 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into the Imbalance of Positive Proposals in Two-stage Object Detection
May 23, 2020

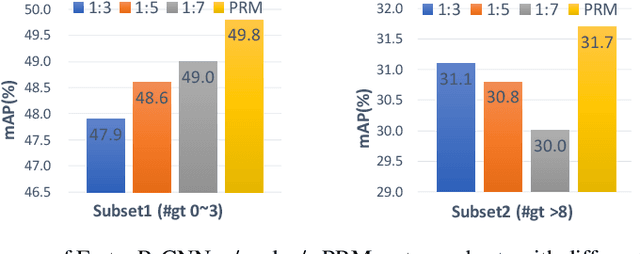
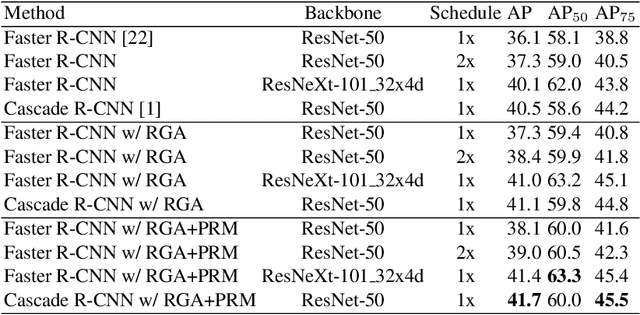
Imbalance issue is a major yet unsolved bottleneck for the current object detection models. In this work, we observe two crucial yet never discussed imbalance issues. The first imbalance lies in the large number of low-quality RPN proposals, which makes the R-CNN module (i.e., post-classification layers) become highly biased towards the negative proposals in the early training stage. The second imbalance stems from the unbalanced ground-truth numbers across different testing images, resulting in the imbalance of the number of potentially existing positive proposals in testing phase. To tackle these two imbalance issues, we incorporates two innovations into Faster R-CNN: 1) an R-CNN Gradient Annealing (RGA) strategy to enhance the impact of positive proposals in the early training stage. 2) a set of Parallel R-CNN Modules (PRM) with different positive/negative sampling ratios during training on one same backbone. Our RGA and PRM can totally bring 2.0% improvements on AP on COCO minival. Experiments on CrowdHuman further validates the effectiveness of our innovations across various kinds of object detection tasks.
Walk-Steered Convolution for Graph Classification
Apr 16, 2018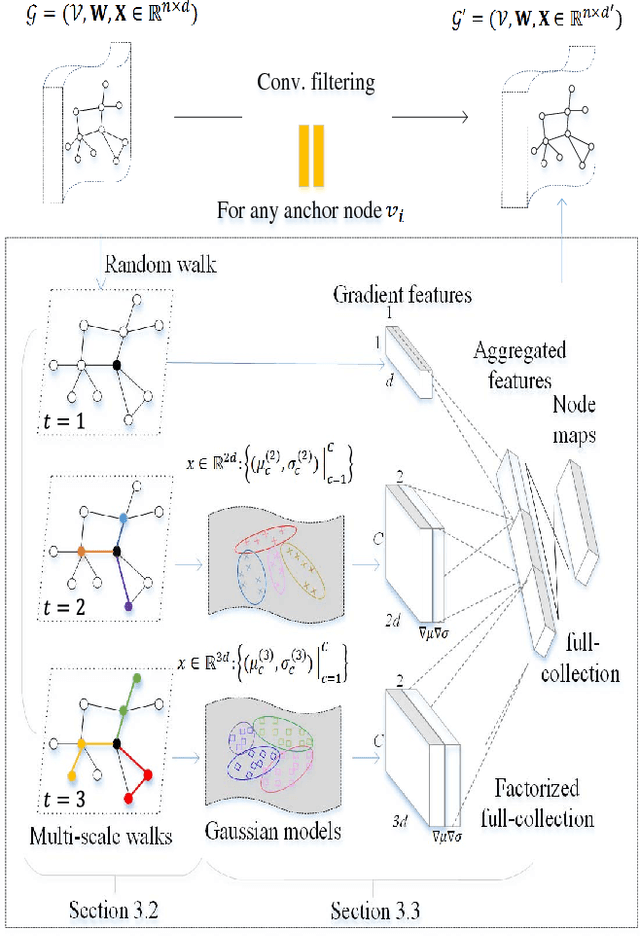
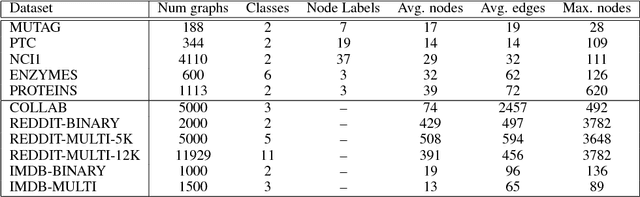


Graph classification is a fundamental but challenging problem due to the non-Euclidean property of graph. In this work, we jointly leverage the powerful representation ability of random walk and the essential success of standard convolutional network work (CNN), to propose a random walk based convolutional network, called walk-steered convolution (WSC). Different from those existing graph CNNs with deterministic neighbor searching, we randomly sample multi-scale walk fields by using random walk, which is more flexible to the scalability of graph. To encode each-scale walk field consisting of several walk paths, specifically, we characterize the directions of walk field by multiple Gaussian models so as to better analogize the standard CNNs on images. Each Gaussian implicitly defines a directions and all of them properly encode the spatial layout of walks after the gradient projecting to the space of Gaussian parameters. Further, a graph coarsening layer using dynamical clustering is stacked upon the Gaussian encoding to capture high-level semantics of graph. Comprehensive evaluations on several public datasets well demonstrate the superiority of our proposed graph learning method over other state-of-the-arts for graph classification.