 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqLens: Interpretable Frequency Attribution for Time Series Forecasting
Feb 09, 2026Time series forecasting models often lack interpretability, limiting their adoption in domains requiring explainable predictions. We propose \textsc{FreqLens}, an interpretable forecasting framework that discovers and attributes predictions to learnable frequency components. \textsc{FreqLens} introduces two key innovations: (1) \emph{learnable frequency discovery} -- frequency bases are parameterized via sigmoid mapping and learned from data with diversity regularization, enabling automatic discovery of dominant periodic patterns without domain knowledge; and (2) \emph{axiomatic frequency attribution} -- a theoretically grounded framework that provably satisfies Completeness, Faithfulness, Null-Frequency, and Symmetry axioms, with per-frequency attributions equivalent to Shapley values. On Traffic and Weather datasets, \textsc{FreqLens} achieves competitive or superior performance while discovering physically meaningful frequencies: all 5 independent runs discover the 24-hour daily cycle ($24.6 \pm 0.1$h, 2.5\% error) and 12-hour half-daily cycle ($11.8 \pm 0.1$h, 1.6\% error) on Traffic, and weekly cycles ($10\times$ longer than the input window) on Weather. These results demonstrate genuine frequency-level knowledge discovery with formal theoretical guarantees on attribution quality.
A Unified SPD Token Transformer Framework for EEG Classification: Systematic Comparison of Geometric Embeddings
Jan 29, 2026Spatial covariance matrices of EEG signals are Symmetric Positive Definite (SPD) and lie on a Riemannian manifold, yet the theoretical connection between embedding geometry and optimization dynamics remains unexplored. We provide a formal analysis linking embedding choice to gradient conditioning and numerical stability for SPD manifolds, establishing three theoretical results: (1) BWSPD's $\sqrtκ$ gradient conditioning (vs $κ$ for Log-Euclidean) via Daleckii-Kreĭn matrices provides better gradient conditioning on high-dimensional inputs ($d \geq 22$), with this advantage reducing on low-dimensional inputs ($d \leq 8$) where eigendecomposition overhead dominates; (2) Embedding-Space Batch Normalization (BN-Embed) approximates Riemannian normalization up to $O(\varepsilon^2)$ error, yielding $+26\%$ accuracy on 56-channel ERP data but negligible effect on 8-channel SSVEP data, matching the channel-count-dependent prediction; (3) bi-Lipschitz bounds prove BWSPD tokens preserve manifold distances with distortion governed solely by the condition ratio $κ$. We validate these predictions via a unified Transformer framework comparing BWSPD, Log-Euclidean, and Euclidean embeddings within identical architecture across 1,500+ runs on three EEG paradigms (motor imagery, ERP, SSVEP; 36 subjects). Our Log-Euclidean Transformer achieves state-of-the-art performance on all datasets, substantially outperforming classical Riemannian classifiers and recent SPD baselines, while BWSPD offers competitive accuracy with similar training time.
Quantum Reinforcement Learning-Guided Diffusion Model for Image Synthesis via Hybrid Quantum-Classical Generative Model Architectures
Sep 17, 2025Diffusion models typically employ static or heuristic classifier-free guidance (CFG) schedules, which often fail to adapt across timesteps and noise conditions. In this work, we introduce a quantum reinforcement learning (QRL) controller that dynamically adjusts CFG at each denoising step. The controller adopts a hybrid quantum--classical actor--critic architecture: a shallow variational quantum circuit (VQC) with ring entanglement generates policy features, which are mapped by a compact multilayer perceptron (MLP) into Gaussian actions over $\Delta$CFG, while a classical critic estimates value functions. The policy is optimized using Proximal Policy Optimization (PPO) with Generalized Advantage Estimation (GAE), guided by a reward that balances classification confidence, perceptual improvement, and action regularization. Experiments on CIFAR-10 demonstrate that our QRL policy improves perceptual quality (LPIPS, PSNR, SSIM) while reducing parameter count compared to classical RL actors and fixed schedules. Ablation studies on qubit number and circuit depth reveal trade-offs between accuracy and efficiency, and extended evaluations confirm robust generation under long diffusion schedules.
