 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-Sense Cross-Lingual Alignment of Contextual Embeddings
Mar 11, 2021
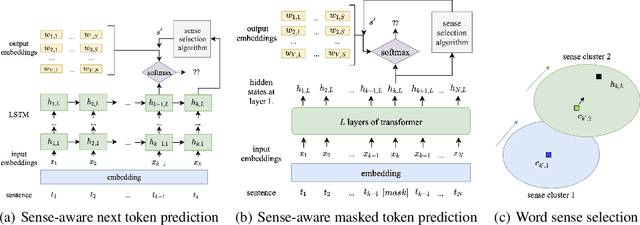
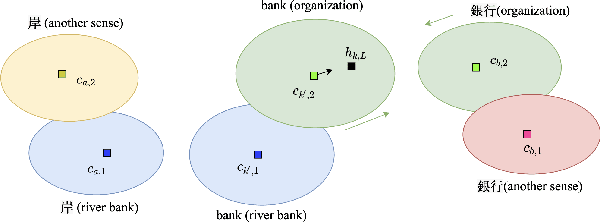
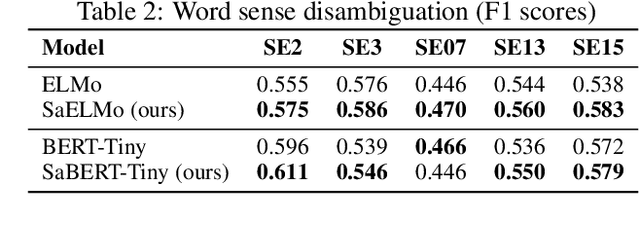
Cross-lingual word embeddings (CLWE) have been proven useful in many cross-lingual tasks. However, most existing approaches to learn CLWE including the ones with contextual embeddings are sense agnostic. In this work, we propose a novel framework to align contextual embeddings at the sense level by leveraging cross-lingual signal from bilingual dictionaries only. We operationalize our framework by first proposing a novel sense-aware cross entropy loss to model word senses explicitly. The monolingual ELMo and BERT models pretrained with our sense-aware cross entropy loss demonstrate significant performance improvement for word sense disambiguation tasks. We then propose a sense alignment objective on top of the sense-aware cross entropy loss for cross-lingual model pretraining, and pretrain cross-lingual models for several language pairs (English to German/Spanish/Japanese/Chinese). Compared with the best baseline results, our cross-lingual models achieve 0.52%, 2.09% and 1.29% average performance improvements on zero-shot cross-lingual NER, sentiment classification and XNLI tasks, respectively.
DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Nov 03, 2020

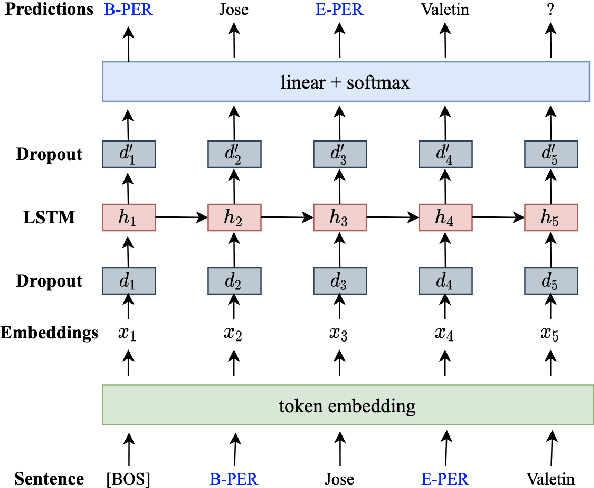
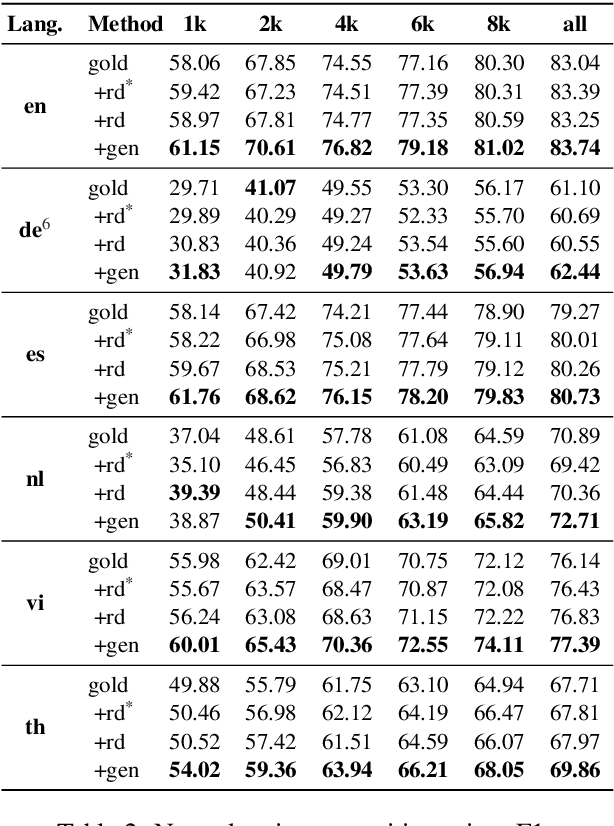
Data augmentation techniques have been widely used to improve machine learning performance as they enhance the generalization capability of models. In this work, to generate high quality synthetic data for low-resource tagging tasks, we propose a novel augmentation method with language models trained on the linearized labeled sentences. Our method is applicable to both supervised and semi-supervised settings. For the supervised settings, we conduct extensive experiments on named entity recognition (NER), part of speech (POS) tagging and end-to-end target based sentiment analysis (E2E-TBSA) tasks. For the semi-supervised settings, we evaluate our method on the NER task under the conditions of given unlabeled data only and unlabeled data plus a knowledge base. The results show that our method can consistently outperform the baselines, particularly when the given gold training data are less.