 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRPO-RM: Fine-Tuning Representation Models via GRPO-Driven Reinforcement Learning
Nov 19, 2025The Group Relative Policy Optimization (GRPO), a reinforcement learning method used to fine-tune large language models (LLMs), has proved its effectiveness in practical applications such as DeepSeek-R1. It raises a question whether GRPO can be generalized to representation learning models. In this paper, we propose Group Relative Policy Optimization for Representation Model (GRPO-RM), and investigate the performance of GRPO-like policy in post-training representation models. Specifically, our method establishes a predefined output set to functionally replace token sequence sampling in LLMs, thereby generating an output group, which is essential for the probability-driven optimization of GRPO. In addition, a specialized reward function is designed to accommodate the properties of representation models. Extensive experiments are conducted on various real-world datasets to validate the effectiveness of our proposed method.
Explore How to Inject Beneficial Noise in MLLMs
Nov 17, 2025Multimodal Large Language Models (MLLMs) have played an increasingly important role in multimodal intelligence. However, the existing fine-tuning methods often ignore cross-modal heterogeneity, limiting their full potential. In this work, we propose a novel fine-tuning strategy by injecting beneficial random noise, which outperforms previous methods and even surpasses full fine-tuning, with minimal additional parameters. The proposed Multimodal Noise Generator (MuNG) enables efficient modality fine-tuning by injecting customized noise into the frozen MLLMs. Specifically, we reformulate the reasoning process of MLLMs from a variational inference perspective, upon which we design a multimodal noise generator that dynamically analyzes cross-modal relationships in image-text pairs to generate task-adaptive beneficial noise. Injecting this type of noise into the MLLMs effectively suppresses irrelevant semantic components, leading to significantly improved cross-modal representation alignment and enhanced performance on downstream tasks. Experiments on two mainstream MLLMs, QwenVL and LLaVA, demonstrate that our method surpasses full-parameter fine-tuning and other existing fine-tuning approaches, while requiring adjustments to only about $1\sim2\%$ additional parameters. The relevant code is uploaded in the supplementary.
CNN2GNN: How to Bridge CNN with GNN
Apr 23, 2024Although the convolutional neural network (CNN) has achieved excellent performance in vision tasks by extracting the intra-sample representation, it will take a higher training expense because of stacking numerous convolutional layers. Recently, as the bilinear models, graph neural networks (GNN) have succeeded in exploring the underlying topological relationship among the graph data with a few graph neural layers. Unfortunately, it cannot be directly utilized on non-graph data due to the lack of graph structure and has high inference latency on large-scale scenarios. Inspired by these complementary strengths and weaknesses, \textit{we discuss a natural question, how to bridge these two heterogeneous networks?} In this paper, we propose a novel CNN2GNN framework to unify CNN and GNN together via distillation. Firstly, to break the limitations of GNN, a differentiable sparse graph learning module is designed as the head of networks to dynamically learn the graph for inductive learning. Then, a response-based distillation is introduced to transfer the knowledge from CNN to GNN and bridge these two heterogeneous networks. Notably, due to extracting the intra-sample representation of a single instance and the topological relationship among the datasets simultaneously, the performance of distilled ``boosted'' two-layer GNN on Mini-ImageNet is much higher than CNN containing dozens of layers such as ResNet152.
Deep Manifold Learning with Graph Mining
Jul 18, 2022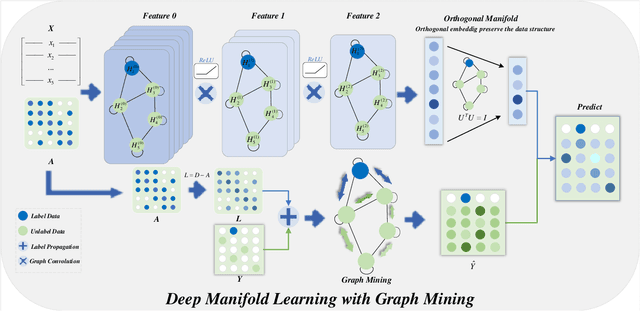

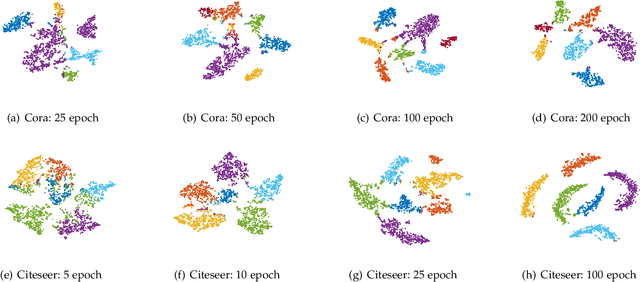
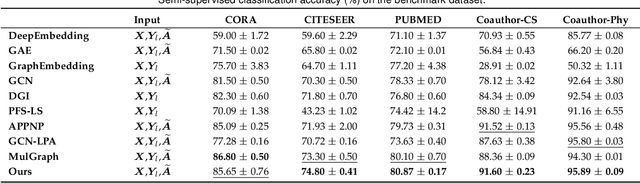
Admittedly, Graph Convolution Network (GCN) has achieved excellent results on graph datasets such as social networks, citation networks, etc. However, softmax used as the decision layer in these frameworks is generally optimized with thousands of iterations via gradient descent. Furthermore, due to ignoring the inner distribution of the graph nodes, the decision layer might lead to an unsatisfactory performance in semi-supervised learning with less label support. To address the referred issues, we propose a novel graph deep model with a non-gradient decision layer for graph mining. Firstly, manifold learning is unified with label local-structure preservation to capture the topological information of the nodes. Moreover, owing to the non-gradient property, closed-form solutions is achieved to be employed as the decision layer for GCN. Particularly, a joint optimization method is designed for this graph model, which extremely accelerates the convergence of the model. Finally, extensive experiments show that the proposed model has achieved state-of-the-art performance compared to the current models.
Deep Contrastive Graph Representation via Adaptive Homotopy Learning
Jun 17, 2021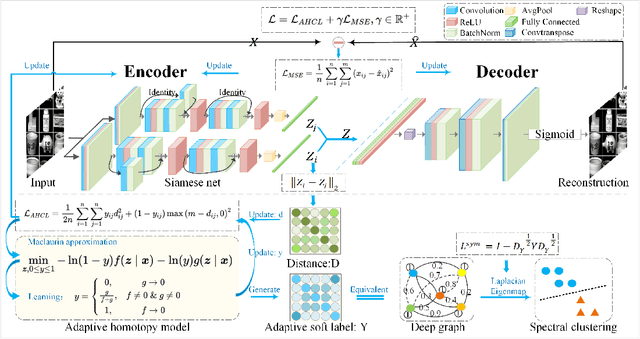
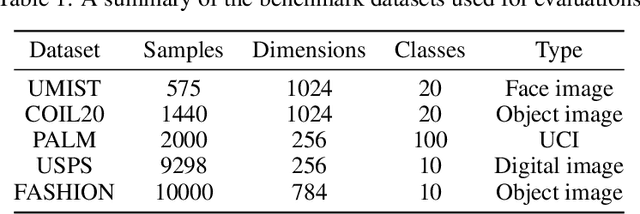

