 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning for Robot Perception through HRI
Paper and Code
Jan 17, 2017
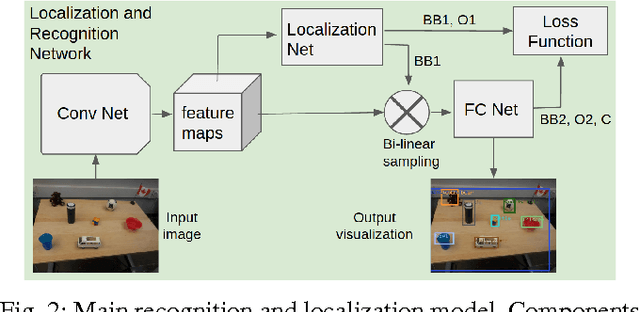

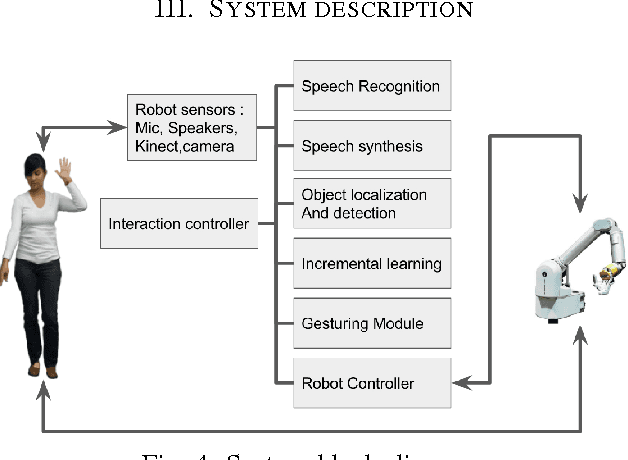
Scene understanding and object recognition is a difficult to achieve yet crucial skill for robots. Recently, Convolutional Neural Networks (CNN), have shown success in this task. However, there is still a gap between their performance on image datasets and real-world robotics scenarios. We present a novel paradigm for incrementally improving a robot's visual perception through active human interaction. In this paradigm, the user introduces novel objects to the robot by means of pointing and voice commands. Given this information, the robot visually explores the object and adds images from it to re-train the perception module. Our base perception module is based on recent development in object detection and recognition using deep learning. Our method leverages state of the art CNNs from off-line batch learning, human guidance, robot exploration and incremental on-line learning.