 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Far and Near: Perceptual Evaluation of Crowd Representations Across Levels of Detail
Oct 23, 2025In this paper, we investigate how users perceive the visual quality of crowd character representations at different levels of detail (LoD) and viewing distances. Each representation: geometric meshes, image-based impostors, Neural Radiance Fields (NeRFs), and 3D Gaussians, exhibits distinct trade-offs between visual fidelity and computational performance. Our qualitative and quantitative results provide insights to guide the design of perceptually optimized LoD strategies for crowd rendering.
CrowdSplat: Exploring Gaussian Splatting For Crowd Rendering
Jan 29, 2025We present CrowdSplat, a novel approach that leverages 3D Gaussian Splatting for real-time, high-quality crowd rendering. Our method utilizes 3D Gaussian functions to represent animated human characters in diverse poses and outfits, which are extracted from monocular videos. We integrate Level of Detail (LoD) rendering to optimize computational efficiency and quality. The CrowdSplat framework consists of two stages: (1) avatar reconstruction and (2) crowd synthesis. The framework is also optimized for GPU memory usage to enhance scalability. Quantitative and qualitative evaluations show that CrowdSplat achieves good levels of rendering quality, memory efficiency, and computational performance. Through these experiments, we demonstrate that CrowdSplat is a viable solution for dynamic, realistic crowd simulation in real-time applications.
Evaluating CrowdSplat: Perceived Level of Detail for Gaussian Crowds
Jan 28, 2025Efficient and realistic crowd rendering is an important element of many real-time graphics applications such as Virtual Reality (VR) and games. To this end, Levels of Detail (LOD) avatar representations such as polygonal meshes, image-based impostors, and point clouds have been proposed and evaluated. More recently, 3D Gaussian Splatting has been explored as a potential method for real-time crowd rendering. In this paper, we present a two-alternative forced choice (2AFC) experiment that aims to determine the perceived quality of 3D Gaussian avatars. Three factors were explored: Motion, LOD (i.e., #Gaussians), and the avatar height in Pixels (corresponding to the viewing distance). Participants viewed pairs of animated 3D Gaussian avatars and were tasked with choosing the most detailed one. Our findings can inform the optimization of LOD strategies in Gaussian-based crowd rendering, thereby helping to achieve efficient rendering while maintaining visual quality in real-time applications.
Environment-Specific People
Dec 22, 2023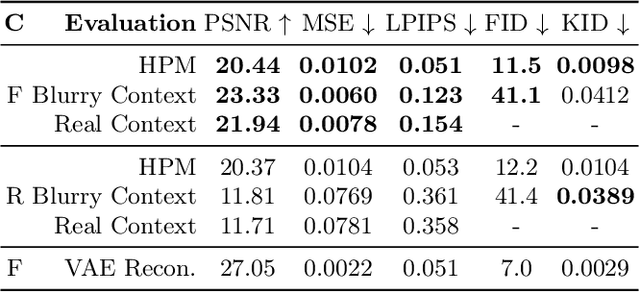
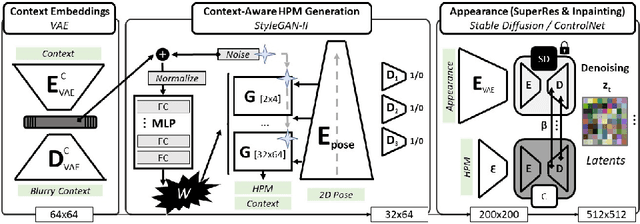

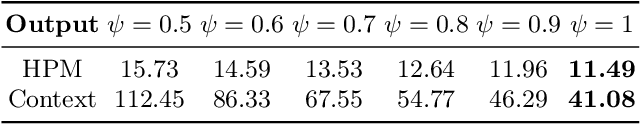
Despite significant progress in generative image synthesis and full-body generation in particular, state-of-the-art methods are either context-independent, overly reliant to text prompts, or bound to the curated training datasets, such as fashion images with monotonous backgrounds. Here, our goal is to generate people in clothing that is semantically appropriate for a given scene. To this end, we present ESP, a novel method for context-aware full-body generation, that enables photo-realistic inpainting of people into existing "in-the-wild" photographs. ESP is conditioned on a 2D pose and contextual cues that are extracted from the environment photograph and integrated into the generation process. Our models are trained on a dataset containing a set of in-the-wild photographs of people covering a wide range of different environments. The method is analyzed quantitatively and qualitatively, and we show that ESP outperforms state-of-the-art on the task of contextual full-body generation.
Globally Continuous and Non-Markovian Activity Analysis from Videos
Oct 11, 2018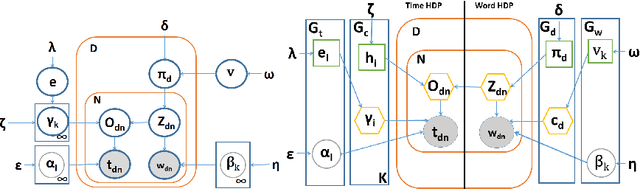
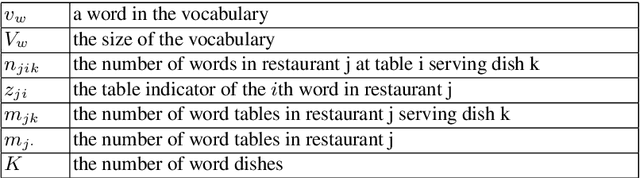

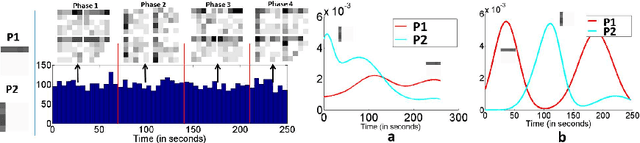
Automatically recognizing activities in video is a classic problem in vision and helps to understand behaviors, describe scenes and detect anomalies. We propose an unsupervised method for such purposes. Given video data, we discover recurring activity patterns that appear, peak, wane and disappear over time. By using non-parametric Bayesian methods, we learn coupled spatial and temporal patterns with minimum prior knowledge. To model the temporal changes of patterns, previous works compute Markovian progressions or locally continuous motifs whereas we model time in a globally continuous and non-Markovian way. Visually, the patterns depict flows of major activities. Temporally, each pattern has its own unique appearance-disappearance cycles. To compute compact pattern representations, we also propose a hybrid sampling method. By combining these patterns with detailed environment information, we interpret the semantics of activities and report anomalies. Also, our method fits data better and detects anomalies that were difficult to detect previously.
* Preprint of our ECCV 2016 spotlight paper