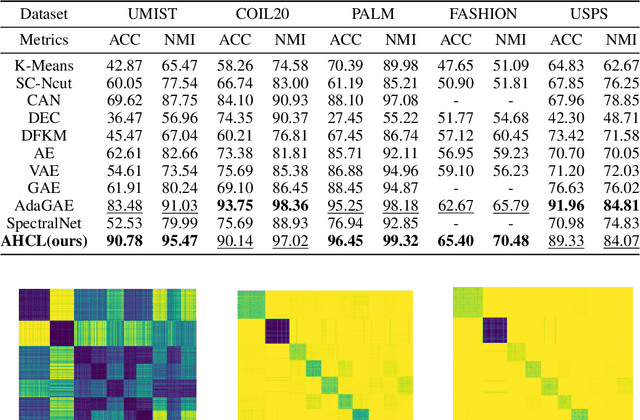
Homotopy model is an excellent tool exploited by diverse research works in the field of machine learning. However, its flexibility is limited due to lack of adaptiveness, i.e., manual fixing or tuning the appropriate homotopy coefficients. To address the problem above, we propose a novel adaptive homotopy framework (AH) in which the Maclaurin duality is employed, such that the homotopy parameters can be adaptively obtained. Accordingly, the proposed AH can be widely utilized to enhance the homotopy-based algorithm. In particular, in this paper, we apply AH to contrastive learning (AHCL) such that it can be effectively transferred from weak-supervised learning (given label priori) to unsupervised learning, where soft labels of contrastive learning are directly and adaptively learned. Accordingly, AHCL has the adaptive ability to extract deep features without any sort of prior information. Consequently, the affinity matrix formulated by the related adaptive labels can be constructed as the deep Laplacian graph that incorporates the topology of deep representations for the inputs. Eventually, extensive experiments on benchmark datasets validate the superiority of our method.
Non-Gradient Manifold Neural Network
Jun 15, 2021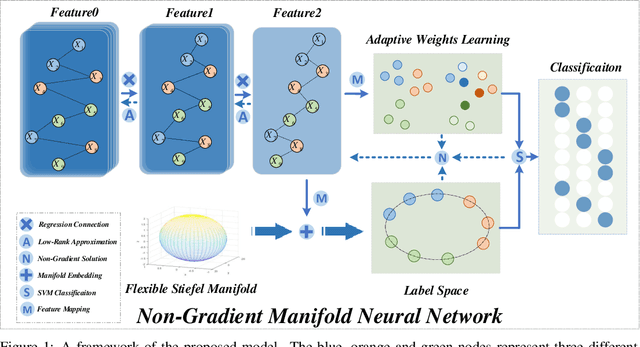

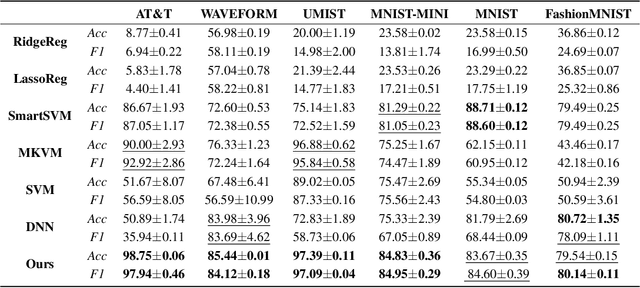

Deep neural network (DNN) generally takes thousands of iterations to optimize via gradient descent and thus has a slow convergence. In addition, softmax, as a decision layer, may ignore the distribution information of the data during classification. Aiming to tackle the referred problems, we propose a novel manifold neural network based on non-gradient optimization, i.e., the closed-form solutions. Considering that the activation function is generally invertible, we reconstruct the network via forward ridge regression and low rank backward approximation, which achieve the rapid convergence. Moreover, by unifying the flexible Stiefel manifold and adaptive support vector machine, we devise the novel decision layer which efficiently fits the manifold structure of the data and label information. Consequently, a jointly non-gradient optimization method is designed to generate the network with closed-form results. Eventually, extensive experiments validate the superior performance of the model.