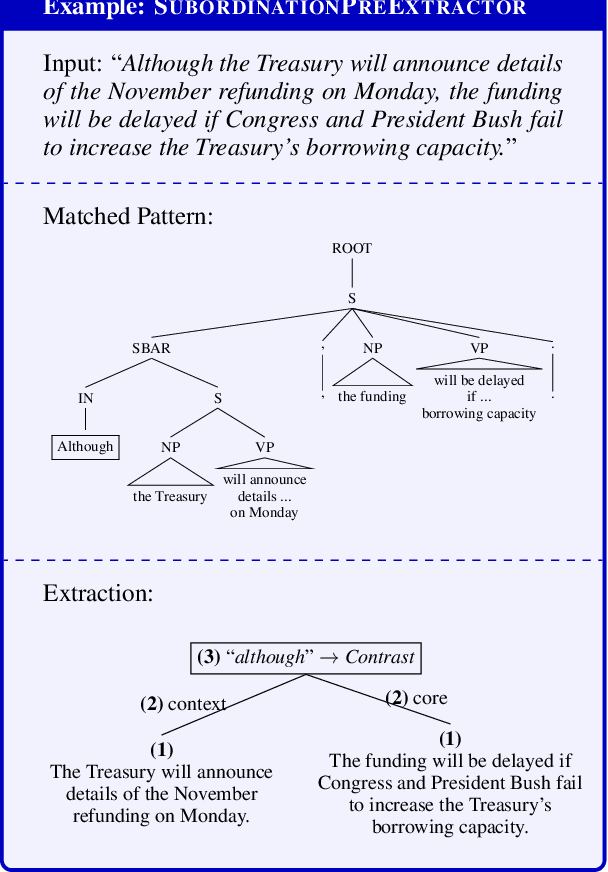
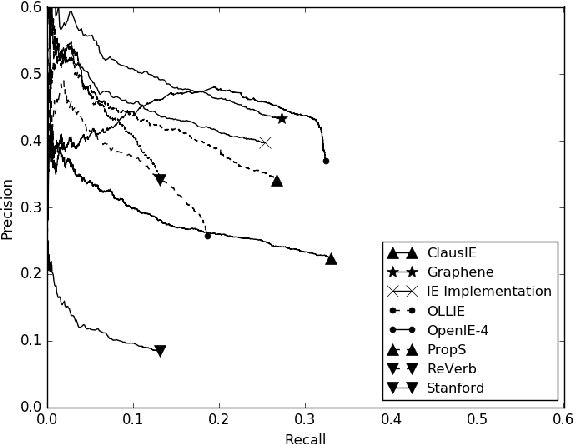
We present an approach for recursively splitting and rephrasing complex English sentences into a novel semantic hierarchy of simplified sentences, with each of them presenting a more regular structure that may facilitate a wide variety of artificial intelligence tasks, such as machine translation (MT) or information extraction (IE). Using a set of hand-crafted transformation rules, input sentences are recursively transformed into a two-layered hierarchical representation in the form of core sentences and accompanying contexts that are linked via rhetorical relations. In this way, the semantic relationship of the decomposed constituents is preserved in the output, maintaining its interpretability for downstream applications. Both a thorough manual analysis and automatic evaluation across three datasets from two different domains demonstrate that the proposed syntactic simplification approach outperforms the state of the art in structural text simplification. Moreover, an extrinsic evaluation shows that when applying our framework as a preprocessing step the performance of state-of-the-art Open IE systems can be improved by up to 346% in precision and 52% in recall. To enable reproducible research, all code is provided online.
Graphene: A Context-Preserving Open Information Extraction System
Aug 28, 2018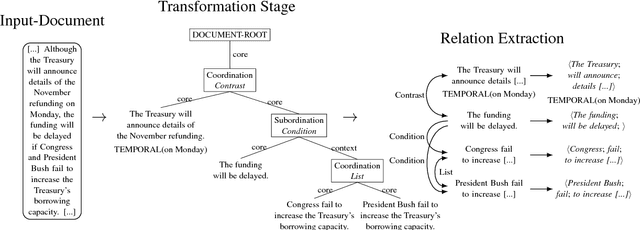

We introduce Graphene, an Open IE system whose goal is to generate accurate, meaningful and complete propositions that may facilitate a variety of downstream semantic applications. For this purpose, we transform syntactically complex input sentences into clean, compact structures in the form of core facts and accompanying contexts, while identifying the rhetorical relations that hold between them in order to maintain their semantic relationship. In that way, we preserve the context of the relational tuples extracted from a source sentence, generating a novel lightweight semantic representation for Open IE that enhances the expressiveness of the extracted propositions.