 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4-DoF Tracking for Robot Fine Manipulation Tasks
Apr 04, 2017

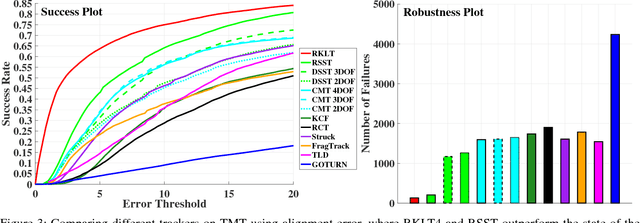

This paper presents two visual trackers from the different paradigms of learning and registration based tracking and evaluates their application in image based visual servoing. They can track object motion with four degrees of freedom (DoF) which, as we will show here, is sufficient for many fine manipulation tasks. One of these trackers is a newly developed learning based tracker that relies on learning discriminative correlation filters while the other is a refinement of a recent 8 DoF RANSAC based tracker adapted with a new appearance model for tracking 4 DoF motion. Both trackers are shown to provide superior performance to several state of the art trackers on an existing dataset for manipulation tasks. Further, a new dataset with challenging sequences for fine manipulation tasks captured from robot mounted eye-in-hand (EIH) cameras is also presented. These sequences have a variety of challenges encountered during real tasks including jittery camera movement, motion blur, drastic scale changes and partial occlusions. Quantitative and qualitative results on these sequences are used to show that these two trackers are robust to failures while providing high precision that makes them suitable for such fine manipulation tasks.
Incremental Learning for Robot Perception through HRI
Jan 17, 2017
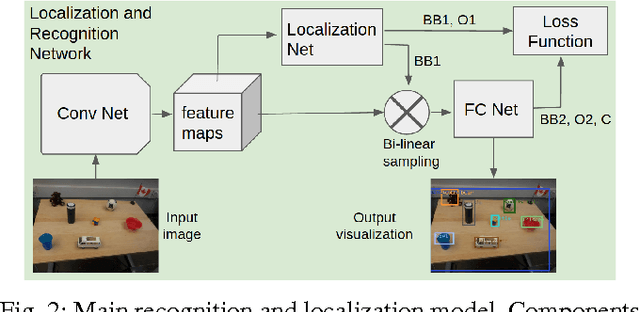

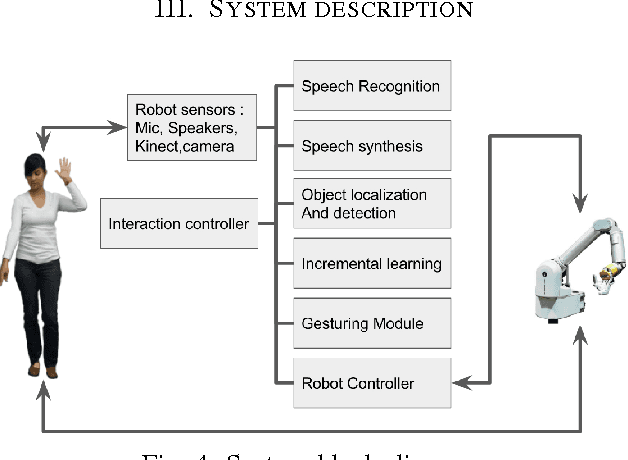
Scene understanding and object recognition is a difficult to achieve yet crucial skill for robots. Recently, Convolutional Neural Networks (CNN), have shown success in this task. However, there is still a gap between their performance on image datasets and real-world robotics scenarios. We present a novel paradigm for incrementally improving a robot's visual perception through active human interaction. In this paradigm, the user introduces novel objects to the robot by means of pointing and voice commands. Given this information, the robot visually explores the object and adds images from it to re-train the perception module. Our base perception module is based on recent development in object detection and recognition using deep learning. Our method leverages state of the art CNNs from off-line batch learning, human guidance, robot exploration and incremental on-line learning.