 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoLugano: A Deep Learning Framework for Fully Automated Lymphoma Segmentation and Lugano Staging on FDG-PET/CT
Dec 08, 2025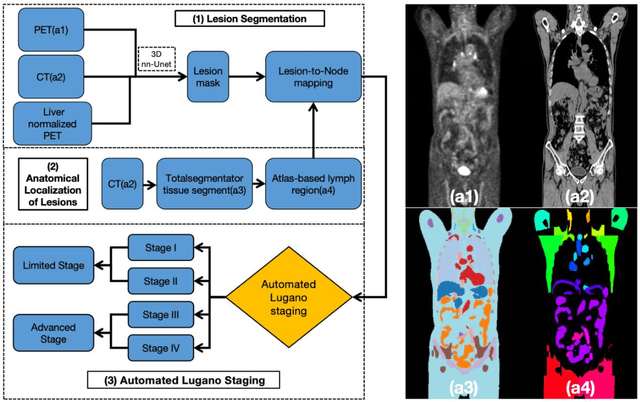
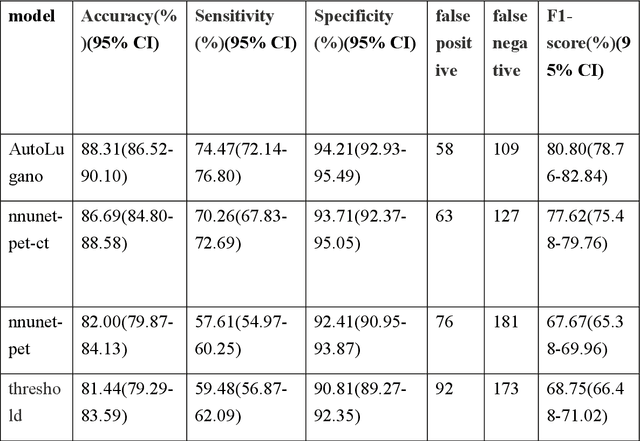
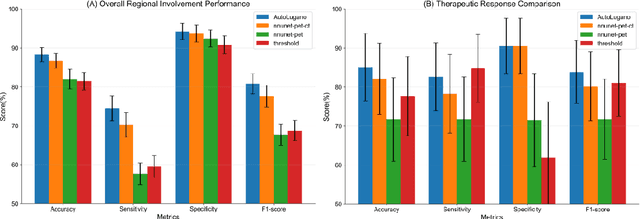
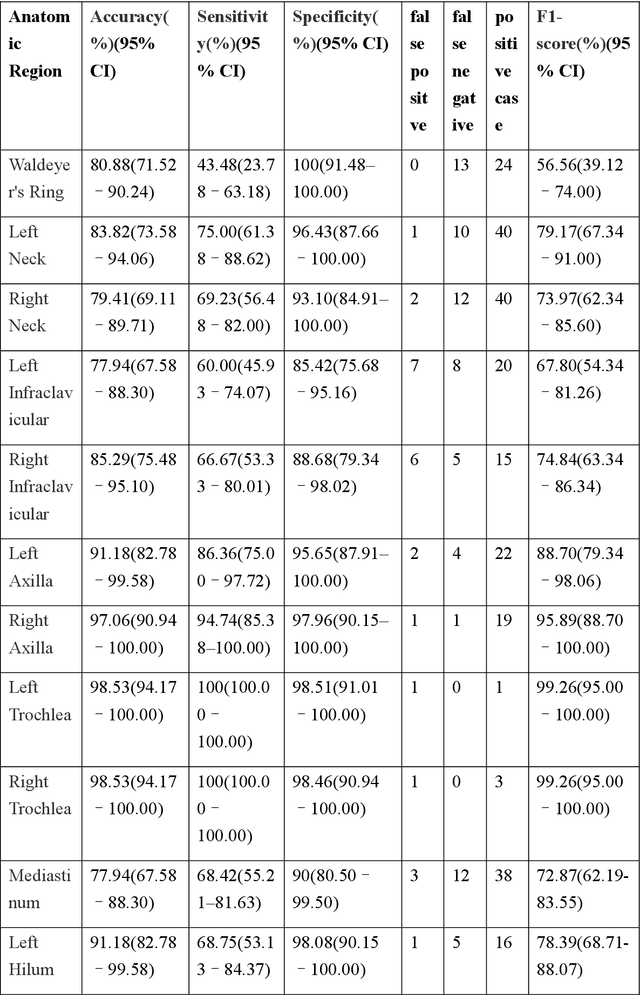
Purpose: To develop a fully automated deep learning system, AutoLugano, for end-to-end lymphoma classification by performing lesion segmentation, anatomical localization, and automated Lugano staging from baseline FDG-PET/CT scans. Methods: The AutoLugano system processes baseline FDG-PET/CT scans through three sequential modules:(1) Anatomy-Informed Lesion Segmentation, a 3D nnU-Net model, trained on multi-channel inputs, performs automated lesion detection (2) Atlas-based Anatomical Localization, which leverages the TotalSegmentator toolkit to map segmented lesions to 21 predefined lymph node regions using deterministic anatomical rules; and (3) Automated Lugano Staging, where the spatial distribution of involved regions is translated into Lugano stages and therapeutic groups (Limited vs. Advanced Stage).The system was trained on the public autoPET dataset (n=1,007) and externally validated on an independent cohort of 67 patients. Performance was assessed using accuracy, sensitivity, specificity, F1-scorefor regional involvement detection and staging agreement. Results: On the external validation set, the proposed model demonstrated robust performance, achieving an overall accuracy of 88.31%, sensitivity of 74.47%, Specificity of 94.21% and an F1-score of 80.80% for regional involvement detection,outperforming baseline models. Most notably, for the critical clinical task of therapeutic stratification (Limited vs. Advanced Stage), the system achieved a high accuracy of 85.07%, with a specificity of 90.48% and a sensitivity of 82.61%.Conclusion: AutoLugano represents the first fully automated, end-to-end pipeline that translates a single baseline FDG-PET/CT scan into a complete Lugano stage. This study demonstrates its strong potential to assist in initial staging, treatment stratification, and supporting clinical decision-making.