Q-DPTS: Quantum Differentially Private Time Series Forecasting via Variational Quantum Circuits
Aug 07, 2025Time series forecasting is vital in domains where data sensitivity is paramount, such as finance and energy systems. While Differential Privacy (DP) provides theoretical guarantees to protect individual data contributions, its integration especially via DP-SGD often impairs model performance due to injected noise. In this paper, we propose Q-DPTS, a hybrid quantum-classical framework for Quantum Differentially Private Time Series Forecasting. Q-DPTS combines Variational Quantum Circuits (VQCs) with per-sample gradient clipping and Gaussian noise injection, ensuring rigorous $(\epsilon, \delta)$-differential privacy. The expressiveness of quantum models enables improved robustness against the utility loss induced by DP mechanisms. We evaluate Q-DPTS on the ETT (Electricity Transformer Temperature) dataset, a standard benchmark for long-term time series forecasting. Our approach is compared against both classical and quantum baselines, including LSTM, QASA, QRWKV, and QLSTM. Results demonstrate that Q-DPTS consistently achieves lower prediction error under the same privacy budget, indicating a favorable privacy-utility trade-off. This work presents one of the first explorations into quantum-enhanced differentially private forecasting, offering promising directions for secure and accurate time series modeling in privacy-critical scenarios.
Benchmarking Quantum and Classical Sequential Models for Urban Telecommunication Forecasting
Aug 06, 2025In this study, we evaluate the performance of classical and quantum-inspired sequential models in forecasting univariate time series of incoming SMS activity (SMS-in) using the Milan Telecommunication Activity Dataset. Due to data completeness limitations, we focus exclusively on the SMS-in signal for each spatial grid cell. We compare five models, LSTM (baseline), Quantum LSTM (QLSTM), Quantum Adaptive Self-Attention (QASA), Quantum Receptance Weighted Key-Value (QRWKV), and Quantum Fast Weight Programmers (QFWP), under varying input sequence lengths (4, 8, 12, 16, 32 and 64). All models are trained to predict the next 10-minute SMS-in value based solely on historical values within a given sequence window. Our findings indicate that different models exhibit varying sensitivities to sequence length, suggesting that quantum enhancements are not universally advantageous. Rather, the effectiveness of quantum modules is highly dependent on the specific task and architectural design, reflecting inherent trade-offs among model size, parameterization strategies, and temporal modeling capabilities.
Quantum Reinforcement Learning Trading Agent for Sector Rotation in the Taiwan Stock Market
Jun 26, 2025We propose a hybrid quantum-classical reinforcement learning framework for sector rotation in the Taiwan stock market. Our system employs Proximal Policy Optimization (PPO) as the backbone algorithm and integrates both classical architectures (LSTM, Transformer) and quantum-enhanced models (QNN, QRWKV, QASA) as policy and value networks. An automated feature engineering pipeline extracts financial indicators from capital share data to ensure consistent model input across all configurations. Empirical backtesting reveals a key finding: although quantum-enhanced models consistently achieve higher training rewards, they underperform classical models in real-world investment metrics such as cumulative return and Sharpe ratio. This discrepancy highlights a core challenge in applying reinforcement learning to financial domains -- namely, the mismatch between proxy reward signals and true investment objectives. Our analysis suggests that current reward designs may incentivize overfitting to short-term volatility rather than optimizing risk-adjusted returns. This issue is compounded by the inherent expressiveness and optimization instability of quantum circuits under Noisy Intermediate-Scale Quantum (NISQ) constraints. We discuss the implications of this reward-performance gap and propose directions for future improvement, including reward shaping, model regularization, and validation-based early stopping. Our work offers a reproducible benchmark and critical insights into the practical challenges of deploying quantum reinforcement learning in real-world finance.
Vision-QRWKV: Exploring Quantum-Enhanced RWKV Models for Image Classification
Jun 07, 2025Recent advancements in quantum machine learning have shown promise in enhancing classical neural network architectures, particularly in domains involving complex, high-dimensional data. Building upon prior work in temporal sequence modeling, this paper introduces Vision-QRWKV, a hybrid quantum-classical extension of the Receptance Weighted Key Value (RWKV) architecture, applied for the first time to image classification tasks. By integrating a variational quantum circuit (VQC) into the channel mixing component of RWKV, our model aims to improve nonlinear feature transformation and enhance the expressive capacity of visual representations. We evaluate both classical and quantum RWKV models on a diverse collection of 14 medical and standard image classification benchmarks, including MedMNIST datasets, MNIST, and FashionMNIST. Our results demonstrate that the quantum-enhanced model outperforms its classical counterpart on a majority of datasets, particularly those with subtle or noisy class distinctions (e.g., ChestMNIST, RetinaMNIST, BloodMNIST). This study represents the first systematic application of quantum-enhanced RWKV in the visual domain, offering insights into the architectural trade-offs and future potential of quantum models for lightweight and efficient vision tasks.
