 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching on What Matters: A Pseudo-Metric Learning Approach to Matching Estimation in High Dimensions
May 28, 2019


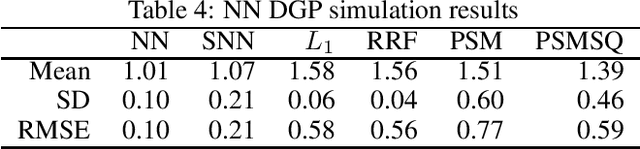
When pre-processing observational data via matching, we seek to approximate each unit with maximally similar peers that had an alternative treatment status--essentially replicating a randomized block design. However, as one considers a growing number of continuous features, a curse of dimensionality applies making asymptotically valid inference impossible (Abadie and Imbens, 2006). The alternative of ignoring plausibly relevant features is certainly no better, and the resulting trade-off substantially limits the application of matching methods to "wide" datasets. Instead, Li and Fu (2017) recasts the problem of matching in a metric learning framework that maps features to a low-dimensional space that facilitates "closer matches" while still capturing important aspects of unit-level heterogeneity. However, that method lacks key theoretical guarantees and can produce inconsistent estimates in cases of heterogeneous treatment effects. Motivated by straightforward extension of existing results in the matching literature, we present alternative techniques that learn latent matching features through either MLPs or through siamese neural networks trained on a carefully selected loss function. We benchmark the resulting alternative methods in simulations as well as against two experimental data sets--including the canonical NSW worker training program data set--and find superior performance of the neural-net-based methods.