 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForming Local Intersections of Projections for Classifying and Searching Histopathology Images
Aug 08, 2020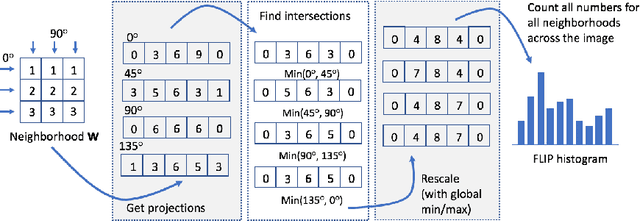
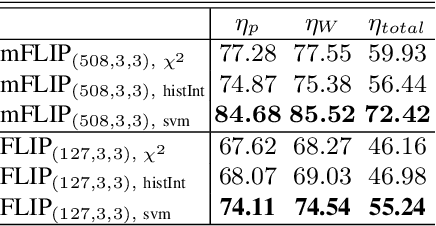


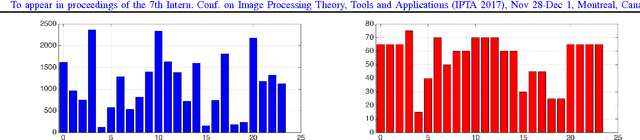
In this paper, we propose a novel image descriptor called Forming Local Intersections of Projections (FLIP) and its multi-resolution version (mFLIP) for representing histopathology images. The descriptor is based on the Radon transform wherein we apply parallel projections in small local neighborhoods of gray-level images. Using equidistant projection directions in each window, we extract unique and invariant characteristics of the neighborhood by taking the intersection of adjacent projections. Thereafter, we construct a histogram for each image, which we call the FLIP histogram. Various resolutions provide different FLIP histograms which are then concatenated to form the mFLIP descriptor. Our experiments included training common networks from scratch and fine-tuning pre-trained networks to benchmark our proposed descriptor. Experiments are conducted on the publicly available dataset KIMIA Path24 and KIMIA Path960. For both of these datasets, FLIP and mFLIP descriptors show promising results in all experiments.Using KIMIA Path24 data, FLIP outperformed non-fine-tuned Inception-v3 and fine-tuned VGG16 and mFLIP outperformed fine-tuned Inception-v3 in feature extracting.
Convolutional Neural Networks for Histopathology Image Classification: Training vs. Using Pre-Trained Networks
Oct 11, 2017

We explore the problem of classification within a medical image data-set based on a feature vector extracted from the deepest layer of pre-trained Convolution Neural Networks. We have used feature vectors from several pre-trained structures, including networks with/without transfer learning to evaluate the performance of pre-trained deep features versus CNNs which have been trained by that specific dataset as well as the impact of transfer learning with a small number of samples. All experiments are done on Kimia Path24 dataset which consists of 27,055 histopathology training patches in 24 tissue texture classes along with 1,325 test patches for evaluation. The result shows that pre-trained networks are quite competitive against training from scratch. As well, fine-tuning does not seem to add any tangible improvement for VGG16 to justify additional training while we observed considerable improvement in retrieval and classification accuracy when we fine-tuned the Inception structure.