 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICGNN: Graph Neural Network Enabled Scalable Beamforming for MISO Interference Channels
Feb 06, 2025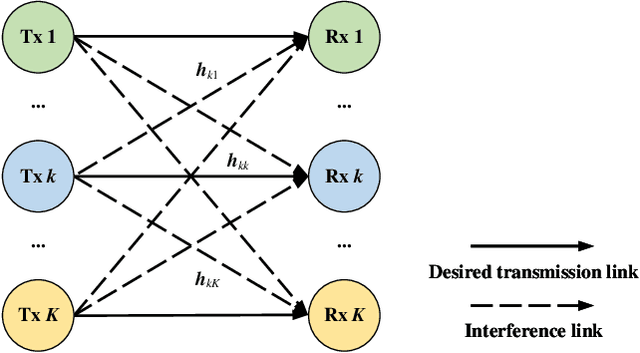
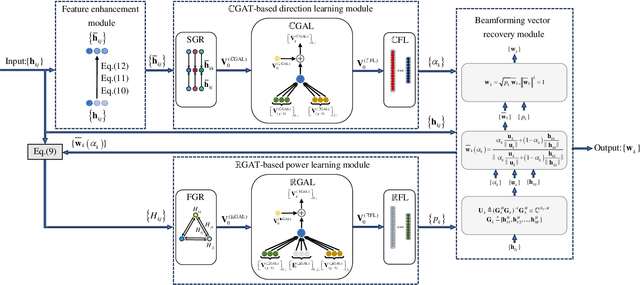
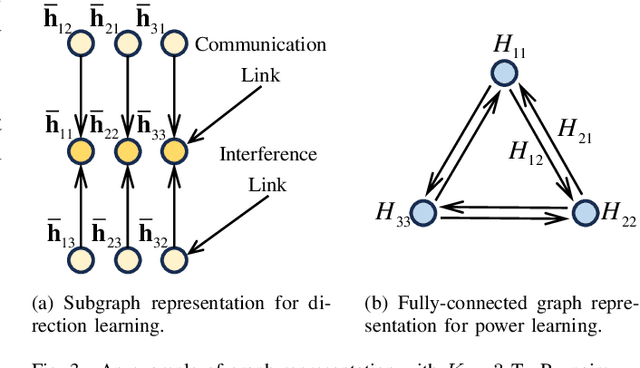
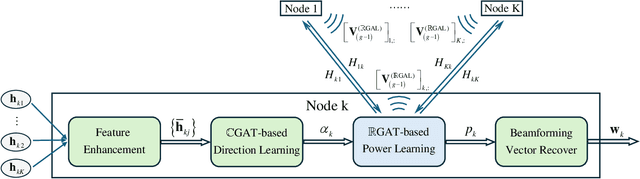
This paper investigates the graph neural network (GNN)-enabled beamforming design for interference channels. We propose a model termed interference channel GNN (ICGNN) to solve a quality-of-service constrained energy efficiency maximization problem. The ICGNN is two-stage, where the direction and power parts of beamforming vectors are learned separately but trained jointly via unsupervised learning. By formulating the dimensionality of features independent of the transceiver pairs, the ICGNN is scalable with the number of transceiver pairs. Besides, to improve the performance of the ICGNN, the hybrid maximum ratio transmission and zero-forcing scheme reduces the output ports, the feature enhancement module unifies the two types of links into one type, the subgraph representation enhances the message passing efficiency, and the multi-head attention and residual connection facilitate the feature extracting. Furthermore, we present the over-the-air distributed implementation of the ICGNN. Ablation studies validate the effectiveness of key components in the ICGNN. Numerical results also demonstrate the capability of ICGNN in achieving near-optimal performance with an average inference time less than 0.1 ms. The scalability of ICGNN for unseen problem sizes is evaluated and enhanced by transfer learning with limited fine-tuning cost. The results of the centralized and distributed implementations of ICGNN are illustrated.
Graph Neural Network Enabled Fluid Antenna Systems: A Two-Stage Approach
Feb 06, 2025



An emerging fluid antenna system (FAS) brings a new dimension, i.e., the antenna positions, to deal with the deep fading, but simultaneously introduces challenges related to the transmit design. This paper proposes an ``unsupervised learning to optimize" paradigm to optimize the FAS. Particularly, we formulate the sum-rate and energy efficiency (EE) maximization problems for a multiple-user multiple-input single-output (MU-MISO) FAS and solved by a two-stage graph neural network (GNN) where the first stage and the second stage are for the inference of antenna positions and beamforming vectors, respectively. The outputs of the two stages are jointly input into a unsupervised loss function to train the two-stage GNN. The numerical results demonstrates that the advantages of the FAS for performance improvement and the two-stage GNN for real-time and scalable optimization. Besides, the two stages can function separately.