 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqLens: Interpretable Frequency Attribution for Time Series Forecasting
Feb 09, 2026Time series forecasting models often lack interpretability, limiting their adoption in domains requiring explainable predictions. We propose \textsc{FreqLens}, an interpretable forecasting framework that discovers and attributes predictions to learnable frequency components. \textsc{FreqLens} introduces two key innovations: (1) \emph{learnable frequency discovery} -- frequency bases are parameterized via sigmoid mapping and learned from data with diversity regularization, enabling automatic discovery of dominant periodic patterns without domain knowledge; and (2) \emph{axiomatic frequency attribution} -- a theoretically grounded framework that provably satisfies Completeness, Faithfulness, Null-Frequency, and Symmetry axioms, with per-frequency attributions equivalent to Shapley values. On Traffic and Weather datasets, \textsc{FreqLens} achieves competitive or superior performance while discovering physically meaningful frequencies: all 5 independent runs discover the 24-hour daily cycle ($24.6 \pm 0.1$h, 2.5\% error) and 12-hour half-daily cycle ($11.8 \pm 0.1$h, 1.6\% error) on Traffic, and weekly cycles ($10\times$ longer than the input window) on Weather. These results demonstrate genuine frequency-level knowledge discovery with formal theoretical guarantees on attribution quality.
A Unified SPD Token Transformer Framework for EEG Classification: Systematic Comparison of Geometric Embeddings
Jan 29, 2026Spatial covariance matrices of EEG signals are Symmetric Positive Definite (SPD) and lie on a Riemannian manifold, yet the theoretical connection between embedding geometry and optimization dynamics remains unexplored. We provide a formal analysis linking embedding choice to gradient conditioning and numerical stability for SPD manifolds, establishing three theoretical results: (1) BWSPD's $\sqrtκ$ gradient conditioning (vs $κ$ for Log-Euclidean) via Daleckii-Kreĭn matrices provides better gradient conditioning on high-dimensional inputs ($d \geq 22$), with this advantage reducing on low-dimensional inputs ($d \leq 8$) where eigendecomposition overhead dominates; (2) Embedding-Space Batch Normalization (BN-Embed) approximates Riemannian normalization up to $O(\varepsilon^2)$ error, yielding $+26\%$ accuracy on 56-channel ERP data but negligible effect on 8-channel SSVEP data, matching the channel-count-dependent prediction; (3) bi-Lipschitz bounds prove BWSPD tokens preserve manifold distances with distortion governed solely by the condition ratio $κ$. We validate these predictions via a unified Transformer framework comparing BWSPD, Log-Euclidean, and Euclidean embeddings within identical architecture across 1,500+ runs on three EEG paradigms (motor imagery, ERP, SSVEP; 36 subjects). Our Log-Euclidean Transformer achieves state-of-the-art performance on all datasets, substantially outperforming classical Riemannian classifiers and recent SPD baselines, while BWSPD offers competitive accuracy with similar training time.
Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning
Feb 24, 2024Food classification is the foundation for developing food vision tasks and plays a key role in the burgeoning field of computational nutrition. Due to the complexity of food requiring fine-grained classification, recent academic research mainly modifies Convolutional Neural Networks (CNNs) and/or Vision Transformers (ViTs) to perform food category classification. However, to learn fine-grained features, the CNN backbone needs additional structural design, whereas ViT, containing the self-attention module, has increased computational complexity. In recent months, a new Sequence State Space (S4) model, through a Selection mechanism and computation with a Scan (S6), colloquially termed Mamba, has demonstrated superior performance and computation efficiency compared to the Transformer architecture. The VMamba model, which incorporates the Mamba mechanism into image tasks (such as classification), currently establishes the state-of-the-art (SOTA) on the ImageNet dataset. In this research, we introduce an academically underestimated food dataset CNFOOD-241, and pioneer the integration of a residual learning framework within the VMamba model to concurrently harness both global and local state features inherent in the original VMamba architectural design. The research results show that VMamba surpasses current SOTA models in fine-grained and food classification. The proposed Res-VMamba further improves the classification accuracy to 79.54\% without pretrained weight. Our findings elucidate that our proposed methodology establishes a new benchmark for SOTA performance in food recognition on the CNFOOD-241 dataset. The code can be obtained on GitHub: https://github.com/ChiShengChen/ResVMamba.
ET-USB: Transformer-Based Sequential Behavior Modeling for Inbound Customer Service
Dec 27, 2019
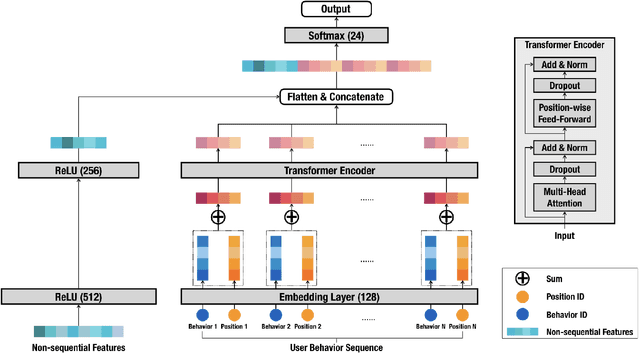

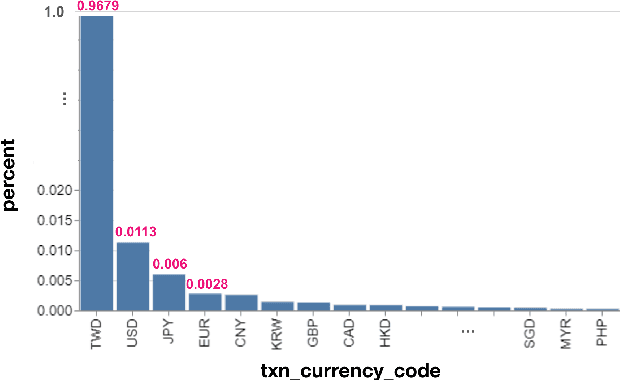
Deep learning models with attention mechanisms have achieved exceptional results for many tasks, including language tasks and recommendation systems. Whereas previous studies have emphasized allocation of phone agents, we focused on inbound call prediction for customer service. A common method of analyzing user history behaviors is to extract all types of aggregated feature over time, but that method may fail to detect users' behavioral sequences. Therefore, we created a new approach, ET-USB, that incorporates users' sequential and nonsequential features; we apply the powerful Transformer encoder, a self-attention network model, to capture the information underlying user behavior sequences. ET-USB is helpful in various business scenarios at Cathay Financial Holdings. We conducted experiments to test the proposed network structure's ability to process various dimensions of behavior data; the results suggest that ET-USB delivers results superior to those of delivered by other deep-learning models.