 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciBERTSUM: Extractive Summarization for Scientific Documents
Jan 21, 2022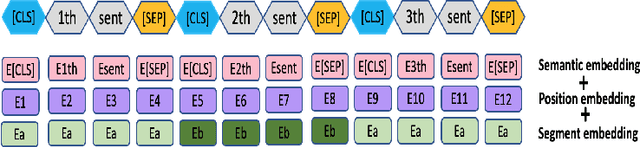
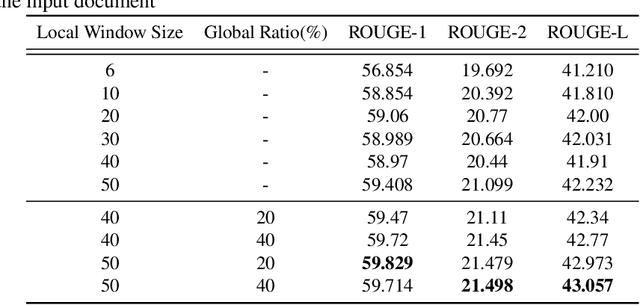
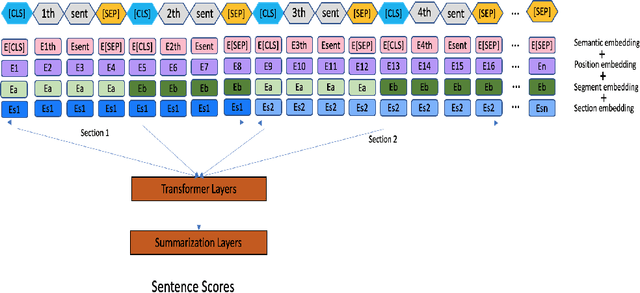

The summarization literature focuses on the summarization of news articles. The news articles in the CNN-DailyMail are relatively short documents with about 30 sentences per document on average. We introduce SciBERTSUM, our summarization framework designed for the summarization of long documents like scientific papers with more than 500 sentences. SciBERTSUM extends BERTSUM to long documents by 1) adding a section embedding layer to include section information in the sentence vector and 2) applying a sparse attention mechanism where each sentences will attend locally to nearby sentences and only a small number of sentences attend globally to all other sentences. We used slides generated by the authors of scientific papers as reference summaries since they contain the technical details from the paper. The results show the superiority of our model in terms of ROUGE scores.
Large Scale Subject Category Classification of Scholarly Papers with Deep Attentive Neural Networks
Jul 27, 2020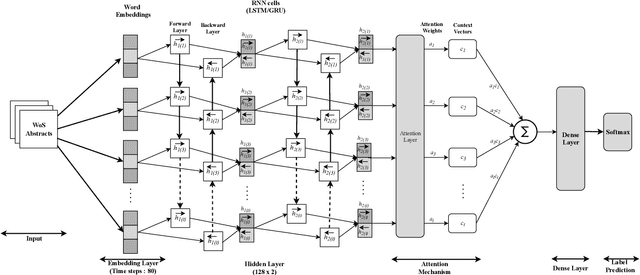
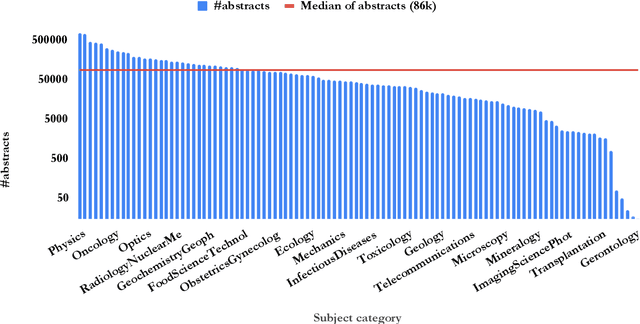
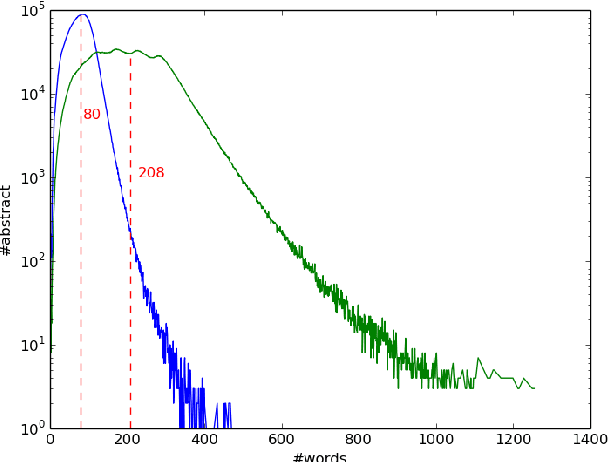
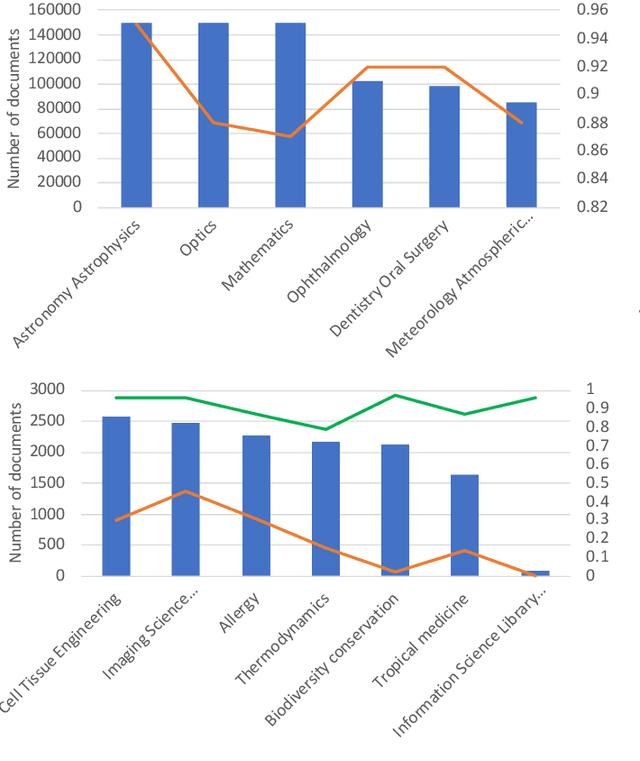
Subject categories of scholarly papers generally refer to the knowledge domain(s) to which the papers belong, examples being computer science or physics. Subject category information can be used for building faceted search for digital library search engines. This can significantly assist users in narrowing down their search space of relevant documents. Unfortunately, many academic papers do not have such information as part of their metadata. Existing methods for solving this task usually focus on unsupervised learning that often relies on citation networks. However, a complete list of papers citing the current paper may not be readily available. In particular, new papers that have few or no citations cannot be classified using such methods. Here, we propose a deep attentive neural network (DANN) that classifies scholarly papers using only their abstracts. The network is trained using 9 million abstracts from Web of Science (WoS). We also use the WoS