 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Textual and Tabular Worlds for Fact Verification: A Lightweight, Attention-Based Model
Mar 26, 2024FEVEROUS is a benchmark and research initiative focused on fact extraction and verification tasks involving unstructured text and structured tabular data. In FEVEROUS, existing works often rely on extensive preprocessing and utilize rule-based transformations of data, leading to potential context loss or misleading encodings. This paper introduces a simple yet powerful model that nullifies the need for modality conversion, thereby preserving the original evidence's context. By leveraging pre-trained models on diverse text and tabular datasets and by incorporating a lightweight attention-based mechanism, our approach efficiently exploits latent connections between different data types, thereby yielding comprehensive and reliable verdict predictions. The model's modular structure adeptly manages multi-modal information, ensuring the integrity and authenticity of the original evidence are uncompromised. Comparative analyses reveal that our approach exhibits competitive performance, aligning itself closely with top-tier models on the FEVEROUS benchmark.
XFEVER: Exploring Fact Verification across Languages
Oct 25, 2023This paper introduces the Cross-lingual Fact Extraction and VERification (XFEVER) dataset designed for benchmarking the fact verification models across different languages. We constructed it by translating the claim and evidence texts of the Fact Extraction and VERification (FEVER) dataset into six languages. The training and development sets were translated using machine translation, whereas the test set includes texts translated by professional translators and machine-translated texts. Using the XFEVER dataset, two cross-lingual fact verification scenarios, zero-shot learning and translate-train learning, are defined, and baseline models for each scenario are also proposed in this paper. Experimental results show that the multilingual language model can be used to build fact verification models in different languages efficiently. However, the performance varies by language and is somewhat inferior to the English case. We also found that we can effectively mitigate model miscalibration by considering the prediction similarity between the English and target languages. The XFEVER dataset, code, and model checkpoints are available at https://github.com/nii-yamagishilab/xfever.
Outlier-Aware Training for Improving Group Accuracy Disparities
Oct 27, 2022Methods addressing spurious correlations such as Just Train Twice (JTT, arXiv:2107.09044v2) involve reweighting a subset of the training set to maximize the worst-group accuracy. However, the reweighted set of examples may potentially contain unlearnable examples that hamper the model's learning. We propose mitigating this by detecting outliers to the training set and removing them before reweighting. Our experiments show that our method achieves competitive or better accuracy compared with JTT and can detect and remove annotation errors in the subset being reweighted in JTT.
A Multi-Level Attention Model for Evidence-Based Fact Checking
Jun 02, 2021

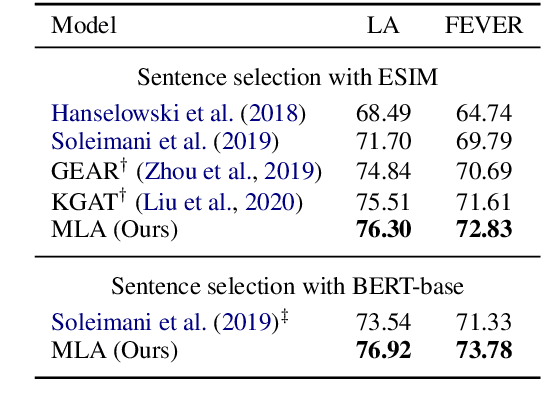
Evidence-based fact checking aims to verify the truthfulness of a claim against evidence extracted from textual sources. Learning a representation that effectively captures relations between a claim and evidence can be challenging. Recent state-of-the-art approaches have developed increasingly sophisticated models based on graph structures. We present a simple model that can be trained on sequence structures. Our model enables inter-sentence attentions at different levels and can benefit from joint training. Results on a large-scale dataset for Fact Extraction and VERification (FEVER) show that our model outperforms the graph-based approaches and yields 1.09% and 1.42% improvements in label accuracy and FEVER score, respectively, over the best published model.
DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Nov 03, 2020

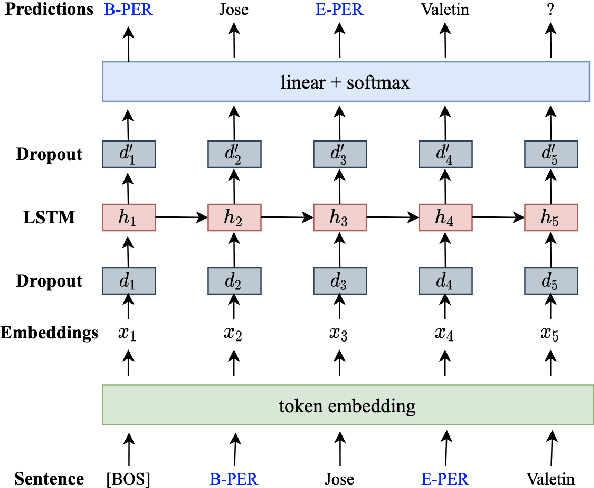
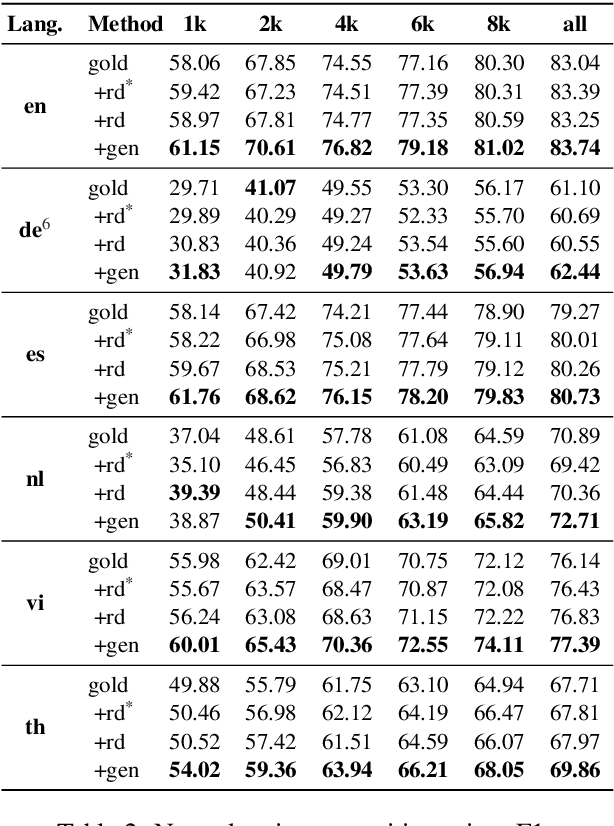
Data augmentation techniques have been widely used to improve machine learning performance as they enhance the generalization capability of models. In this work, to generate high quality synthetic data for low-resource tagging tasks, we propose a novel augmentation method with language models trained on the linearized labeled sentences. Our method is applicable to both supervised and semi-supervised settings. For the supervised settings, we conduct extensive experiments on named entity recognition (NER), part of speech (POS) tagging and end-to-end target based sentiment analysis (E2E-TBSA) tasks. For the semi-supervised settings, we evaluate our method on the NER task under the conditions of given unlabeled data only and unlabeled data plus a knowledge base. The results show that our method can consistently outperform the baselines, particularly when the given gold training data are less.