 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCI: A (G)raph (C)oncept (I)nterpretation Framework
Feb 09, 2023



Explainable AI (XAI) underwent a recent surge in research on concept extraction, focusing on extracting human-interpretable concepts from Deep Neural Networks. An important challenge facing concept extraction approaches is the difficulty of interpreting and evaluating discovered concepts, especially for complex tasks such as molecular property prediction. We address this challenge by presenting GCI: a (G)raph (C)oncept (I)nterpretation framework, used for quantitatively measuring alignment between concepts discovered from Graph Neural Networks (GNNs) and their corresponding human interpretations. GCI encodes concept interpretations as functions, which can be used to quantitatively measure the alignment between a given interpretation and concept definition. We demonstrate four applications of GCI: (i) quantitatively evaluating concept extractors, (ii) measuring alignment between concept extractors and human interpretations, (iii) measuring the completeness of interpretations with respect to an end task and (iv) a practical application of GCI to molecular property prediction, in which we demonstrate how to use chemical functional groups to explain GNNs trained on molecular property prediction tasks, and implement interpretations with a 0.76 AUCROC completeness score.
Explainer Divergence Scores (EDS): Some Post-Hoc Explanations May be Effective for Detecting Unknown Spurious Correlations
Nov 14, 2022Recent work has suggested post-hoc explainers might be ineffective for detecting spurious correlations in Deep Neural Networks (DNNs). However, we show there are serious weaknesses with the existing evaluation frameworks for this setting. Previously proposed metrics are extremely difficult to interpret and are not directly comparable between explainer methods. To alleviate these constraints, we propose a new evaluation methodology, Explainer Divergence Scores (EDS), grounded in an information theory approach to evaluate explainers. EDS is easy to interpret and naturally comparable across explainers. We use our methodology to compare the detection performance of three different explainers - feature attribution methods, influential examples and concept extraction, on two different image datasets. We discover post-hoc explainers often contain substantial information about a DNN's dependence on spurious artifacts, but in ways often imperceptible to human users. This suggests the need for new techniques that can use this information to better detect a DNN's reliance on spurious correlations.
Failing Conceptually: Concept-Based Explanations of Dataset Shift
May 01, 2021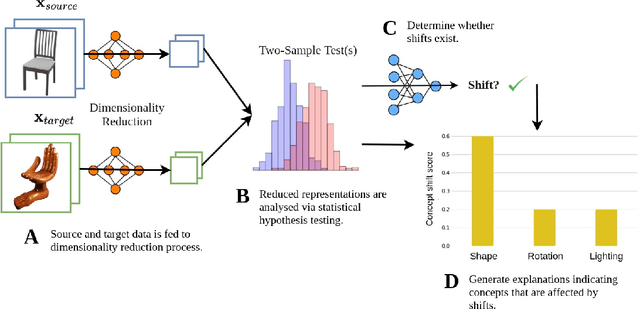

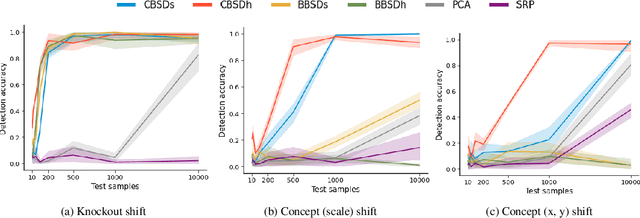

Despite their remarkable performance on a wide range of visual tasks, machine learning technologies often succumb to data distribution shifts. Consequently, a range of recent work explores techniques for detecting these shifts. Unfortunately, current techniques offer no explanations about what triggers the detection of shifts, thus limiting their utility to provide actionable insights. In this work, we present Concept Bottleneck Shift Detection (CBSD): a novel explainable shift detection method. CBSD provides explanations by identifying and ranking the degree to which high-level human-understandable concepts are affected by shifts. Using two case studies (dSprites and 3dshapes), we demonstrate how CBSD can accurately detect underlying concepts that are affected by shifts and achieve higher detection accuracy compared to state-of-the-art shift detection methods.
Is Disentanglement all you need? Comparing Concept-based & Disentanglement Approaches
Apr 14, 2021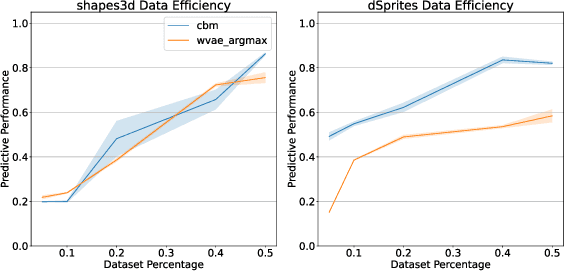