Inverting estimating equations for causal inference on quantiles
Jan 02, 2024The causal inference literature frequently focuses on estimating the mean of the potential outcome, whereas the quantiles of the potential outcome may carry important additional information. We propose a universal approach, based on the inverse estimating equations, to generalize a wide class of causal inference solutions from estimating the mean of the potential outcome to its quantiles. We assume that an identifying moment function is available to identify the mean of the threshold-transformed potential outcome, based on which a convenient construction of the estimating equation of quantiles of potential outcome is proposed. In addition, we also give a general construction of the efficient influence functions of the mean and quantiles of potential outcomes, and identify their connection. We motivate estimators for the quantile estimands with the efficient influence function, and develop their asymptotic properties when either parametric models or data-adaptive machine learners are used to estimate the nuisance functions. A broad implication of our results is that one can rework the existing result for mean causal estimands to facilitate causal inference on quantiles, rather than starting from scratch. Our results are illustrated by several examples.
Identification and multiply robust estimation in causal mediation analysis with treatment noncompliance
Apr 20, 2023In experimental and observational studies, there is often interest in understanding the potential mechanism by which an intervention program improves the final outcome. Causal mediation analyses have been developed for this purpose but are primarily restricted to the case of perfect treatment compliance, with a few exceptions that require exclusion restriction. In this article, we establish a semiparametric framework for assessing causal mediation in the presence of treatment noncompliance without exclusion restriction. We propose a set of assumptions to identify the natural mediation effects for the entire study population and further, for the principal natural mediation effects within subpopulations characterized by the potential compliance behaviour. We derive the efficient influence functions for the principal natural mediation effect estimands, which motivate a set of multiply robust estimators for inference. The semiparametric efficiency theory for the identified estimands is derived, based on which a multiply robust estimator is proposed. The multiply robust estimators remain consistent to the their respective estimands under four types of misspecification of the working models and is quadruply robust. We further describe a nonparametric extension of the proposed estimators by incorporating machine learners to estimate the nuisance parameters. A sensitivity analysis framework has been developed for address key identification assumptions-principal ignorability and ignorability of mediator. We demonstrate the proposed methods via simulations and applications to a real data example.
T-Cell Receptor Optimization with Reinforcement Learning and Mutation Policies for Precesion Immunotherapy
Mar 02, 2023T cells monitor the health status of cells by identifying foreign peptides displayed on their surface. T-cell receptors (TCRs), which are protein complexes found on the surface of T cells, are able to bind to these peptides. This process is known as TCR recognition and constitutes a key step for immune response. Optimizing TCR sequences for TCR recognition represents a fundamental step towards the development of personalized treatments to trigger immune responses killing cancerous or virus-infected cells. In this paper, we formulated the search for these optimized TCRs as a reinforcement learning (RL) problem, and presented a framework TCRPPO with a mutation policy using proximal policy optimization. TCRPPO mutates TCRs into effective ones that can recognize given peptides. TCRPPO leverages a reward function that combines the likelihoods of mutated sequences being valid TCRs measured by a new scoring function based on deep autoencoders, with the probabilities of mutated sequences recognizing peptides from a peptide-TCR interaction predictor. We compared TCRPPO with multiple baseline methods and demonstrated that TCRPPO significantly outperforms all the baseline methods to generate positive binding and valid TCRs. These results demonstrate the potential of TCRPPO for both precision immunotherapy and peptide-recognizing TCR motif discovery.