schema that covers 104 subject categories. The proposed network consists of two bi-directional recurrent neural networks followed by an attention layer. We compare our model against baselines by varying the architecture and text representation. Our best model achieves micro-F1 measure of 0.76 with F1 of individual subject categories ranging from 0.50-0.95. The results showed the importance of retraining word embedding models to maximize the vocabulary overlap and the effectiveness of the attention mechanism. The combination of word vectors with TFIDF outperforms character and sentence level embedding models. We discuss imbalanced samples and overlapping categories and suggest possible strategies for mitigation. We also determine the subject category distribution in CiteSeerX by classifying a random sample of one million academic papers.
Provably Stable Interpretable Encodings of Context Free Grammars in RNNs with a Differentiable Stack
Jun 11, 2020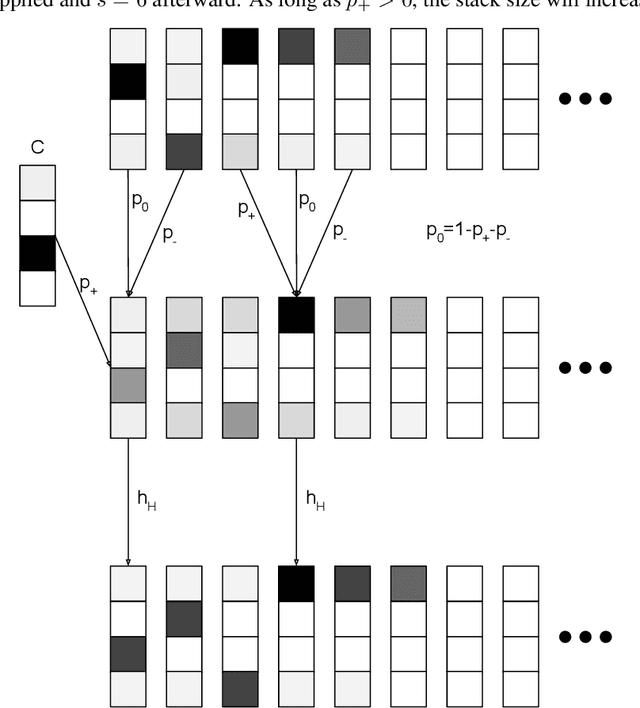
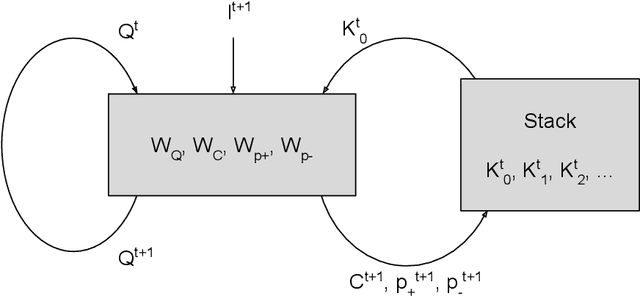
Given a collection of strings belonging to a context free grammar (CFG) and another collection of strings not belonging to the CFG, how might one infer the grammar? This is the problem of grammatical inference. Since CFGs are the languages recognized by pushdown automata (PDA), it suffices to determine the state transition rules and stack action rules of the corresponding PDA. An approach would be to train a recurrent neural network (RNN) to classify the sample data and attempt to extract these PDA rules. But neural networks are not a priori aware of the structure of a PDA and would likely require many samples to infer this structure. Furthermore, extracting the PDA rules from the RNN is nontrivial. We build a RNN specifically structured like a PDA, where weights correspond directly to the PDA rules. This requires a stack architecture that is somehow differentiable (to enable gradient-based learning) and stable (an unstable stack will show deteriorating performance with longer strings). We propose a stack architecture that is differentiable and that provably exhibits orbital stability. Using this stack, we construct a neural network that provably approximates a PDA for strings of arbitrary length. Moreover, our model and method of proof can easily be generalized to other state machines, such as a Turing Machine.