 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiability of deep generative models under mixture priors without auxiliary information
Jun 20, 2022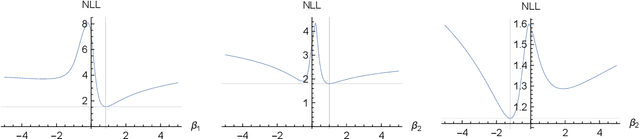


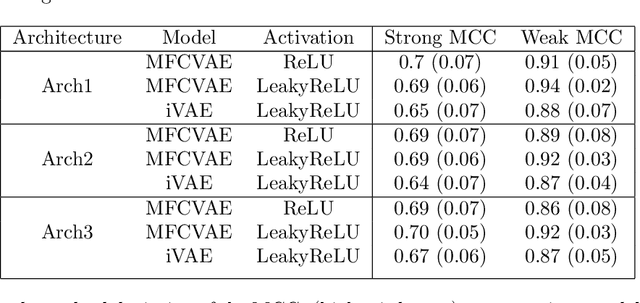
We prove identifiability of a broad class of deep latent variable models that (a) have universal approximation capabilities and (b) are the decoders of variational autoencoders that are commonly used in practice. Unlike existing work, our analysis does not require weak supervision, auxiliary information, or conditioning in the latent space. Recently, there has been a surge of works studying identifiability of such models. In these works, the main assumption is that along with the data, an auxiliary variable $u$ (also known as side information) is observed as well. At the same time, several works have empirically observed that this doesn't seem to be necessary in practice. In this work, we explain this behavior by showing that for a broad class of generative (i.e. unsupervised) models with universal approximation capabilities, the side information $u$ is not necessary: We prove identifiability of the entire generative model where we do not observe $u$ and only observe the data $x$. The models we consider are tightly connected with autoencoder architectures used in practice that leverage mixture priors in the latent space and ReLU/leaky-ReLU activations in the encoder. Our main result is an identifiability hierarchy that significantly generalizes previous work and exposes how different assumptions lead to different "strengths" of identifiability. For example, our weakest result establishes (unsupervised) identifiability up to an affine transformation, which already improves existing work. It's well known that these models have universal approximation capabilities and moreover, they have been extensively used in practice to learn representations of data.
Structure learning in polynomial time: Greedy algorithms, Bregman information, and exponential families
Oct 28, 2021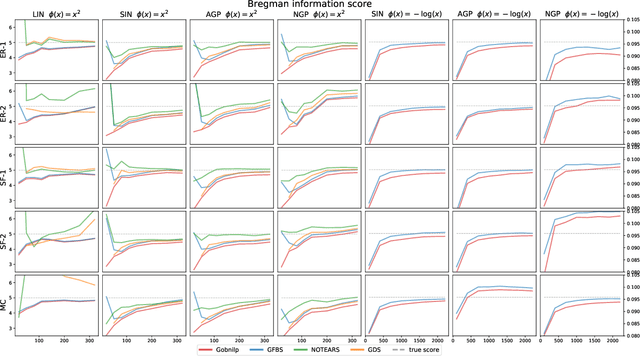



Greedy algorithms have long been a workhorse for learning graphical models, and more broadly for learning statistical models with sparse structure. In the context of learning directed acyclic graphs, greedy algorithms are popular despite their worst-case exponential runtime. In practice, however, they are very efficient. We provide new insight into this phenomenon by studying a general greedy score-based algorithm for learning DAGs. Unlike edge-greedy algorithms such as the popular GES and hill-climbing algorithms, our approach is vertex-greedy and requires at most a polynomial number of score evaluations. We then show how recent polynomial-time algorithms for learning DAG models are a special case of this algorithm, thereby illustrating how these order-based algorithms can be rigourously interpreted as score-based algorithms. This observation suggests new score functions and optimality conditions based on the duality between Bregman divergences and exponential families, which we explore in detail. Explicit sample and computational complexity bounds are derived. Finally, we provide extensive experiments suggesting that this algorithm indeed optimizes the score in a variety of settings.
Learning latent causal graphs via mixture oracles
Jun 29, 2021
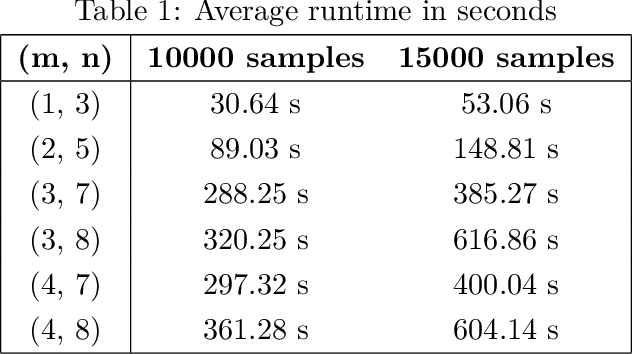

We study the problem of reconstructing a causal graphical model from data in the presence of latent variables. The main problem of interest is recovering the causal structure over the latent variables while allowing for general, potentially nonlinear dependence between the variables. In many practical problems, the dependence between raw observations (e.g. pixels in an image) is much less relevant than the dependence between certain high-level, latent features (e.g. concepts or objects), and this is the setting of interest. We provide conditions under which both the latent representations and the underlying latent causal model are identifiable by a reduction to a mixture oracle. The proof is constructive, and leads to several algorithms for explicitly reconstructing the full graphical model. We discuss efficient algorithms and provide experiments illustrating the algorithms in practice.
Exact nuclear norm, completion and decomposition for random overcomplete tensors via degree-4 SOS
Nov 18, 2020

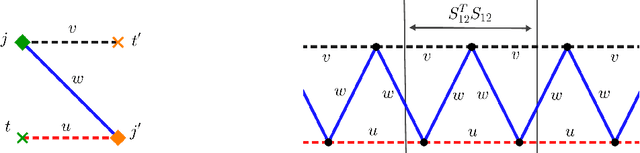
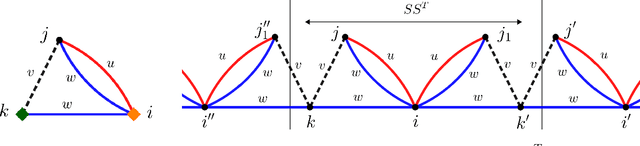
In this paper we show that simple semidefinite programs inspired by degree $4$ SOS can exactly solve the tensor nuclear norm, tensor decomposition, and tensor completion problems on tensors with random asymmetric components. More precisely, for tensor nuclear norm and tensor decomposition, we show that w.h.p. these semidefinite programs can exactly find the nuclear norm and components of an $(n\times n\times n)$-tensor $\mathcal{T}$ with $m\leq n^{3/2}/polylog(n)$ random asymmetric components. For tensor completion, we show that w.h.p. the semidefinite program introduced by Potechin \& Steurer (2017) can exactly recover an $(n\times n\times n)$-tensor $\mathcal{T}$ with $m$ random asymmetric components from only $n^{3/2}m\, polylog(n)$ randomly observed entries. This gives the first theoretical guarantees for exact tensor completion in the overcomplete regime. This matches the best known results for approximate versions of these problems given by Barak \& Moitra (2015) for tensor completion, and Ma, Shi \& Steurer (2016) for tensor decomposition.