 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Estimation of Heterogeneous Causal Effects
Feb 22, 2022


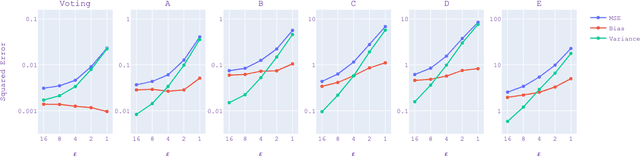
Estimating heterogeneous treatment effects in domains such as healthcare or social science often involves sensitive data where protecting privacy is important. We introduce a general meta-algorithm for estimating conditional average treatment effects (CATE) with differential privacy (DP) guarantees. Our meta-algorithm can work with simple, single-stage CATE estimators such as S-learner and more complex multi-stage estimators such as DR and R-learner. We perform a tight privacy analysis by taking advantage of sample splitting in our meta-algorithm and the parallel composition property of differential privacy. In this paper, we implement our approach using DP-EBMs as the base learner. DP-EBMs are interpretable, high-accuracy models with privacy guarantees, which allow us to directly observe the impact of DP noise on the learned causal model. Our experiments show that multi-stage CATE estimators incur larger accuracy loss than single-stage CATE or ATE estimators and that most of the accuracy loss from differential privacy is due to an increase in variance, not biased estimates of treatment effects.
Matching on What Matters: A Pseudo-Metric Learning Approach to Matching Estimation in High Dimensions
May 28, 2019


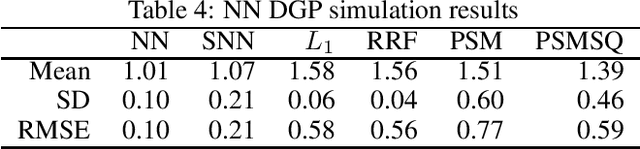
When pre-processing observational data via matching, we seek to approximate each unit with maximally similar peers that had an alternative treatment status--essentially replicating a randomized block design. However, as one considers a growing number of continuous features, a curse of dimensionality applies making asymptotically valid inference impossible (Abadie and Imbens, 2006). The alternative of ignoring plausibly relevant features is certainly no better, and the resulting trade-off substantially limits the application of matching methods to "wide" datasets. Instead, Li and Fu (2017) recasts the problem of matching in a metric learning framework that maps features to a low-dimensional space that facilitates "closer matches" while still capturing important aspects of unit-level heterogeneity. However, that method lacks key theoretical guarantees and can produce inconsistent estimates in cases of heterogeneous treatment effects. Motivated by straightforward extension of existing results in the matching literature, we present alternative techniques that learn latent matching features through either MLPs or through siamese neural networks trained on a carefully selected loss function. We benchmark the resulting alternative methods in simulations as well as against two experimental data sets--including the canonical NSW worker training program data set--and find superior performance of the neural-net-based methods.
Pricing Engine: Estimating Causal Impacts in Real World Business Settings
Jun 12, 2018
We introduce the Pricing Engine package to enable the use of Double ML estimation techniques in general panel data settings. Customization allows the user to specify first-stage models, first-stage featurization, second stage treatment selection and second stage causal-modeling. We also introduce a DynamicDML class that allows the user to generate dynamic treatment-aware forecasts at a range of leads and to understand how the forecasts will vary as a function of causally estimated treatment parameters. The Pricing Engine is built on Python 3.5 and can be run on an Azure ML Workbench environment with the addition of only a few Python packages. This note provides high-level discussion of the Double ML method, describes the packages intended use and includes an example Jupyter notebook demonstrating application to some publicly available data. Installation of the package and additional technical documentation is available at $\href{https://github.com/bquistorff/pricingengine}{github.com/bquistorff/pricingengine}$.