 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-based Autograding for Short Textual Answers
Sep 09, 2023
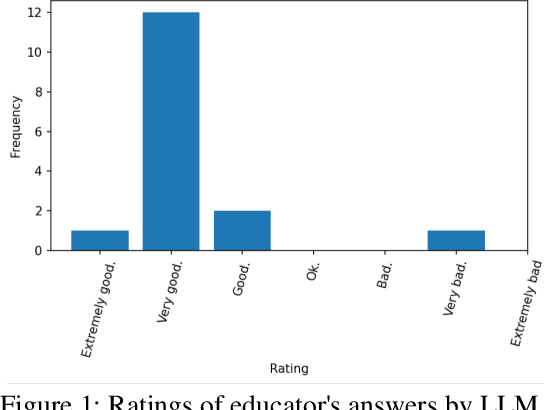
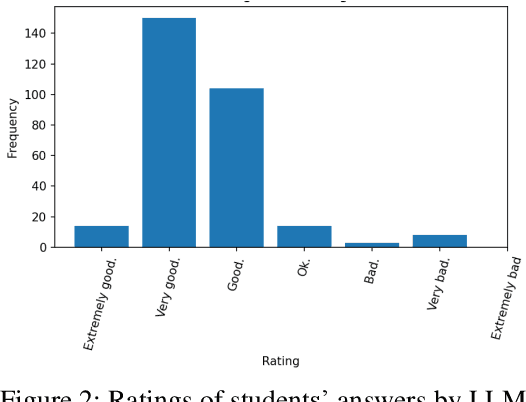
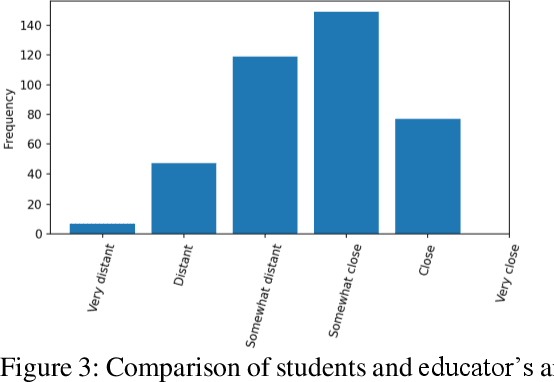
Grading of exams is an important, labor intensive, subjective, repetitive and frequently challenging task. The feasibility of autograding textual responses has greatly increased thanks to the availability of large language models (LLMs) such as ChatGPT and because of the substantial influx of data brought about by digitalization. However, entrusting AI models with decision-making roles raises ethical considerations, mainly stemming from potential biases and issues related to generating false information. Thus, in this manuscript we provide an evaluation of a large language model for the purpose of autograding, while also highlighting how LLMs can support educators in validating their grading procedures. Our evaluation is targeted towards automatic short textual answers grading (ASAG), spanning various languages and examinations from two distinct courses. Our findings suggest that while "out-of-the-box" LLMs provide a valuable tool to provide a complementary perspective, their readiness for independent automated grading remains a work in progress, necessitating human oversight.