Concept-based explanations have emerged as a popular way of extracting human-interpretable representations from deep discriminative models. At the same time, the disentanglement learning literature has focused on extracting similar representations in an unsupervised or weakly-supervised way, using deep generative models. Despite the overlapping goals and potential synergies, to our knowledge, there has not yet been a systematic comparison of the limitations and trade-offs between concept-based explanations and disentanglement approaches. In this paper, we give an overview of these fields, comparing and contrasting their properties and behaviours on a diverse set of tasks, and highlighting their potential strengths and limitations. In particular, we demonstrate that state-of-the-art approaches from both classes can be data inefficient, sensitive to the specific nature of the classification/regression task, or sensitive to the employed concept representation.
MEME: Generating RNN Model Explanations via Model Extraction
Dec 13, 2020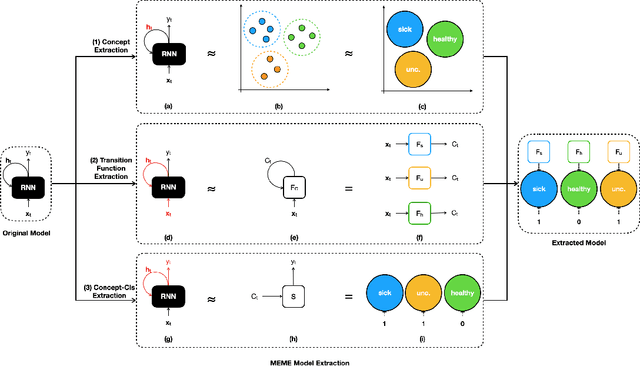
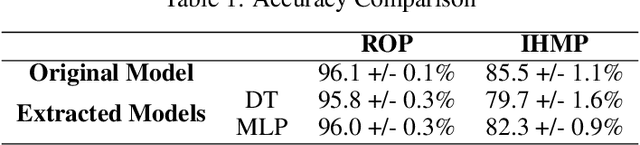
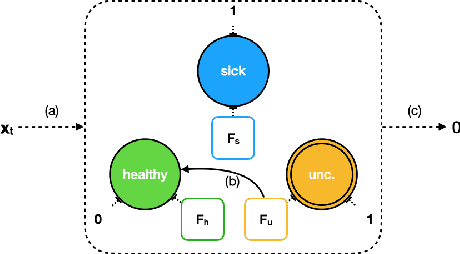
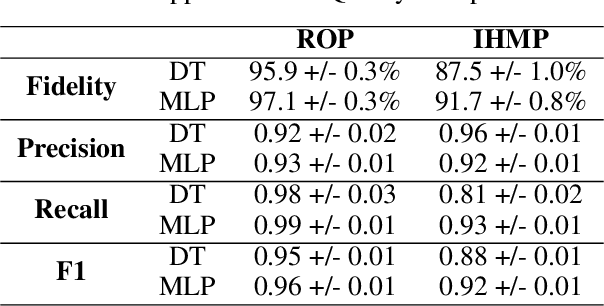
Recurrent Neural Networks (RNNs) have achieved remarkable performance on a range of tasks. A key step to further empowering RNN-based approaches is improving their explainability and interpretability. In this work we present MEME: a model extraction approach capable of approximating RNNs with interpretable models represented by human-understandable concepts and their interactions. We demonstrate how MEME can be applied to two multivariate, continuous data case studies: Room Occupation Prediction, and In-Hospital Mortality Prediction. Using these case-studies, we show how our extracted models can be used to interpret RNNs both locally and globally, by approximating RNN decision-making via interpretable concept interactions.
Now You See Me : Concept-based Model Extraction
Oct 25, 2020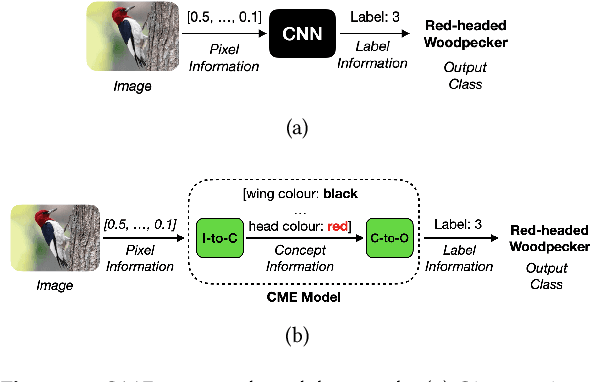
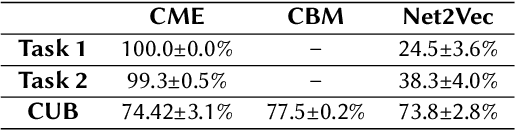
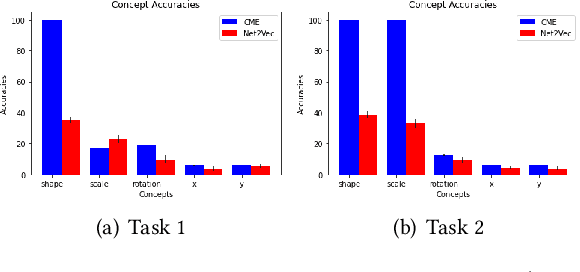
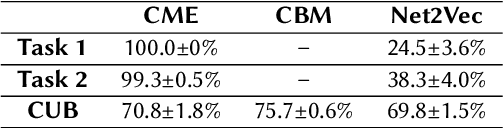
Deep Neural Networks (DNNs) have achieved remarkable performance on a range of tasks. A key step to further empowering DNN-based approaches is improving their explainability. In this work we present CME: a concept-based model extraction framework, used for analysing DNN models via concept-based extracted models. Using two case studies (dSprites, and Caltech UCSD Birds), we demonstrate how CME can be used to (i) analyse the concept information learned by a DNN model (ii) analyse how a DNN uses this concept information when predicting output labels (iii) identify key concept information that can further improve DNN predictive performance (for one of the case studies, we showed how model accuracy can be improved by over 14%, using only 30% of the available concepts).