 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Aesthetic Score Distribution through Cumulative Jensen-Shannon Divergence
Nov 20, 2017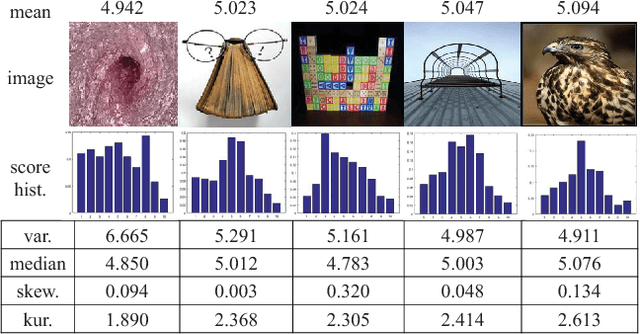
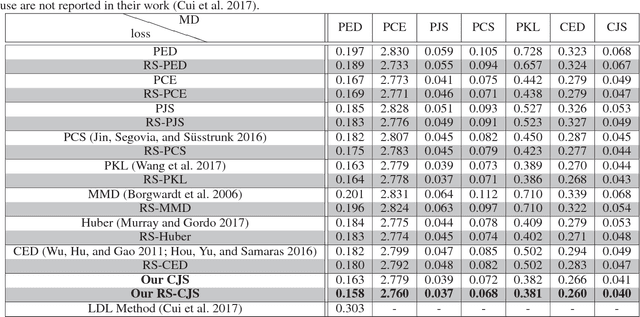
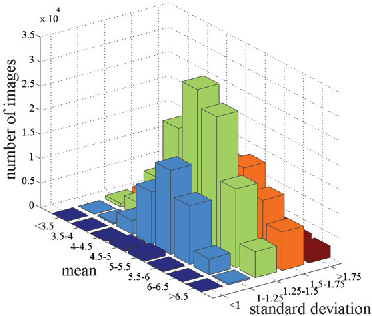

Aesthetic quality prediction is a challenging task in the computer vision community because of the complex interplay with semantic contents and photographic technologies. Recent studies on the powerful deep learning based aesthetic quality assessment usually use a binary high-low label or a numerical score to represent the aesthetic quality. However the scalar representation cannot describe well the underlying varieties of the human perception of aesthetics. In this work, we propose to predict the aesthetic score distribution (i.e., a score distribution vector of the ordinal basic human ratings) using Deep Convolutional Neural Network (DCNN). Conventional DCNNs which aim to minimize the difference between the predicted scalar numbers or vectors and the ground truth cannot be directly used for the ordinal basic rating distribution. Thus, a novel CNN based on the Cumulative distribution with Jensen-Shannon divergence (CJS-CNN) is presented to predict the aesthetic score distribution of human ratings, with a new reliability-sensitive learning method based on the kurtosis of the score distribution, which eliminates the requirement of the original full data of human ratings (without normalization). Experimental results on large scale aesthetic dataset demonstrate the effectiveness of our introduced CJS-CNN in this task.
Privacy Preserving Face Retrieval in the Cloud for Mobile Users
Aug 09, 2017



Recently, cloud storage and processing have been widely adopted. Mobile users in one family or one team may automatically backup their photos to the same shared cloud storage space. The powerful face detector trained and provided by a 3rd party may be used to retrieve the photo collection which contains a specific group of persons from the cloud storage server. However, the privacy of the mobile users may be leaked to the cloud server providers. In the meanwhile, the copyright of the face detector should be protected. Thus, in this paper, we propose a protocol of privacy preserving face retrieval in the cloud for mobile users, which protects the user photos and the face detector simultaneously. The cloud server only provides the resources of storage and computing and can not learn anything of the user photos and the face detector. We test our protocol inside several families and classes. The experimental results reveal that our protocol can successfully retrieve the proper photos from the cloud server and protect the user photos and the face detector.
Efficient Privacy Preserving Viola-Jones Type Object Detection via Random Base Image Representation
Mar 30, 2017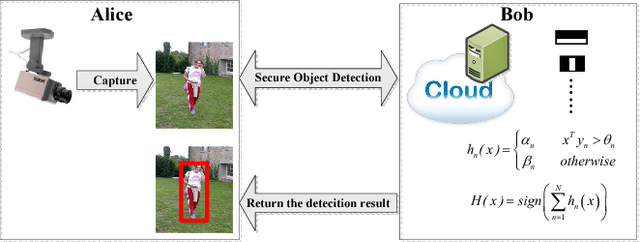
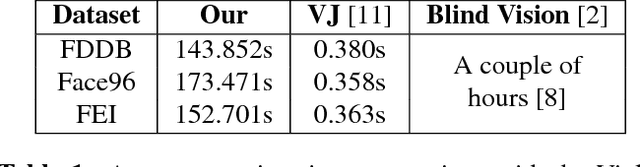
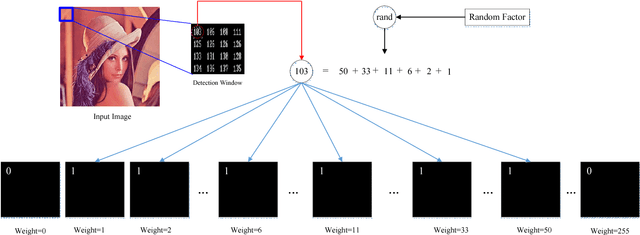

A cloud server spent a lot of time, energy and money to train a Viola-Jones type object detector with high accuracy. Clients can upload their photos to the cloud server to find objects. However, the client does not want the leakage of the content of his/her photos. In the meanwhile, the cloud server is also reluctant to leak any parameters of the trained object detectors. 10 years ago, Avidan & Butman introduced Blind Vision, which is a method for securely evaluating a Viola-Jones type object detector. Blind Vision uses standard cryptographic tools and is painfully slow to compute, taking a couple of hours to scan a single image. The purpose of this work is to explore an efficient method that can speed up the process. We propose the Random Base Image (RBI) Representation. The original image is divided into random base images. Only the base images are submitted randomly to the cloud server. Thus, the content of the image can not be leaked. In the meanwhile, a random vector and the secure Millionaire protocol are leveraged to protect the parameters of the trained object detector. The RBI makes the integral-image enable again for the great acceleration. The experimental results reveal that our method can retain the detection accuracy of that of the plain vision algorithm and is significantly faster than the traditional blind vision, with only a very low probability of the information leakage theoretically.