 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSelect: Customized Selection of Parameters for Fine-Tuning during Personalized Federated Learning
Jul 07, 2023

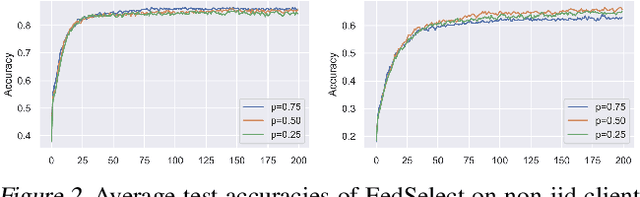
Recent advancements in federated learning (FL) seek to increase client-level performance by fine-tuning client parameters on local data or personalizing architectures for the local task. Existing methods for such personalization either prune a global model or fine-tune a global model on a local client distribution. However, these existing methods either personalize at the expense of retaining important global knowledge, or predetermine network layers for fine-tuning, resulting in suboptimal storage of global knowledge within client models. Enlightened by the lottery ticket hypothesis, we first introduce a hypothesis for finding optimal client subnetworks to locally fine-tune while leaving the rest of the parameters frozen. We then propose a novel FL framework, FedSelect, using this procedure that directly personalizes both client subnetwork structure and parameters, via the simultaneous discovery of optimal parameters for personalization and the rest of parameters for global aggregation during training. We show that this method achieves promising results on CIFAR-10.
* Work in progress
Deep Contrastive Graph Representation via Adaptive Homotopy Learning
Jun 17, 2021
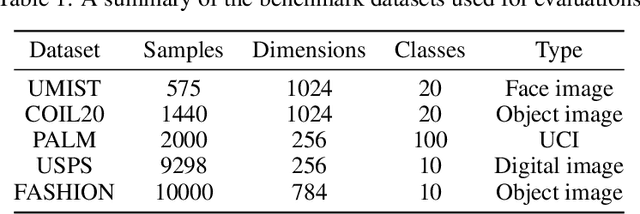

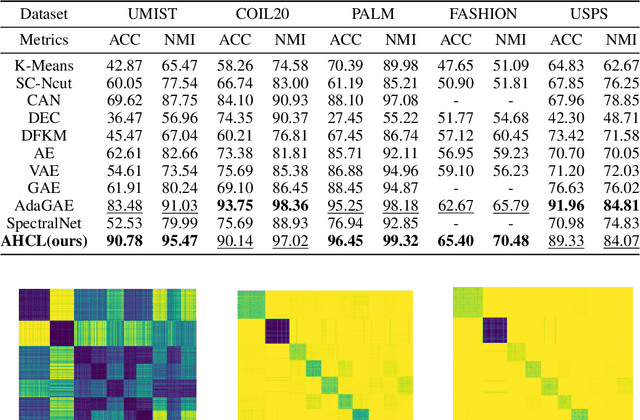
Homotopy model is an excellent tool exploited by diverse research works in the field of machine learning. However, its flexibility is limited due to lack of adaptiveness, i.e., manual fixing or tuning the appropriate homotopy coefficients. To address the problem above, we propose a novel adaptive homotopy framework (AH) in which the Maclaurin duality is employed, such that the homotopy parameters can be adaptively obtained. Accordingly, the proposed AH can be widely utilized to enhance the homotopy-based algorithm. In particular, in this paper, we apply AH to contrastive learning (AHCL) such that it can be effectively transferred from weak-supervised learning (given label priori) to unsupervised learning, where soft labels of contrastive learning are directly and adaptively learned. Accordingly, AHCL has the adaptive ability to extract deep features without any sort of prior information. Consequently, the affinity matrix formulated by the related adaptive labels can be constructed as the deep Laplacian graph that incorporates the topology of deep representations for the inputs. Eventually, extensive experiments on benchmark datasets validate the superiority of our method.