Unraveling Quantum Environments: Transformer-Assisted Learning in Lindblad Dynamics
May 11, 2025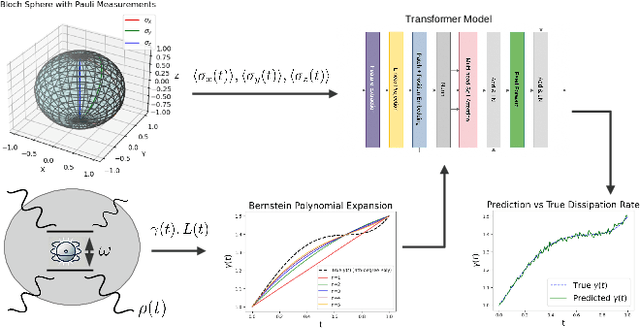
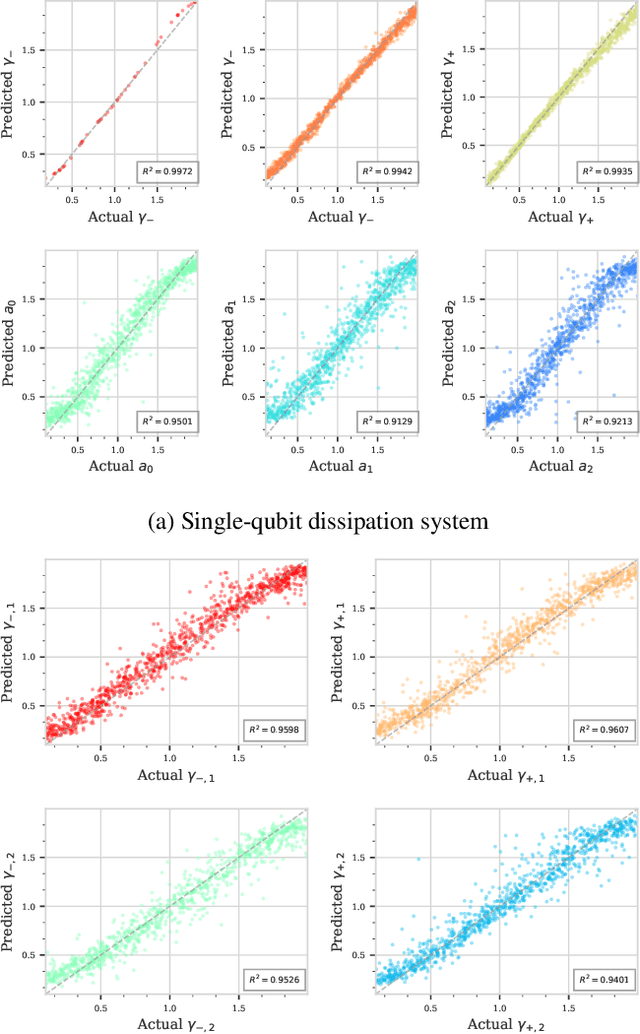
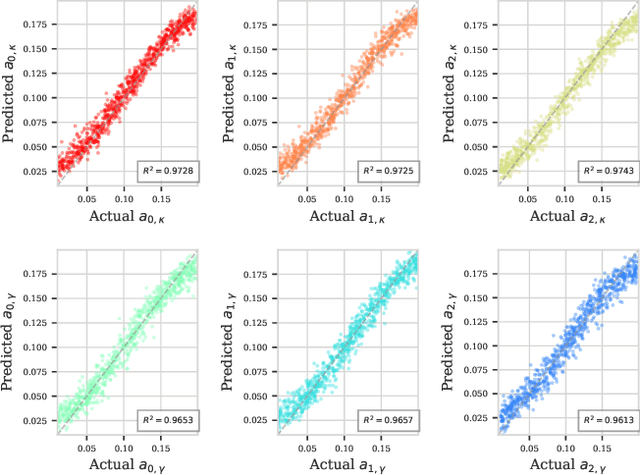
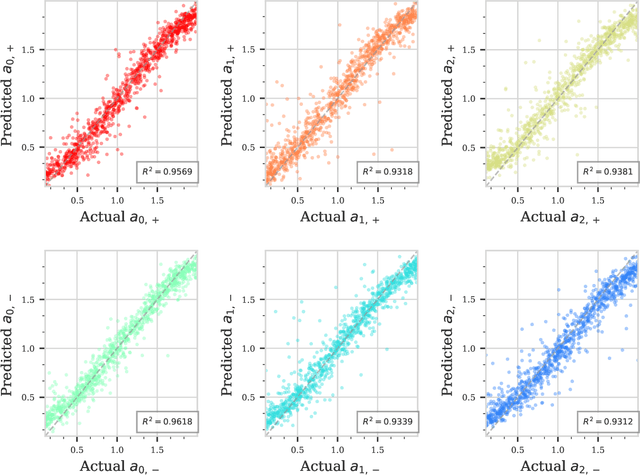
Understanding dissipation in open quantum systems is crucial for the development of robust quantum technologies. In this work, we introduce a Transformer-based machine learning framework to infer time-dependent dissipation rates in quantum systems governed by the Lindblad master equation. Our approach uses time series of observable quantities, such as expectation values of single Pauli operators, as input to learn dissipation profiles without requiring knowledge of the initial quantum state or even the system Hamiltonian. We demonstrate the effectiveness of our approach on a hierarchy of open quantum models of increasing complexity, including single-qubit systems with time-independent or time-dependent jump rates, two-qubit interacting systems (e.g., Heisenberg and transverse Ising models), and the Jaynes--Cummings model involving light--matter interaction and cavity loss with time-dependent decay rates. Our method accurately reconstructs both fixed and time-dependent decay rates from observable time series. To support this, we prove that under reasonable assumptions, the jump rates in all these models are uniquely determined by a finite set of observables, such as qubit and photon measurements. In practice, we combine Transformer-based architectures with lightweight feature extraction techniques to efficiently learn these dynamics. Our results suggest that modern machine learning tools can serve as scalable and data-driven alternatives for identifying unknown environments in open quantum systems.
Quantum Adaptive Self-Attention for Quantum Transformer Models
Apr 05, 2025Transformer models have revolutionized sequential learning across various domains, yet their self-attention mechanism incurs quadratic computational cost, posing limitations for real-time and resource-constrained tasks. To address this, we propose Quantum Adaptive Self-Attention (QASA), a novel hybrid architecture that enhances classical Transformer models with a quantum attention mechanism. QASA replaces dot-product attention with a parameterized quantum circuit (PQC) that adaptively captures inter-token relationships in the quantum Hilbert space. Additionally, a residual quantum projection module is introduced before the feedforward network to further refine temporal features. Our design retains classical efficiency in earlier layers while injecting quantum expressiveness in the final encoder block, ensuring compatibility with current NISQ hardware. Experiments on synthetic time-series tasks demonstrate that QASA achieves faster convergence and superior generalization compared to both standard Transformers and reduced classical variants. Preliminary complexity analysis suggests potential quantum advantages in gradient computation, opening new avenues for efficient quantum deep learning models.
Psycho Gundam: Electroencephalography based real-time robotic control system with deep learning
Nov 16, 2024The Psycho Frame, a sophisticated system primarily used in Universal Century (U.C.) series mobile suits for NEWTYPE pilots, has evolved as an integral component in harnessing the latent potential of mental energy. Its ability to amplify and resonate with the pilot's psyche enables real-time mental control, creating unique applications such as psychomagnetic fields and sensory-based weaponry. This paper presents the development of a novel robotic control system inspired by the Psycho Frame, combining electroencephalography (EEG) and deep learning for real-time control of robotic systems. By capturing and interpreting brainwave data through EEG, the system extends human cognitive commands to robotic actions, reflecting the seamless synchronization of thought and machine, much like the Psyco Frame's integration with a Newtype pilot's mental faculties. This research demonstrates how modern AI techniques can expand the limits of human-machine interaction, potentially transcending traditional input methods and enabling a deeper, more intuitive control of complex robotic systems.